
scikit学习回归预测结果太好了。我搞砸了什么?

我们有一些ML模型在Azure ML Studio平台上运行(初始拖动)
好消息/坏消息是我们要训练的数据非常小(数据库中有几百条记录)。这是非常不完美的数据,做出了非常不完美的回归预测,所以误差是可以预料的。那很好。对于这个问题,这很好。因为问题是,当我测试这些模型时,预测太完美了。我不明白我做错了什么,但我显然做错了什么。
(在我看来)明显值得怀疑的事情是,要么我在测试数据上进行训练,要么通过相关性找到了明显/完美的因果关系。我对train_test_split的使用告诉我,我没有对我的测试数据进行训练,我保证第二个是假的,因为这个空间是多么混乱(我们大约15年前开始对这个数据进行手动线性回归,现在仍然保持Excel电子表格能够在紧要关头手动完成,即使它远不如我们的Azure ML Studio模型准确)。
让我们看看代码。这是我的Jupyter笔记本的相关部分(如果有更好的格式,对不起):
X = myData
y = myData.ValueToPredict
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
train_size = 0.75,
test_size = 0.25)
print("X_train: ", X_train.shape)
print("y_train: ", y_train.shape)
print("X_test: ", X_test.shape)
print("y_test: ", y_test.shape)
X_列车:(300、17)
y_列车:(300,)
X_test:(101、17)
y_test:(101,)
ESTIMATORS = {
"Extra Trees": ExtraTreesRegressor(criterion = "mse",
n_estimators=10,
max_features=16,
random_state=42),
"Decision Tree": DecisionTreeRegressor(criterion = "mse",
splitter = "best",
random_state=42),
"Random Forest": RandomForestRegressor(criterion = "mse",
random_state=42),
"Linear regression": LinearRegression(),
"Ridge": RidgeCV(),
}
y_test_predict = dict()
y_test_rmse = dict()
for name, estimator in ESTIMATORS.items():
estimator.fit(X_train, y_train)
y_test_predict[name] = estimator.predict(X_test)
y_test_rmse[name] = np.sqrt(np.mean((y_test - y_test_predict[name]) ** 2)) # I think this might be wrong but isn't the source of my problem
for name, error in y_test_rmse.items():
print(name + " RMSE: " + str(error))
额外树木RMSE:0.3843540838630157
决策树RMSE:0.32838969545222946
随机森林RMSE:0.4304701784728594
线性回归RMSE:7.971345895791494e-15
山脊RMSE:0.000139197344951183
y_test_score = dict()
for name, estimator in ESTIMATORS.items():
estimator.fit(X_train, y_train)
y_test_predict[name] = estimator.predict(X_test)
y_test_score[name] = estimator.score(X_test, y_test)
for name, error in y_test_score.items():
print(name + " Score: " + str(error))
额外树木得分:0.9990166492769291
决策树得分:0.999282165241745
随机森林得分:0.998766521504593
线性回归得分:1.0
山脊得分:0.9999999998713534
我想也许我做的错误度量是错误的,所以我只看了简单的分数(这就是为什么我把两者都包括在内)。然而,两者都表明这些预测太好了,不可能是真的。请记住,输入量很小(总共约400项)。而这些数据基本上是基于天气模式对商品消费进行预测,这是一个混乱的空间,所以应该存在很多错误。
我做错了什么?
(另外,如果我能以更好的方式问这个问题或提供更多有用的信息,我将不胜感激!)
这是数据的热图。我指出了我们预测的值。

我还绘制了两个与我们预测的值相比更重要的输入(用另一个维度的颜色编码):
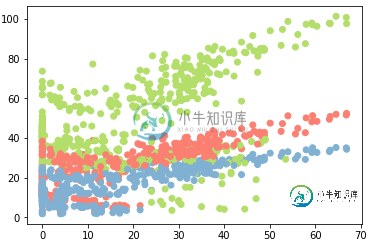
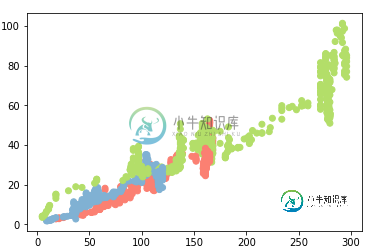
正如@jwil所指出的,我没有从我的X变量中提取我的ValueToPresion列。解决方案是添加一行来删除该列:
X = myData
y = myData.ValueToPredict
X = X.drop("ValueToPredict", 1) # <--- ONE-LINE FIX!
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
train_size = 0.75,
test_size = 0.25)
有了这个,我的错误
额外树木RMSE:1.6170428819849574
决策树RMSE:1.990459810552763
随机森林RMSE:1.699801032532343
线性回归RMSE:2.5265108241534397
山脊RMSE:2.528721533965162
额外树木得分:0.982594419361161
决策树评分:0.9736274412836977
随机森林得分:0.98076723970707
线性回归评分:0.9575098985510281
岭评分:0.95743550797321
共有1个答案

你是对的;我强烈怀疑X数据中有一个或多个特征与Y数据几乎完全相关。通常情况下,这是不好的,因为这些变量不能解释Y,而是由Y解释或与Y.共同确定来解决这个问题,考虑在X上执行Y的线性回归,然后使用简单的P值或AIC/BIC来确定哪些X变量是最不相关的。放下这些,重复这个过程,直到你的R^2开始严重下降(尽管每次都会下降一点)。剩下的变量将是预测中最相关的,并且希望您能够从该子集中识别哪些变量与Y紧密相关。
-
我有一个utf-8编码的字符串,并希望通过java http servlet响应这个字符串作为http请求的应答,但浏览器只接收到混乱的特殊字符。 为什么HttpServletResponse操作字符串,而不像BufferedWriter(OutputStreamWriter(FileOutputStream))那样直接传递字符编码? 谢谢,化疗。
-
问题内容: 我想在主要安装的Python上更新pip,特别是要获取list命令。其中还包括列表更新功能。 所以我跑了: 一切在安装上看起来都不错,但随后我去运行pip并得到了:(如果有帮助,则包括安装结束) 显然,我有点不高兴,因为这是我的系统安装的python ..我在这里阅读了一些答案,但无法确定最简单的解决方法。 问题答案: 我在linux上也有同样的消息。 但随后检查了正在调用的点。 在我
-
本文向大家介绍用scikit-learn和pandas学习线性回归的方法,包括了用scikit-learn和pandas学习线性回归的方法的使用技巧和注意事项,需要的朋友参考一下 对于想深入了解线性回归的童鞋,这里给出一个完整的例子,详细学完这个例子,对用scikit-learn来运行线性回归,评估模型不会有什么问题了。 1. 获取数据,定义问题 没有数据,当然没法研究机器学习啦。:) 这里我们用
-
在机器学习课程https://share.coursera.org/wiki/index.php/ML:Linear_Regression_with_Multiple_Variables#Gradient_Descent_for_Multiple_Variables中,它说梯度下降应该收敛。 我正在使用scikit学习的线性回归。它不提供梯度下降信息。我已经看到了许多关于stackoverflow
-
问题内容: 重构类名称时,Eclipse最近显示出一种非常奇怪的行为。例如,让我们看一下我们的一个类: 并将其重命名为“ CampaignCsvPanel”,则发生以下情况: 奇怪- 基本上每次 我重命名课程时 都会 发生。更重要的是: 我已经创建了一个全新的工作区(并再次签出了相同的项目), 并且我安装了Eclipse的新版本(即Eclipse 3.6和3.7中都发生了)。 我认为,它 必须与