
无法显示数据帧的列

当我试图打印我的数据集的单个列时,它显示错误
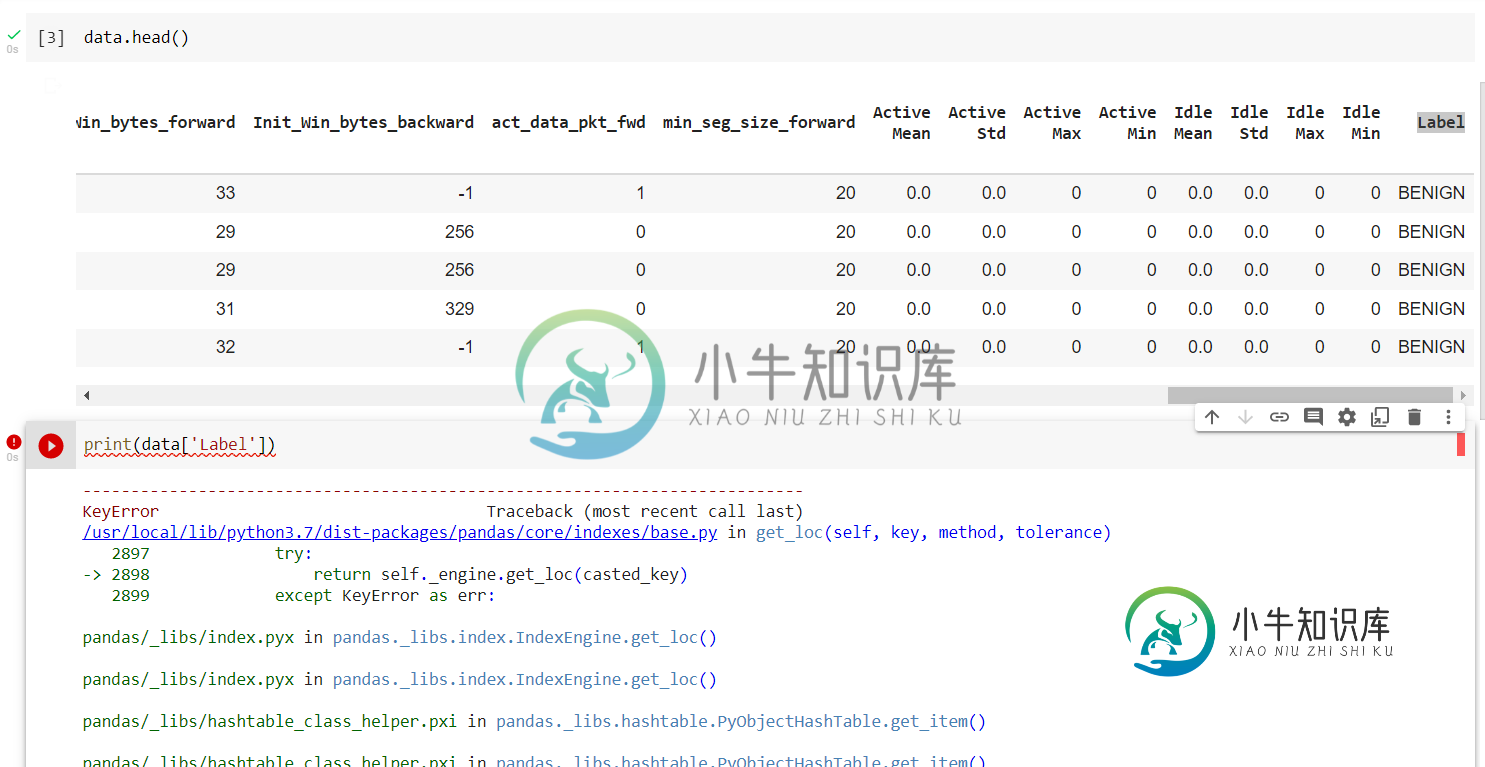
KeyError回溯(最近一次调用上次)~\anaconda3\lib\site packages\pandas\core\index\base。py in get_loc(自身、键、方法、公差)2645 try:-
熊猫库\索引。大熊猫中的pyx_图书馆。指数IndexEngine。获取_loc()
熊猫库\索引。大熊猫中的pyx_图书馆。指数IndexEngine。获取_loc()
pandas\u libs\hashtable\u class\u助手。熊猫体内的pxi_图书馆。哈希表。PyObjectHashTable。获取_项()
pandas\u libs\hashtable\u class\u助手。熊猫体内的pxi_图书馆。哈希表。PyObjectHashTable。获取_项()
关键错误:'标签'
在处理上述异常期间,发生了另一个异常:
KeyError Traceback(最近的调用最后)在----
~\anaconda3\lib\site packages\pandas\core\frame。getitem(self,key)2798中的py,如果self。柱。N级
~\anaconda3\lib\site packages\pandas\core\index\base。在get_loc(自我、键、方法、公差)2646中的py返回自我_发动机get_loc(钥匙)2647,钥匙错误除外:-
熊猫库\索引。大熊猫中的pyx_图书馆。指数IndexEngine。获取_loc()
熊猫库\索引。大熊猫中的pyx_图书馆。指数IndexEngine。获取_loc()
pandas\u libs\hashtable\u class\u助手。熊猫体内的pxi_图书馆。哈希表。PyObjectHashTable。获取_项()
pandas\u libs\hashtable\u class\u助手。熊猫体内的pxi_图书馆。哈希表。PyObjectHashTable。获取_项()
关键错误:'标签'
data['Label']
共有2个答案

