
指定YARN节点标签时,YARN应用程序无法启动

我试图使用YARN节点标签来标记工作节点,但当我在YARN上运行应用程序(Spark或simple YARN app)时,这些应用程序无法启动。
>
使用Spark时,当指定--conf Spark.yarn.am.nodelabelexpression=“my-label”时,作业无法启动(在提交的应用程序[...]上被阻止,请参见下面的详细信息)。
对于YARN应用程序(如distributedshell),当指定-node_label_expression my-label时,应用程序两者都不能启动
以下是我到目前为止所做的测试。
我使用Google Dataproc运行我的集群(例如:4个worker,2个在可抢占节点上)。我的目标是强制任何YARN应用程序主程序运行在一个不可抢占的节点上,否则该节点随时可能被关闭,从而使应用程序难以失效。
我正在使用YARN属性(--properties)创建集群,以启用节点标签:
gcloud dataproc clusters create \
my-dataproc-cluster \
--project [PROJECT_ID] \
--zone [ZONE] \
--master-machine-type n1-standard-1 \
--master-boot-disk-size 10 \
--num-workers 2 \
--worker-machine-type n1-standard-1 \
--worker-boot-disk-size 10 \
--num-preemptible-workers 2 \
--properties 'yarn:yarn.node-labels.enabled=true,yarn:yarn.node-labels.fs-store.root-dir=/system/yarn/node-labels'
-
null
yarn rmadmin -addToClusterNodeLabels "my-label(exclusive=false)"
yarn rmadmin -replaceLabelsOnNode "\
[WORKER_0_NAME].c.[PROJECT_ID].internal=my-label \
[WORKER_1_NAME].c.[PROJECT_ID].internal=my-label"
当我运行一个简单的示例(sparkpi)而不指定有关节点标签的信息时:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
/usr/lib/spark/examples/jars/spark-examples.jar \
10
在YARN Web UI的Scheduler选项卡中,我看到应用程序在
上启动。
但是当我运行指定Spark.yarn.am.nodelabelexpression以设置Spark应用程序主程序位置的作业时:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--conf spark.yarn.am.nodeLabelExpression="my-label" \
/usr/lib/spark/examples/jars/spark-examples.jar \
10
-
null
我怀疑与标签分区相关的队列(不是
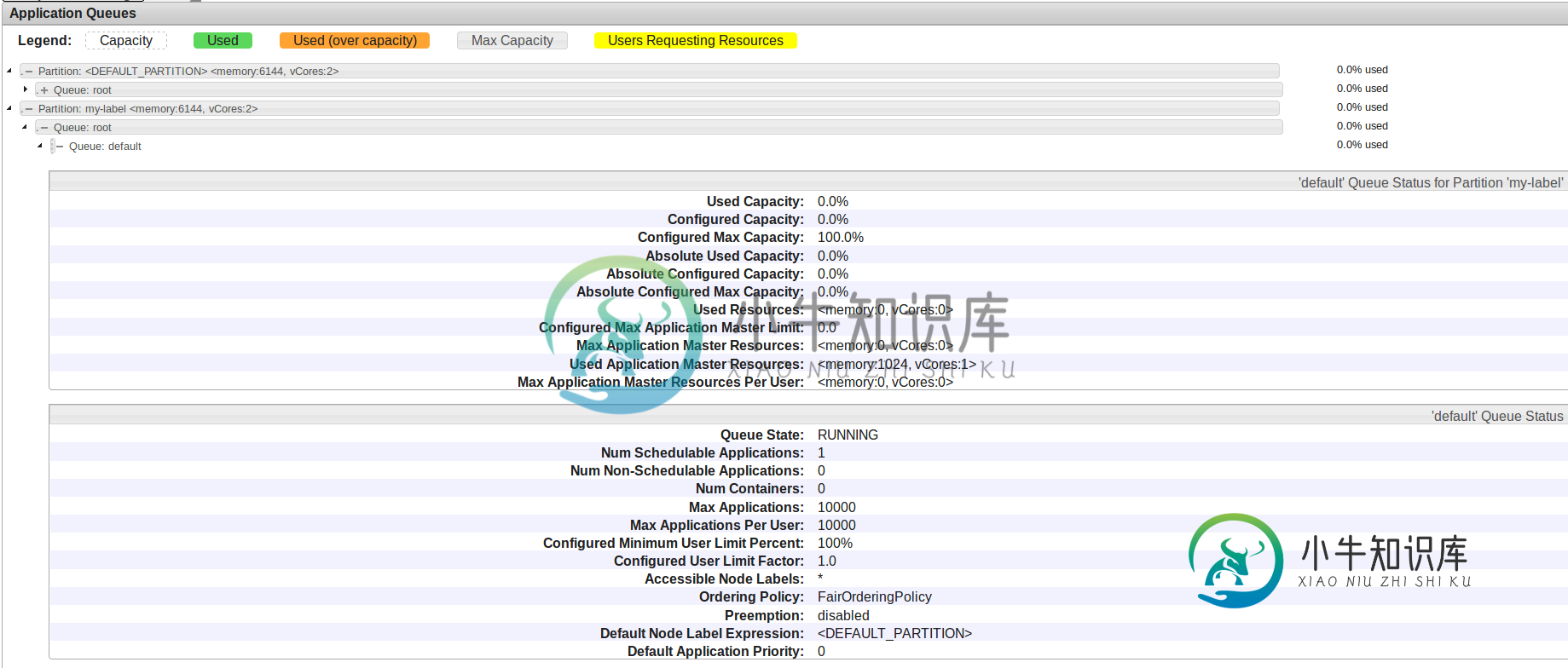
这里,使用的应用程序主资源是
,但是最大应用程序主资源是
。这解释了为什么应用程序无法启动,但我不知道如何改变这一点。
我尝试更新不同的参数,但没有成功:
yarn.scheduler.capacity.root.default.accessible-node-labels=my-label
yarn.scheduler.capacity.root.default.accessible-node-labels.my-label.capacity
yarn.scheduler.capacity.root.default.accessible-node-labels.my-label.maximum-capacity
yarn.scheduler.capacity.root.default.accessible-node-labels.my-label.maximum-am-resource-percent
yarn.scheduler.capacity.root.default.accessible-node-labels.my-label.user-limit-factor
yarn.scheduler.capacity.root.default.accessible-node-labels.my-label.minimum-user-limit-percent
hadoop jar \
/usr/lib/hadoop-yarn/hadoop-yarn-applications-distributedshell.jar \
-shell_command "echo ok" \
-jar /usr/lib/hadoop-yarn/hadoop-yarn-applications-distributedshell.jar \
