
在data.table中我不能用dtplyr做什么

从表面上看,dplyr具有data.table的优点,使其听起来像dtplyr将超过dplyr。一旦dtplyr完全成熟,还有什么理由使用dplyr吗?
注意:我不是在问dplyrvsdata.table(如data.table vs dplyr:一个能做得好而另一个做得不好吗?),但是考虑到对于特定的问题,一个比另一个更好,为什么dtplyr不是使用的工具。
共有1个答案

我将尝试给出我最好的指南,但这并不容易,因为人们需要熟悉{data.table}、{dplyr}、{dtplyr}和{base R}。我使用{data.table}和许多{tidy-world}包({dplyr}除外)。两者都喜欢,尽管我更喜欢data.table的语法而不是dplyr的语法。我希望所有tidy-world软件包在必要时都使用{dtplyr}或{data.table}作为后端。
与任何其他翻译一样(想想dplyr-to-sparkly/sql),有些东西可以或不能翻译,至少目前是这样。我是说,也许有一天{dtplyr}能让它100%翻译,谁知道呢。下面的列表并不是详尽无遗的,也不是100%正确的,因为我会根据我对相关主题/包/问题/等的了解尽力回答。
重要的是,对于那些不完全准确的答案,我希望它能为您提供一些关于{data.table}应该注意哪些方面的指导,并将其与{dtplyr}进行比较,然后自己找出答案。不要认为这些答案是理所当然的。
这很容易翻译
library(data.table)
library(dplyr)
library(flights)
data <- data.table(diamonds)
# dplyr
diamonds %>%
filter(cut != "Fair") %>%
group_by(cut) %>%
summarize(
avg_price = mean(price),
median_price = as.numeric(median(price)),
count = n()
) %>%
arrange(desc(count))
# data.table
data [
][cut != 'Fair', by = cut, .(
avg_price = mean(price),
median_price = as.numeric(median(price)),
count = .N
)
][order( - count)]
{data.table}非常快&内存效率很高,因为(几乎?)一切都是从C语言中从头开始构建的,使用了按引用更新、key(想想SQL)等关键概念,以及它们在包中无处不在的不断优化(例如fifelse、fread/fread、基R采用的基数排序顺序),同时确保语法简洁一致,这就是我认为它优雅的原因。
从Integration到data.table,主要的数据操作(如子集、组、更新、联接等)被保存在一起
最后一点,作为一个例子,
# Calculate the average arrival and departure delay for all flights with “JFK” as the origin airport in the month of June.
flights[origin == 'JFK' & month == 6L,
.(m_arr = mean(arr_delay), m_dep = mean(dep_delay))]
>
我们首先在i中进行子集,以找到匹配的行索引,其中origin airport等于“JFK”,month等于6L。我们还没有对对应于这些行的整个data.table进行子集。
现在,我们看一下j,发现它只使用了两列。我们要做的是计算它们的平均值()。因此,我们只对对应于匹配行的那些列进行子集,并计算它们的平均值()。
