
使用OCR(光学字符识别)读取扫描PDF(JPEG)的内容

我一直在尝试使用OCR(光学字符识别)隐蔽扫描的不可选择PDF(JPEG)。
要转换的扫描PDF文档
但是,我得到一个错误作为附件。
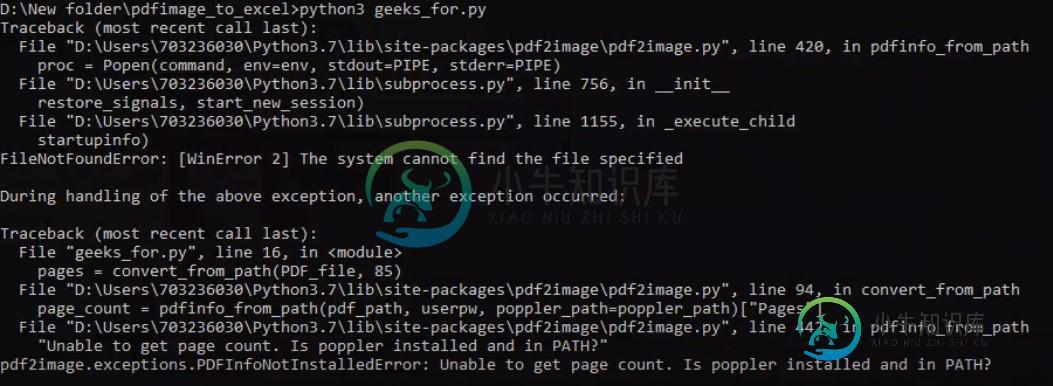
请调查此事,并建议我得到预期的结果。
# Import libraries
from PIL import Image
import pytesseract
import sys
from pdf2image import convert_from_path
import os
# Path of the pdf
PDF_file = "document.pdf"
'''
Part #1 : Converting PDF to images
'''
# Store all the pages of the PDF in a variable
pages = convert_from_path(PDF_file, 500)
# Counter to store images of each page of PDF to image
image_counter = 1
# Iterate through all the pages stored above
for page in pages:
# Declaring filename for each page of PDF as JPG
# For each page, filename will be:
# PDF page 1 -> page_1.jpg
# PDF page 2 -> page_2.jpg
# PDF page 3 -> page_3.jpg
# ....
# PDF page n -> page_n.jpg
filename = "page_"+str(image_counter)+".jpg"
# Save the image of the page in system
page.save(filename, 'JPEG')
# Increment the counter to update filename
image_counter = image_counter + 1
'''
Part #2 - Recognizing text from the images using OCR
'''
# Variable to get count of total number of pages
filelimit = image_counter-1
# Creating a text file to write the output
outfile = "out_text.txt"
# Open the file in append mode so that
# All contents of all images are added to the same file
f = open(outfile, "a")
# Iterate from 1 to total number of pages
for i in range(1, filelimit + 1):
# Set filename to recognize text from
# Again, these files will be:
# page_1.jpg
# page_2.jpg
# ....
# page_n.jpg
filename = "page_"+str(i)+".jpg"
# Recognize the text as string in image using pytesserct
text = str(((pytesseract.image_to_string(Image.open(filename)))))
# The recognized text is stored in variable text
# Any string processing may be applied on text
# Here, basic formatting has been done:
# In many PDFs, at line ending, if a word can't
# be written fully, a 'hyphen' is added.
# The rest of the word is written in the next line
# Eg: This is a sample text this word here GeeksF-
# orGeeks is half on first line, remaining on next.
# To remove this, we replace every '-\n' to ''.
text = text.replace('-\n', '')
# Finally, write the processed text to the file.
f.write(text)
# Close the file after writing all the text.
f.close()
附上要转换的文档和我面临的错误。
共有1个答案

问题出在您的pdf到图像的转换中。我没有尝试过pdf2image。我使用Fitz。该程序甚至能够提取单个pdf页面中存在的多个图像。
安装包
pip install PyMuPDF
然后
import fitz
def converted(directory_to_store, path_of_pdf_file):
file = fitz.open(path_of_pdf_file)
page = len(file)
j = 0
for i in range(page):
for image in file.getPageImageList(i):
my_xref = image[0]
pic = fitz.Pixmap(file, my_xref)
final_image = fitz.Pixmap(fitz.csRGB, pic)
file_name = str(j) + '.png'
image_path = directory_to_store + file_name
final_image.writePNG(img_path)
j+=1
pic = None
final_pic = None
print('Conversion Complete')
-
问题内容: 我目前正在从事一个涉及Android光学字符识别的项目,确实需要一些在该领域有经验的人的指导。 有人告诉我首先要使用Android设置OpenCV(使用Android 设置OpenCv)并从那里开始。从那时起,我建立了OpenCV,并使其具有所有示例(OpenCV android示例 )和教程。 我的问题是我无法从这里找到明确的方向,我在这里找到了一个相关问题,其答案指向了教程,但是我
-
任何java库?如何使搜索文本使用任何java库?开源或付费。 如何使用PDFBox将OCR应用于pdf?如何使用pdfbox以编程方式搜索pdf文本我搜索了很多。没有找到任何解决办法。任何人都可以粘贴OCR PDFBox的代码。
-
问题内容: 我正在从一个文件中读取,该文件在一行上读取所有内容: 然后,我的扫描程序会从文件中读取该文件并将其放入字符串中: 现在,我希望输出为: 但是相反,我得到了与输入完全相同的东西。也就是说,每个\ n都包含在输出中,并且所有内容都在一行中而不是单独的行中。 我以为Scanner能够正确读取转义字符,但它会像\\ n一样将其复制到String上。 问题答案: 如果写的是文件,则不能使用,因为
-
问题内容: 编辑 以便进一步阅读:问题是我的输入文件已损坏。 我不明白我在做什么错: 我正在使用此代码: 哪个工作正常。现在,由于某种原因,我想换一个扫描仪。我的代码变成: 这次,我们从不输入while,因为r.hasNextLine()始终返回“ false”。关于我在做什么错的任何想法吗? 我精确地说,没有其他更改,文件仍然相同。 编辑 :我还精确地我尝试了另一个文件,并得到相同的结果,这意味
-
我想知道PDF是否是使用OCR从扫描文档创建的。 为了使扫描文档中的文本可以选择,我猜相同的文本是使用透明颜色、特殊字体。。。 我正在使用pdfbox,我查看了字体、颜色和许多其他属性,没有发现任何特殊之处。
-
问题内容: 我有一个小字节数组(小于25K),可以作为较大的邮件信封的一部分进行接收和解码。有时,这是图像,而且是JPG。除字节数组外,我没有其他上下文信息,并且需要标识这是否是图像以及图像是否为JPG类型。 是否有一些魔术数字或魔术字节存在于开头,结尾或某个偏移量处,我可以查看它们以识别它? 我的代码示例如下(从内存而不是c / p): 我真的需要什么会 方法,甚至指向详细说明它的规范的指针。我