
Firebase数据库中的多用户聊天室数据结构

我很难弄清楚如何正确地构造多用户聊天室FirebaseDatabase体系结构。
基本上,该应用程序支持用户之间的私人消息(可以是两个用户之间的消息,也可以是多个用户之间的消息)。如果只在2个用户之间,数据结构真的很容易。
我试图降低成本(我不希望当当前登录的用户正在与某人聊天,而观察者正在获得与该特定聊天无关的所有消息时),并正确地构造数据。如果只有2个用户,我总是可以在当前用户ID下添加受体,并只查询该节点。但是有多个用户(甚至不确定他们中有多少人),我需要依赖聊天室Id,但我很难做到这一点。

共有1个答案

users
uid_0
name: "Bill"
chats:
chat_id_0: true
chat_id_9: true
uid_1
name: "Jesse"
chats:
chat_id_0: true
chat_id_6: true
.
.
.
chats
chat_id_0:
uid_0: "Hey there, Jesse"
uid_1: "Sup Bill?"
chat_id_6:
uid_0: "This is Bill, anyone around?"
chat_id_9:
uid_1: "Look ma, no hands"
uid_7: "Impressive"
显然,更多的细节将包含在每个聊天节点中(时间戳等)
如何根据chatId检查是否已经与相同的接收方(或接收方)进行了聊天
有几种方法可以解决这个问题;
一个是,当一个观察者被添加到每个聊天(.ChildAdded)中时,该聊天节点中的每个子节点都将返回到您的应用程序中。这对两件事有好处--一是用现有的聊天消息填充用户界面,其次...然后你就会知道谁参与了那次聊天。将这些UID与聊天id放在一个数组中,在向该人发送聊天之前,查看它们是否作为现有聊天存在于数组中。
第二个选项是查询用户uid出现的所有聊天内容(使用。ObservesingleEvent进行查询)。这将返回他们所属的所有聊天节点,然后有他们还与谁聊天的UID和聊天ID。
chats
chat_id_0
who_dat
uid_0: true
uid_1: true
uid_2: true
messages:
uid_0: "Hey there, Jesse"
uid_1: "Sup Bill?"
-
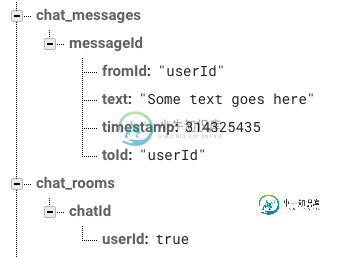
我希望基本上在我的应用程序内翻拍Kik。对于我在firebase聊天应用程序上看到的大多数指南,都有一个主要的消息节点,然后在该节点下面有一个扇出,每个用户都有引用主列表中消息的消息。 根据目前我的Firebase的布局方式,实现类似以下内容会更容易: 因此,当用户向对方发送消息时,我会更新发送者和用户下面的“聊天消息”节点。 有什么理由不这样做吗?我看到每个人都按照我描述的第一种方式进行,但我看
-
我正在开发一个Android聊天应用程序,似乎我需要通过FCM发送每条消息,还需要保存到实时数据库。 我使用Firebase realtime DB存储和发送消息。我仍然需要发送每个消息(或至少消息id)也通过FCM。我担心如果我不这样做,并且只在应用程序在后台时发送FCM,用户可能会错过一些传入的消息。 将侦听器放在服务上似乎不够可靠(如果android干掉了服务怎么办?直到我重新启动它,我可能
-
我正在构建一个使用Firestore存储大多数数据的应用程序。该应用程序具有聊天功能,我正在考虑使用实时数据库。使用Firebase Firestore vs Realtime Database实现此聊天功能有哪些好处?如果没有区别,我应该什么都使用Firestore吗? 附言:我已经阅读了两个https://firebase.google.com/docs/database/rtdb-vs-fi
-
我们正在构建一个聊天应用程序,一对一聊天是该应用程序的主要目的,所以目前,消息传递速度是我们的第一要务。我们需要一个后端解决方案,我们最初计划使用Firebase实时数据库。但后来Firestore出现了,从那以后,我们看到了Firebase团队对实时数据库Firestore的许多建议。 我们已经使用了实时数据库和Firestore,所以我们非常了解两者的功能和查询能力。对于我们的用例,就特性而言
-
我正在使用Flatter和firebase构建一个应用程序,我想知道最好的firestore数据库结构是什么。 我希望用户能够发布消息,然后通过帖子内容和海报用户名进行搜索。 为用户创建一个集合,每个文档存储用户名和其他信息,并为帖子创建一个单独的集合,每个文档包含帖子和海报的用户名,这是否有意义? 万一帖子数量超过一百万或更多,查询这种大规模收集是否会产生额外的成本? 将每个用户的帖子作为子集合