在我看来,按引用更新是{data.table}最重要的特性,也是它如此快速的原因&内存效率。dplyr::mutate默认情况下不支持它。由于我不熟悉{dtplyr},我不确定{dtplyr}可以或不能支持多少和哪些操作。如上所述,它还取决于操作的复杂性,而操作的复杂性又反过来影响翻译。
在{data.table}中使用按引用更新有两种方法
>
{data.table}:=的赋值运算符
# Manipulating list columns
df <- purrr::map_dfr(1:1e5, ~ iris)
dt <- data.table(df)
# data.table
dt [,
by = Species, .(data = .( .SD )) ][, # `.(` shorthand for `list`
model := map(data, ~ lm(Sepal.Length ~ Sepal.Width, data = . )) ][,
summary := map(model, summary) ][,
plot := map(data, ~ ggplot( . , aes(Sepal.Length, Sepal.Width)) +
geom_point())]
# dplyr
df %>%
group_by(Species) %>%
nest() %>%
mutate(
model = map(data, ~ lm(Sepal.Length ~ Sepal.Width, data = . )),
summary = map(model, summary),
plot = map(data, ~ ggplot( . , aes(Sepal.Length, Sepal.Width)) +
geom_point())
)
df <- purrr::map_dfr(1:1e5, ~ iris)
dt <- copy(data.table(df))
bench::mark(
check = FALSE,
dt[, by = Species, .(data = list(.SD))],
df %>% group_by(Species) %>% nest()
)
# # A tibble: 2 x 13
# expression min median `itr/sec` mem_alloc `gc/sec` n_itr n_gc
# <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl> <int> <dbl>
# 1 dt[, by = Species, .(data = list(.SD))] 361.94ms 402.04ms 2.49 705.8MB 1.24 2 1
# 2 df %>% group_by(Species) %>% nest() 6.85m 6.85m 0.00243 1.4GB 2.28 1 937
# # ... with 5 more variables: total_time <bch:tm>, result <list>, memory <list>, time <list>,
# # gc <list>
有许多按引用更新的用例,甚至{data.table}用户也不会一直使用它的高级版本,因为它需要更多的代码。{dtplyr}是否支持这些开箱即用的功能,您必须自己去了解。
主要资源:用lapply()在data.table中优雅地分配多列
这涉及到更常用的:=或set。
dt <- data.table( matrix(runif(10000), nrow = 100) )
# A few variants
for (col in paste0('V', 20:100))
