
Flink检查点会导致背压


我正在使用至少一次检查点模式,这应该是异步化进程。有人能建议吗?我的检查点设置
env.enableCheckpointing(1800000,
CheckpointingMode.AT_LEAST_ONCE);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig()
.enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig()
.setCheckpointTimeout(10min);
env.getCheckpointConfig()
.setFailOnCheckpointingErrors(
jobConfiguration.getCheckpointConfig().getFailOnCheckpointingErrors());
我的工作有128个容器。
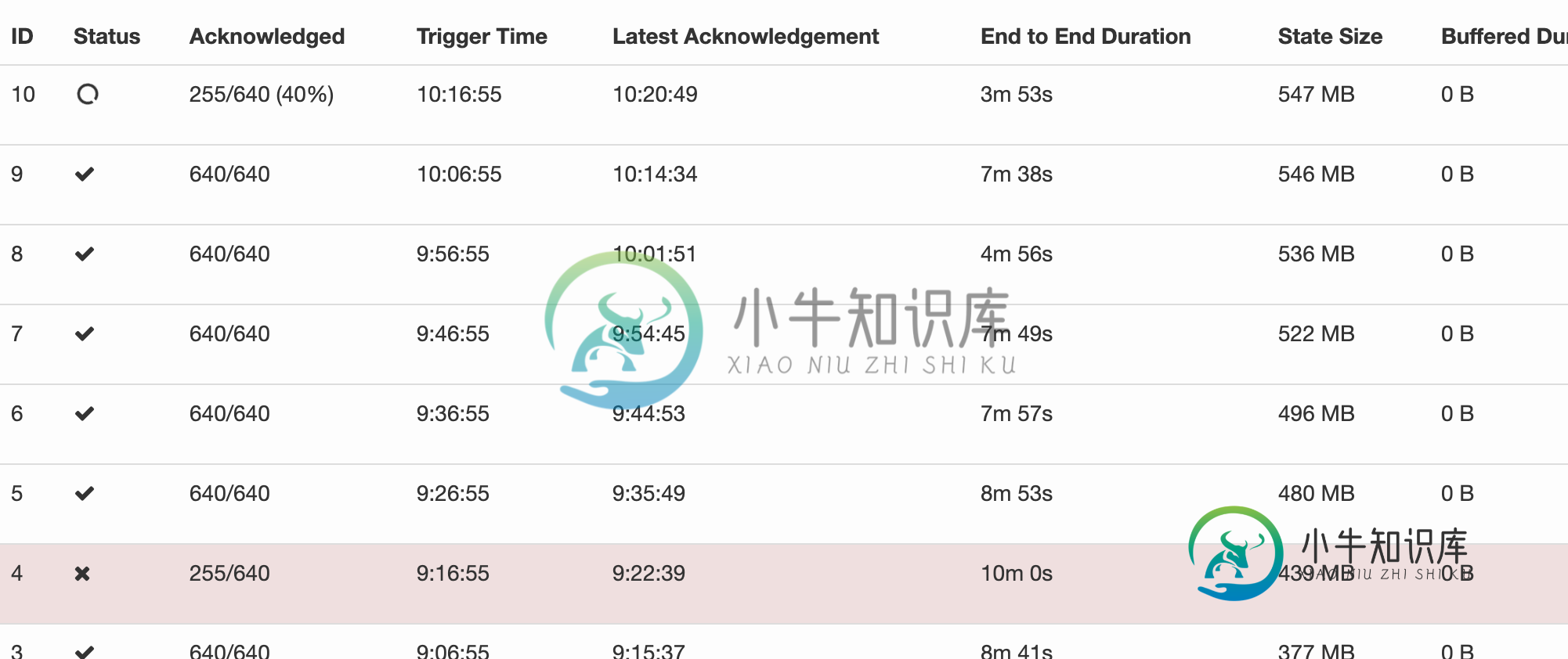
我想用一个30分钟的检查站看看


共有2个答案

任何类型的检查点都会增加计算开销。大多数检查点是异步的(如您所述),但它仍然会增加一般的I/O操作。例如,这些额外的I/O请求可能会阻塞您对外部系统的访问。此外,如果您启用检查点,Flink需要跟踪更多信息(新与已检查点)。
你是否试图为你的工作增加更多的资源?你能分享你的整个检查点配置吗?