如果您有DataFrame,并且希望从该DataFrame中访问或选择特定的几行/列,则可以使用方括号。
现在假设您想从数据(根据您的问题)数据框中选择一列。
data["Label"]
但是如果您不知道这些列。您可以获取列列表,然后显示列数据。
columns = data.columns.values.tolist()
data[columns[index]]

可能列名后面有空格。试着打印列名
打印(数据列)
或者试着在之后打印专栏
数据。列=数据。柱。str.strip()
-
嗨,我需要同时显示xml和json数据。我可以通过JaxB在本地看到这一点,但在服务器上看不到相同的代码。当我把它部署到服务器时,我得到了这个错误。我不知道如何解决这个错误。无法解决这一点,尝试了很多但没有发生,在本地一切都很好,但当涉及到服务器它显示不同的异常。 错误500:org.springframework.web.util.NestedServletException:请求处理失败;嵌套
-
使用pyspark数据帧,你如何做相当于熊猫 我想列出pyspark数据框列中的所有唯一值。 不是 SQL 类型方式(注册模板,然后 SQL 查询不同的值)。 此外,我不需要< code>groupby然后< code>countDistinct,而是希望检查该列中的不同值。
-
我有两个数据帧,它们共享多个公共列,如下所示: 第一个: 而第二个: 我想保留中的行,其列也存在于中。例如,df2的第27行有值,对于,这些值并不都存在于(因为df1只对列有值
-
问题内容: 我正在尝试使用json在extjs中创建一个gridview。由于某种原因,我的gridview不显示任何数据。我试图用Firebug调试它。我可以在“响应”部分中看到结果。这就是我在“响应”中的内容。 {“ ContentEncoding”:null,“ ContentType”:null,“ Data”:“ {\ r \ n \” myTable \“:[\ r \ n {\ r
-
我想知道如何获取日期列的值。键入df时,“日期”列不显示。柱。我正试图用df将这个df转换成一个Json文件。to_json(),它获取除日期以外的所有值。谢谢大家。 输入[49]:输入(df)输出[49]:熊猫。果心框架数据帧
-
我想使用PySpark创建spark数据帧,为此我在PyCharm中运行了以下代码: 但是,它会返回此错误: 使用 Spark 的默认 log4j 配置文件:组织/缓存/火花/log4j-defaults.属性 将默认日志级别设置为“WARN”。要调整日志记录级别,请使用 sc.setLogLevel(新级别)。对于 SparkR,请使用 setLogLevel(新级别)。18/01/08 10: