
树中分类错误的实例与混淆矩阵不匹配

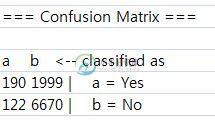
所有规则中不正确分类(见树)的总和是2097(来自895 700 428 74)。但是混淆矩阵是2121(来自1999 122)。有人能解释一下差异吗?为什么数字不同?

共有1个答案

分类器模型描述的Weka输出包含两个部分
- 培训数据错误
- 分层交叉验证
第一种方法只是根据训练数据本身评估经过训练的分类器,而第二种方法则进行交叉验证,在交叉验证中,它将每个类的实例平均分布在每个折叠中。因此,与简单交叉验证相比,分层交叉验证可以更好地描述分类器的性能。
我想你已经发布了分层交叉验证的混淆矩阵
决策树输出在link中有很好的描述https://weka.wikispaces.com/Primer#classifiers.此外,树中显示的未分类示例与分层交叉验证部分下混乱矩阵中显示的示例不同。
希望我是对的。
-
我一直在使用Weka的J48决策树将RSS提要中的关键字频率分类为目标类别。我想我可能在协调生成的决策树与报告的正确分类的实例数以及混淆矩阵中的实例数方面存在问题。 例如,我的一个. arff文件包含以下数据摘录: 以此类推:总共有64个关键字(列)和570行,其中每一行都包含一天提要中关键字的频率。在这种情况下,10天内有57条feed,总共有570条记录需要分类。每个关键字都以代理项编号作为前
-
我正在y_test并y_pred混淆矩阵。我的数据用于多标签分类,因此行值是一种热编码。 我的数据有30个标签,但在输入混淆矩阵后,输出只有11行和列,这让我很困惑。我想我应该有一辆30X30的。 它们的格式是numpy数组。(y\u test和y\u pred是我使用dataframe.values将其转换为numpy数组的数据帧) y\U测试。形状 y_test y\u预测。形状 y\u预测
-
如何分析Weka中的混淆矩阵,以获得准确度?我们知道,由于数据集不平衡,精度不准确。混淆矩阵如何“确认”准确性? 示例:a)准确率96.1728% b) 准确率:96.8% 等...
-
原始数据集如上图所示。CO(ppm)是因变量。 对于上面显示的二进制分类问题,我试图获得混淆矩阵。我有由y_pred和y_test生成的数组,数据类型不匹配,因为y_pred输出的值范围为0到1(sigmoid激活函数),而y_test的数组仅由0和1组成。 如果有人能帮我找到一种绘制混淆矩阵的方法,我将不胜感激。 非常感谢。
-
目前我们衡量分类器准确率的方式是使用以下公式:正确分类的记录数÷记录总数。 有时我们会需要一个更为详细的评价结果,这时就会用到一个称为混淆矩阵的可视化表格。 表格的行表示测试用例实际所属的类别,列则表示分类器的判断结果。 混淆矩阵可以帮助我们快速识别出分类器到底在哪些类别上发生了混淆,因此得名。 让我们看看运动员的示例,这个数据集中有300人,使用十折交叉验证,其混淆矩阵如下: 可以看到,100个
-
对不起,我是新来WEKA,刚刚学习。 在我的决策树(J48)分类器输出中,有一个混淆矩阵: 我如何读取这个矩阵?