太长,读不下去了有时很难分析这个问题。我有两个幸运的猜测/猜测-如果您使用的是RocksDB state backend,您可以切换到FSStateBend-它通常更快,RocksDB对于不适合内存的大状态大小最有意义(或者如果您确实需要增量检查点功能)。第二种是摆弄平行度,增加或减少。
我会怀疑@ArvidHeise写的同样的事情。检查点的大小不是很大,但也不是微不足道的。它可能会增加额外的开销,使工作超出勉强跟上流量的阈值,无法跟上并造成背压。如果您处于背压之下,延迟将不断累积,因此,即使额外开销的百分之几发生变化,也会在毫秒的端到端延迟与无限不断增长的值之间产生差异。
如果您不能简单地添加更多资源,那么您必须html" target="_blank">分析到底是什么增加了额外的资源,以及什么资源是瓶颈。
- 是CPU吗?检查群集上的CPU使用情况。如果是100%左右,这就是你需要优化的地方
- 是IO吗?检查集群上的IO使用情况,并将其与您可以实现的最大吞吐量/每秒请求数进行比较
- 如果两个CPU
在弄清楚瓶颈是什么资源后,下一个问题是为什么?一旦您看到它,它可能会立即显而易见,或者可能需要深入研究,例如检查GC日志、附加分析器等。
回答这些问题可以为您提供您可以在工作中尝试优化的信息,或者允许您调整配置,或者可以为我们(Flink开发人员)提供我们可以在Flink方面尝试优化的额外数据点。
-
下面是我对Flink的疑问。 我们可以将检查点和保存点存储到RockDB等外部数据结构中吗?还是只是我们可以存储在RockDB等中的状态。 状态后端是否会影响检查点?如果是,以何种方式? 什么是状态处理器API?它与我们存储的保存点和检查点直接相关吗?状态处理器API提供了普通保存点无法提供的哪些额外好处? 对于3个问题,请尽可能描述性地回答。我对学习状态处理器API很感兴趣,但我想深入了解它的应
-
我正在kubernetes中运行一个Flink作业。我的设置如下 1个作业管理器吊舱 我的flink作业从kafka源获取时间序列数据(时间、值),进行聚合和其他转换,并将其发布到kafka接收器。 有时,我的作业因检查点异常(10分钟后超时)而失败,主要是由一名操作员完成的。我不理解异步持续时间(在图中)的含义,为什么它花费的时间最长。在这个异常之前,Kafka的吞吐量非常高,有500-800万
-
我们正在尝试使用RocksDB后端设置Flink有状态作业。我们使用会话窗口,有30分钟的间隔。我们使用aggregateFunction,所以不使用任何Flink状态变量。通过采样,我们的事件数不到20k次/秒,新会话数不到20-30次/秒。我们的会议基本上收集了所有的事件。会话累加器的大小会随着时间而增大。我们总共使用了10G内存和Flink1.9,128个容器。以下是设置: 从我们对给定时间
-
我想在flink中使用aws s3作为数据流的接收器。我正在使用StreamingFileSink类创建一个接收器。 我的工作不需要检查点,但是当我禁用检查点时,数据不再写入S3。 案例1:启用检查点 启用检查点后,数据将成功摄取到提到的s3路径。 案例2:检查点禁用 禁用检查点时,数据不会写入s3。 我多次尝试执行作业,但每次都得到相同的结果。我在本地机器和kubernetes集群上都面临这个问
-
我有一份很轻松的工作,在创建检查站方面很吃力。它几乎没有州(除了一些Kafka偏移)。 工作本身有以下基本设置: Kafka索资源- 迭代函数再次执行HTTP调用并转发成功的消息,丢弃4xx并重试5xx。从我的指标中可以看到,所有这些都发生了,我得到了一些5xx(返回迭代源)、一些4xx(忽略)和很多2xx(转发到HDFS)。 如果我查看线程转储,我可以看到某个任务被阻止了: 这一个正在等待对象监
-
我有一个操作/方法来执行对数据库的插入。它需要几个字段,由于各种原因,操作可能会失败,因为一个或多个输入不是唯一的,或者因为它们与一些需要唯一的内部记录冲突。 反对这种方法的人指出,我们开发团队知道会导致失败的每个错误情况,应该返回错误代码并使用它来处理每个情况。 我看不出检查方法有任何明显的缺点。这些错误情况很有可能发生,您绝对必须在使用saveUserInfo()的任何地方解决它们。似乎正是为