
标准C 11是否保证memory_order_seq_cst防止StoreLoad对原子周围的非原子重新排序?

标准C 11是否保证memory_order_seq_cst防止StoreLoad围绕非原子内存访问的原子操作重新排序?
众所周知,C 11中有6个d::memory_order,它指定了如何围绕原子操作对常规的非原子内存访问进行排序-工作草案,编程语言标准C 2016-07-12:http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
§29.3秩序和一致性
§29.3/1
枚举memory\u顺序指定1.10中定义的详细常规(非原子)内存同步顺序,并可能提供操作顺序。其枚举值及其含义如下:
还知道,这6memory_orders防止这些重新排序:
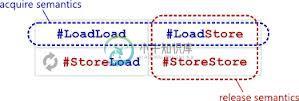
但是,对于常规的非原子内存访问,或者仅针对具有相同内存顺序的其他原子,是否阻止了围绕原子操作的StoreLoad重新排序?
一、 e.为了防止这种存储加载重新排序,我们应该对存储和加载都使用std::memory\u order\u seq\u cst,还是只对其中一个使用?
std::atomic<int> a, b;
b.store(1, std::memory_order_seq_cst); // Sequential Consistency
a.load(std::memory_order_seq_cst); // Sequential Consistency
关于获取-释放语义很清楚,它准确地指定了跨原子操作的非原子内存访问重排序:http://en.cppreference.com/w/cpp/atomic/memory_order
为了防止StoreLoad重新排序,我们应该使用std::memory\u order\u seq\u cst。
两个示例:
std::memory_order_seq_cst对于STORE和LOAD:有MFENCE
StoreLoad不能被重新排序-GCC 6.1.0x86_64:https://godbolt.org/g/mVZJs0
std::atomic<int> a, b;
b.store(1, std::memory_order_seq_cst); // can't be executed after LOAD
a.load(std::memory_order_seq_cst); // can't be executed before STORE
StoreLoad可以重新排序-GCC 6.1.0 x86\u 64:https://godbolt.org/g/2NLy12
std::atomic<int> a, b;
b.store(1, std::memory_order_release); // can be executed after LOAD
a.load(std::memory_order_seq_cst); // can be executed before STORE
此外,如果C/C编译器使用C/C 11到x86的替代映射,这会在加载之前刷新存储缓冲区:MFENCE,MOV(from memory),那么我们也必须使用std::memory\u order\u seq\u cst来加载:http://www.cl.cam.ac.uk/~ pes20/cpp/cpp0xmappings。这个例子中的html在另一个问题作为方法(3)中讨论:它在处理器x86/x86\u 64中的指令LFENCE有意义吗?
也就是说,我们应该使用std::memory_order_seq_cst为STORE和LOAD生成MFENCE保证,防止StoreLoad重新排序。
原子加载或存储的内存顺序cst是否为真:
>
指定获取-释放语义-防止:LoadLoad、LoadStore、StoreStore围绕原子操作重新排序,用于常规的非原子内存访问,
但是,仅针对具有相同内存顺序的其他原子操作,防止在原子操作周围重新排序StoreLoad?
共有2个答案

std::memory\u order\u seq\u cst保证编译器和cpu都不会重新排序。在这种情况下,相同的内存顺序就像一次只执行一条指令一样。
但是编译器优化混淆了这些问题,如果您关闭-O3,那么Geofence就在那里。
编译器可以看到,在使用-O3的测试程序中,没有mfence的结果,因为程序太简单了。
如果你像这样用另一只手操作它,你可以看到障碍物dmb ish。
因此,如果您的程序更复杂,您可能会在这部分代码中看到mford,但如果编译器可以分析并推理不需要它,则不会。

不,标准C 11不保证memory\u order\u seq\u cst可以防止非原子的在原子(seq\u cst)周围的StoreLoad重新排序。
即使是标准C 11也不能保证memory\u order\u seq\u cst可以防止原子(non-seq\u cst)围绕一个原子(seq\u cst)进行存储加载重新排序。
工作草案,编程语言C标准2016-07-12:http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
所有memory\u order\u seq\u cst操作上应有一个总订单S-C 11标准:
§29.3
3.
所有memory\u order\u seq\u cst操作上应有一个总顺序S,与所有受影响位置的“之前发生”顺序和修改顺序一致,以便从原子对象M加载值的每个memory\u order\u seq\u cst操作B观察以下值之一:。。。
但是,任何排序弱于memory\u order\u seq\u cst的原子操作都没有顺序一致性,也没有单一的总顺序,即非memory\u order\u seq\u cst操作可以在允许的方向上使用memory\u order\u seq\u cst操作重新排序-C 11标准:
§29.3
8.[注:memory\u order\u seq\u cst仅确保无数据争用且仅使用memory\u order\u seq\u cst操作的程序的顺序一致性。除非非常小心,否则使用较弱的顺序将使此保证无效。特别是,memory\u order\u seq\u cst fences仅确保fences本身的总顺序。通常,fences不能用于恢复顺序原子操作的一致性与较弱的订购规范。-结束注释]
C编译器还允许这样的重新排序:
在x86\u 64上
通常-如果在编译器中seq_cst实现为存储后的屏障,那么:
<代码>商店-C(放松)
可以重新排序为加载B(seq\u cst)
商店-C(放松)
GCC 7.0生成的Asm截图x86_64:https://godbolt.org/g/4yyeby
此外,理论上可能-如果在编译器中seq\u cst在加载前实现为屏障,则:
<代码>存储-A(seq\u cst)
荷载-C(acq\U rel)
可以重新排序为加载C(acq\U rel)
存储-A(seq\u cst)
<代码>存储-A(seq\u cst)
荷载-C(松弛)
可以重新排序为加载C(松弛)
存储-A(seq\u cst)
同样在PowerPC上可以这样重新排序:
<代码>存储-A(seq\u cst)
商店-C(放松)
可以重新排序到存储C(放松)
存储-A(seq\u cst)
如果甚至允许原子变量跨原子(seq\u cst)重新排序,那么非原子变量也可以跨原子(seq\u cst)重新排序。
GCC 4.8 PowerPC生成的Asm屏幕截图:https://godbolt.org/g/BTQBr8
更多细节:
在x86\u 64上
<代码>STORE-C(发布)
可以重新排序为加载B(seq\u cst)
<代码>STORE-C(发布)
Intel®64和IA-32体系结构
8.2.3.4货物可与早期仓库一起重新订购到不同的位置
一、 e.x86\U 64代码:
STORE-A(seq_cst);
STORE-C(release);
LOAD-B(seq_cst);
可以重新排序为:
STORE-A(seq_cst);
LOAD-B(seq_cst);
STORE-C(release);
之所以会发生这种情况,是因为在c.store和b.load之间不是mfence:
x86_64-GCC 7.0:https://godbolt.org/g/dRGTaO
C
#include <atomic>
// Atomic load-store
void test() {
std::atomic<int> a, b, c;
a.store(2, std::memory_order_seq_cst); // movl 2,[a]; mfence;
c.store(4, std::memory_order_release); // movl 4,[c];
int tmp = b.load(std::memory_order_seq_cst); // movl [b],[tmp];
}
它可以重新排序为:
#include <atomic>
// Atomic load-store
void test() {
std::atomic<int> a, b, c;
a.store(2, std::memory_order_seq_cst); // movl 2,[a]; mfence;
int tmp = b.load(std::memory_order_seq_cst); // movl [b],[tmp];
c.store(4, std::memory_order_release); // movl 4,[c];
}
此外,x86/x86\u 64中的顺序一致性可以通过四种方式实现:http://www.cl.cam.ac.uk/~ pes20/cpp/cpp0xmappings。html
加载(无Geofence)并存储加载(无Geofence)并锁定XCHG<代码>MFENCE<代码>加载<代码>和<代码>存储<代码>(无Geofence)- 锁定XADD(0)和存储(无Geofence)
1和2种方式:LOADand(STOREMFENCE)/(LOCK XCHG)-我们在上面回顾了- 3和4种方式:(
MFENCELOAD)/LOCK XADD和STORE-允许下一次重新排序:
<代码>存储-A(seq\u cst)
荷载-C(acq\U rel)
可以重新排序为加载C(acq\U rel)
存储-A(seq\u cst)
<代码>存储-A(seq\u cst)
荷载-C(松弛)
可以重新排序为加载C(松弛)
存储-A(seq\u cst)
允许存储加载重新排序(表5-PowerPC):http://www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.06.07c.pdf
加载后重新排序的商店
即PowerPC代码:
STORE-A(seq_cst);
STORE-C(relaxed);
LOAD-C(relaxed);
LOAD-B(seq_cst);
可以重新排序为:
LOAD-C(relaxed);
STORE-A(seq_cst);
STORE-C(relaxed);
LOAD-B(seq_cst);
PowerPC-GCC 4.8:https://godbolt.org/g/xowFD3
C
#include <atomic>
// Atomic load-store
void test() {