set(dt, j = col, value = sqrt(get(col)))
for (col in paste0('V', 20:100))
dt[, (col) := sqrt(get(col))]
# I prefer `purrr::map` to `for`
library(purrr)
map(paste0('V', 20:100), ~ dt[, (.) := sqrt(get(.))])
# For brevity, only the codes for join-operation are shown here. Please refer to the link for details
# Normal_join
x <- y[x, on = 'a']
# update_by_reference
x_2[y_2, on = 'a', c := c]
# setkey_n_update
setkey(x_3, a) [ setkey(y_3, a), on = 'a', c := c ]
注意:dplyr::left_join也进行了测试,它是最慢的,为9,000毫秒,使用的内存比{data.table}的update_by_reference和setkey_n_update都多,但比{data.table}的normal_join少。它消耗了大约2.0GB的内存。我没有包含它,因为我只想关注{data.table}。
setkey+update和update分别比normal join快11倍和6.5倍
- 在第一次联接时,
setkey+update的性能与update相似,因为setkey的开销在很大程度上抵消了其自身的性能增益 - 在第二次和随后的联接时,由于不需要
setkey,setkey+update比update快1.8倍(或比normal join快11倍)
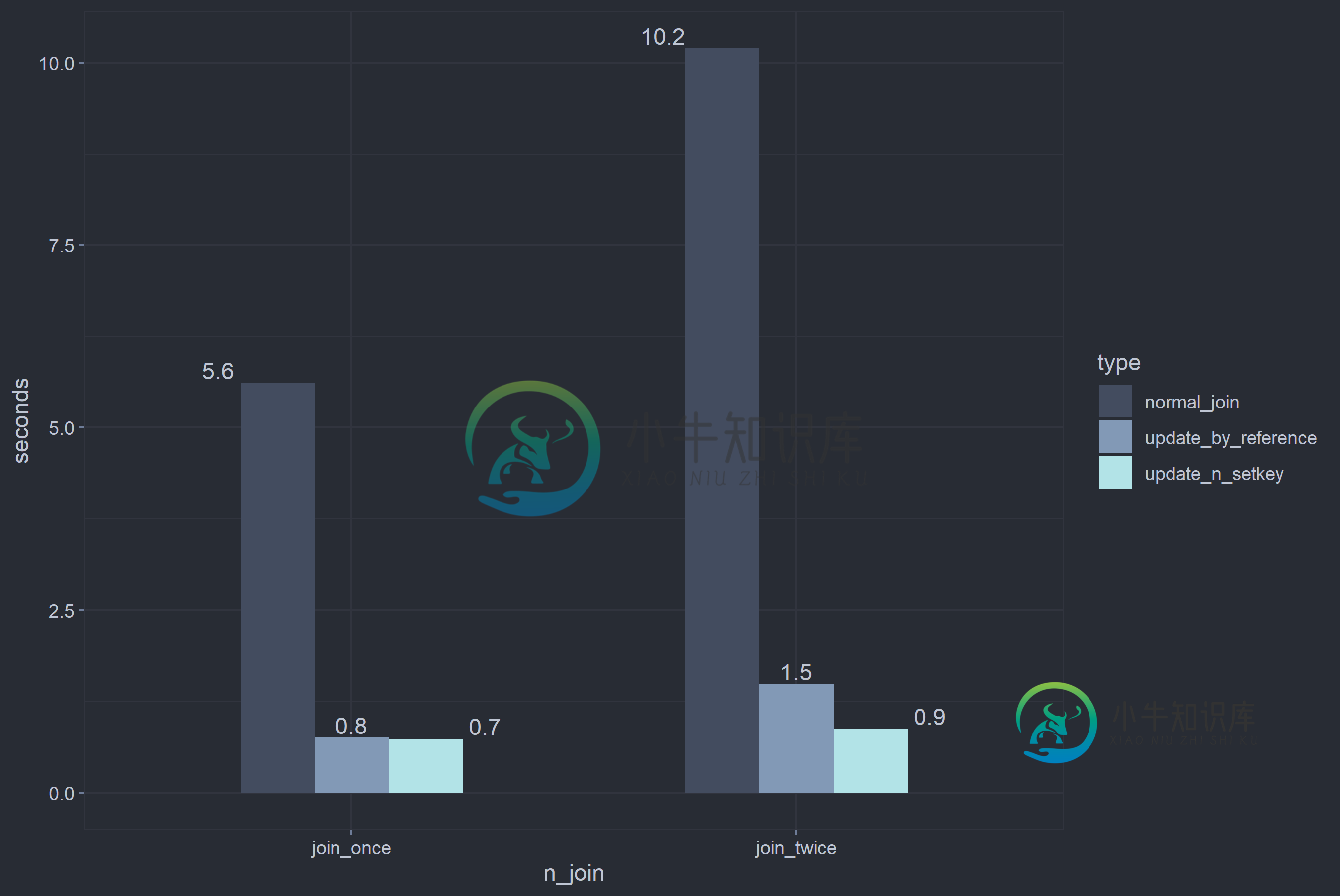
对于性能和内存高效的联接,可以使用update或setkey+update,后者的速度更快,但代价是代码更多。
为了简洁起见,让我们看看一些伪代码。逻辑是一样的。
对于一列或几列
a <- data.table(x = ..., y = ..., z = ..., ...)
b <- data.table(x = ..., y = ..., z = ..., ...)
# `update`
a[b, on = .(x), y := y]
a[b, on = .(x), `:=` (y = y, z = z, ...)]
# `setkey + update`
setkey(a, x) [ setkey(b, x), on = .(x), y := y ]
setkey(a, x) [ setkey(b, x), on = .(x), `:=` (y = y, z = z, ...) ]
对于许多专栏
cols <- c('x', 'y', ...)
# `update`
a[b, on = .(x), (cols) := mget( paste0('i.', cols) )]
# `setkey + update`
setkey(a, x) [ setkey(b, x), on = .(x), (cols) := mget( paste0('i.', cols) ) ]
setjoin(a, b, on = ...) # join all columns
setjoin(a, b, on = ..., select = c('columns_to_be_included', ...))
setjoin(a, b, on = ..., drop = c('columns_to_be_excluded', ...))