-queue default \
-node_label_expression my-label
应用程序无法启动,日志不断重复:
info distributedshell.client:从ASM获得应用程序报告,appid=6,clienttoAmtoken=null,appDiagnostics=application被激活,等待为AM分配资源。详细信息:AM Partition=my-label;分区资源=
如果我没有指定-node_label_expression my-label,应用程序将在
上启动并成功。
- 我是不是在标签上做错了什么?但是,我遵循了官方文档和本指南
- 这是与DataProc有关的特定问题吗?因为以前的指南似乎适用于其他环境
- 也许我需要创建一个特定的队列并将其与我的标签相关联?但是,由于我运行的是一个“一次性”集群来运行一个星星之火作业,所以不需要有特定的队列,所以在缺省根队列上运行作业对我的用例来说不是问题
感谢你的帮助
共有1个答案

一位Google工程师回答了我们(关于我们提出的一个私人问题,而不是在PIT中),并通过指定Dataproc集群创建的初始化脚本给出了解决方案。我不认为问题来自Dataproc,这基本上只是纱线配置。在创建节点标签(my-label)之后,脚本在capactor-scheduler.xml中设置以下属性:
<property>
<name>yarn.scheduler.capacity.root.accessible-node-labels</name>
<value>my-label</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.accessible-node-labels.my-label.capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.accessible-node-labels</name>
<value>my-label</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.accessible-node-labels.my-label.capacity</name>
<value>100</value>
</property>
从脚本附带的注释来看,“在root(根队列)和root.default(默认队列应用程序实际运行)上设置accessible-node-labels”。root.default部分是我的测试中缺少的部分。两者的容量都设置为100。
然后,需要重新启动YARN(systemCTL restart hadoop-yarn-resourceManager.service)来验证修改。
希望对有同样问题或类似问题的人有所帮助。
-
编辑:根据Jim Rush的建议,我现在使用rc.local而不是init.d direclty来运行永远启动启动。 你知道为什么这不起作用吗?我在覆盆子皮B+上运行覆盆子。我已经运行了/etc/init.d kuuyi start和forever kicks并启动了该应用程序。只是启动机器后就不会发生了。 在这方面的任何帮助都是非常感谢的,我在这方面就像乳制品日后的旧奶酪布一样筋疲力尽。
-
问题内容: 我想使用文件浏览器创建文本编辑器,所以当我启动应用程序时,我想在程序中在JTree上添加节点,以便它向我显示所有文件和文件夹,例如在“我的文档”文件夹中,并允许我访问这些文件和文件夹(尤其是文件夹)。我试图从这个例子中弄清楚安德鲁·汤普森是如何做到的, 但是我失败了。我使用此示例为“我的文档”中的所有文件和文件夹创建了节点 。但这就是全部,当单击表示文件夹的节点之一时,我无法弄清楚如何
-
第一章 简介 2016年10月11日,Facebook将Yarn包管理器开源在了github上,在github上得到了很高的关注度,短短半年内github的star超过了2万多。 第二章 优势 2-1 极速 Yarn 缓存它下载的每个包,所以无需重复下载。它还并行化操作以最大化资源利用,所以安装时间比以往快。 2-2 超级安全 Yarn 在每个安装包的代码执行前使用校验码验证包的完整性。 2-3
-
Yarn 是一个由 Facebook 贡献的 Javascript 包管理器。 特性: 离线模式:如果您之前下载了软件包,则可以在没有任何互联网连接的情况下安装。 确定性:无论安装顺序如何,相同的依赖关系将以相同的方式安装在计算机上。 网络性能:Yarn 有效地将请求排序,避免请求堆积,以最大限度地提高网络利用率。 多个注册表:无论从 npm 或 Bower 安装任何包,能保持包工作流程相同。 网
-
问题内容: 我事先意识到这是一个模糊的问题,但我对在这里还能尝试的其他方法感到困惑…… 我一直在研究其他SO问题并遵循他们的建议,但到目前为止,还没有任何问题可以解决我的问题。 这是我遇到的具体错误。 我的文件是最新的,将保留我的所有依赖关系,并具有属性,但仍然出现此错误。 如果我通过SSH进入我的目录并运行,则可以正常运行。但是,我不能只是永远在后台运行它。 我还尝试过通过浏览器停止和重新启动,