std::atomic<int> a, b, c; // addr: 20, 24, 28
a.store(2, std::memory_order_seq_cst); // li r9<-2; sync; stw r9->[a];
c.store(4, std::memory_order_relaxed); // li r9<-4; stw r9->[c];
c.load(std::memory_order_relaxed); // lwz r9<-[c];
int tmp = b.load(std::memory_order_seq_cst); // sync; lwz r9<-[b]; ... isync;
}
通过将a.store分成两部分-可以将其重新排序为:
#include <atomic>
// Atomic load-store
void test() {
std::atomic<int> a, b, c; // addr: 20, 24, 28
//a.store(2, std::memory_order_seq_cst); // part-1: li r9<-2; sync;
c.load(std::memory_order_relaxed); // lwz r9<-[c];
a.store(2, std::memory_order_seq_cst); // part-2: stw r9->[a];
c.store(4, std::memory_order_relaxed); // li r9<-4; stw r9->[c];
int tmp = b.load(std::memory_order_seq_cst); // sync; lwz r9<-[b]; ... isync;
}
其中,从内存加载lwz r9
同样在PowerPC上可以这样重新排序:
<代码>存储-A(seq\u cst)
商店-C(放松)
可以重新排序到存储C(放松)
存储-A(seq\u cst)
因为PowerPC具有弱内存排序模型-允许存储-存储重新排序(表5-PowerPC):http://www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.06.07c.pdf
门店后重新排序的门店
一、 e.在PowerPC上,可以使用其他存储对存储进行重新排序,然后可以对前面的示例进行重新排序,例如:
#include <atomic>
// Atomic load-store
void test() {
std::atomic<int> a, b, c; // addr: 20, 24, 28
//a.store(2, std::memory_order_seq_cst); // part-1: li r9<-2; sync;
c.load(std::memory_order_relaxed); // lwz r9<-[c];
c.store(4, std::memory_order_relaxed); // li r9<-4; stw r9->[c];
a.store(2, std::memory_order_seq_cst); // part-2: stw r9->[a];
int tmp = b.load(std::memory_order_seq_cst); // sync; lwz r9<-[b]; ... isync;
}
其中存储到内存<代码>stw r9-
-
正如在C 11中所知,有6个内存顺序,在关于std::memory\u order\u acquire的文档中: http://en.cppreference.com/w/cpp/atomic/memory_order memory\u order\u acquire内存\u顺序\u获取 具有此内存顺序的加载操作对受影响的内存位置执行获取操作:在此加载之前,当前线程中的内存访问不能重新排序。这可以
-
问题内容: 我无法通过实验进行检查,也无法从手册页中收集到它。 说我有两个过程,一个是将文件1从目录1移动(重命名)到目录2。假设正在运行的另一个进程同时将directory1和directory2的内容复制到另一个位置。复制是否可能以这种方式发生,即目录1和目录2都将显示文件1-即,目录1在移动之前被复制,目录2在移动之后被第一个进程复制。 基本上,rename()是原子系统调用吗? 谢谢 问题
-
问题内容: 参考以下链接:http : //docs.python.org/faq/library.html#what- kinds-of-global-value-mutation-are-thread- safe 我想知道以下情况: 在cPython中将保证是原子的。(x和y都是python变量) 问题答案: 让我们来看看: 它不会出现,他们是原子:x的和y的值可以被另一个线程之间改变字节码,
-
读了很多关于易失性、原子性和可见性的文章后,有一个问题仍然存在。以下跨线程工作,当更新/读取“B”时,“A”始终可见: 原子变量是独立的对象,这同样适用吗?下面的操作会起作用吗? 如果答案是否定的,那么扩展AtomicInteger类并在其中包含“a”就可以了,因为AtomicInteger包装了一个volatile。
-
问题内容: 我在使用MySQL 5.5.22的Django时遇到以下问题。 给定一个具有列ID,级别和存储为a11,a12,a21,a22的2x2矩阵的表,我具有以下行: 给定一个查询集qs,我进行以下更新: django为此生成以下查询(从db.connection.queries中获取该查询,为简洁起见,删除where子句): 然后,我的行如下所示: 对于任何一行,都应该为True,并且据此,
-
问题内容: 给定一个简化的表结构,如下所示: 我可以使用这样的子查询插入记录而不会导致竞争条件吗? 还是子查询不是原子的?我担心同时s获取相同的值,然后导致唯一约束冲突。 问题答案: 是的,这肯定可以创建竞争条件,因为尽管保证所有语句都是原子的,但这并不要求它们在查询执行的各个部分中对不变的数据集进行操作。 客户提交您的上述查询。只要引擎找到只持有与其他读取器兼容的锁的锁,则另一个客户端可以在执行