# With that, you can even use it with `magrittr` pipe
a %>%
setjoin(...) %>%
setjoin(...)
-
null
setkey。参见键和基于快速二分搜索的子集- 辅助索引和自动索引
- 使用.sd进行数据分析
- 时间序列函数:思考
frollapply。滚动函数,滚动集合体,滑动窗口,移动平均 - 滚动连接,非等连接,(某些)“交叉”连接
- {data.table}已经在速度和内存效率上奠定了基础,将来可以扩展到包括许多函数(比如它们如何实现上面提到的时间序列函数)
- 一般来说,对data.table的
I、j或by操作的操作越复杂(您几乎可以使用其中的任何表达式),我认为转换就越困难,尤其是当它与按引用更新、setkey和其他本地data.table函数(如frollapply)组合时
- 另一点与使用碱基R或TidyVerse有关。我同时使用data.table+tidyverse(dplyr/readr/tidyr除外)。对于大型操作,我经常对
stringr::str_*族函数与基本R函数进行基准测试,我发现基本R函数在一定程度上更快,因此使用这些函数。重点是,不要让自己只使用tidyverse或data.table或…,探索其他选项来完成任务。
其中许多方面与上述各点是相互关联的
>
运算复杂度
您可以了解{dtplyr}是否支持这些操作,特别是当它们组合在一起时。
在交互式会话中,处理大小数据集时的另一个有用技巧是{data.table}确实实现了它大大减少编程和计算时间的promise。
为速度和“增压行名”的重复使用变量设置键(子集不指定变量名)。
dt <- data.table(iris)
setkey(dt, Species)
dt['setosa', do_something(...), ...]
dt['virginica', do_another(...), ...]
dt['setosa', more(...), ...]
# `by` argument can also be omitted, particularly useful during interactive session
# this ultimately becomes what I call 'naked' syntax, just type what you want to do, without any placeholders.
# It's simply elegant
dt['setosa', do_something(...), Species, ...]
-
问题内容: 如果html文件是本地文件(在我的C驱动器上),则可以使用,但是如果html文件在服务器上并且图像文件是本地文件,则无法使用。这是为什么? 任何可能的解决方法? 问题答案: 如果客户端可以请求本地文件系统文件,然后使用JavaScript找出其中的内容,则将是一个安全漏洞。 解决此问题的唯一方法是在浏览器中构建扩展。Firefox扩展和IE扩展可以访问本地资源。Chrome的限制更为严
-
我正在尝试使用文件系统。我的< code>CMakeLists.txt中有< code>-std=c 11 -std=c 1y。GCC版本为4.9.2。然而,我得到了一个错误: 使用的正确方法是什么?
-
我试图在我自己的包中使用data.table包。MWE如下:
-
问题内容: 我正在学习Go,并且一直沉迷于Go旅游(exercise- stringer.go:https : //tour.golang.org/methods/7)。 这是一些代码: 所以我想出了is 的内部表示,所以散布算子起作用了。但我得到: 有没有搞错?字符串切片也不起作用,这是怎么回事? 编辑 :对不起,我的问题中有一个错误- 错误是关于type的,不是。我在玩代码,并且粘贴了错误的输
-
问题内容: 在Python中,用于初始化不可变类型,通常用于初始化可变类型。如果将其从语言中删除,该怎么办(轻松)? 例如, 可以这样重写: 为澄清问题的范围:这不是一个问题关于如何以及是使用或它们之间有什么区别。这是一个问题,如果从语言中删除将会发生什么。有什么坏事吗?事情会变得很难或不可能吗? 问题答案: 您可以在中进行的所有操作都可以在中完成。 那么,为什么要使用? 因为您不必将实例存储在变
-
我试图使用Java8Javadoc工具,但它抱怨是一个未知标记: 我看到有一些方法可以禁用doclint,但我真的想知道哪些标签列表被支持(或者为什么这个不支持)。 更多信息在这个问题,这个问题和从这个博文。