
Flink检查点不断失败

我们正在尝试使用RocksDB后端设置Flink有状态作业。我们使用会话窗口,有30分钟的间隔。我们使用aggregateFunction,所以不使用任何Flink状态html" target="_blank">变量。通过采样,我们的事件数不到20k次/秒,新会话数不到20-30次/秒。我们的会议基本上收集了所有的事件。会话累加器的大小会随着时间而增大。我们总共使用了10G内存和Flink1.9,128个容器。以下是设置:
state.backend: rocksdb
state.checkpoints.dir: hdfs://nameservice0/myjob/path
state.backend.rocksdb.memory.managed: true
state.backend.incremental: true
state.backend.rocksdb.memory.write-buffer-ratio: 0.4
state.backend.rocksdb.memory.high-prio-pool-ratio: 0.1
containerized.heap-cutoff-ratio: 0.45
taskmanager.network.memory.fraction: 0.5
taskmanager.network.memory.min: 512mb
taskmanager.network.memory.max: 2560mb
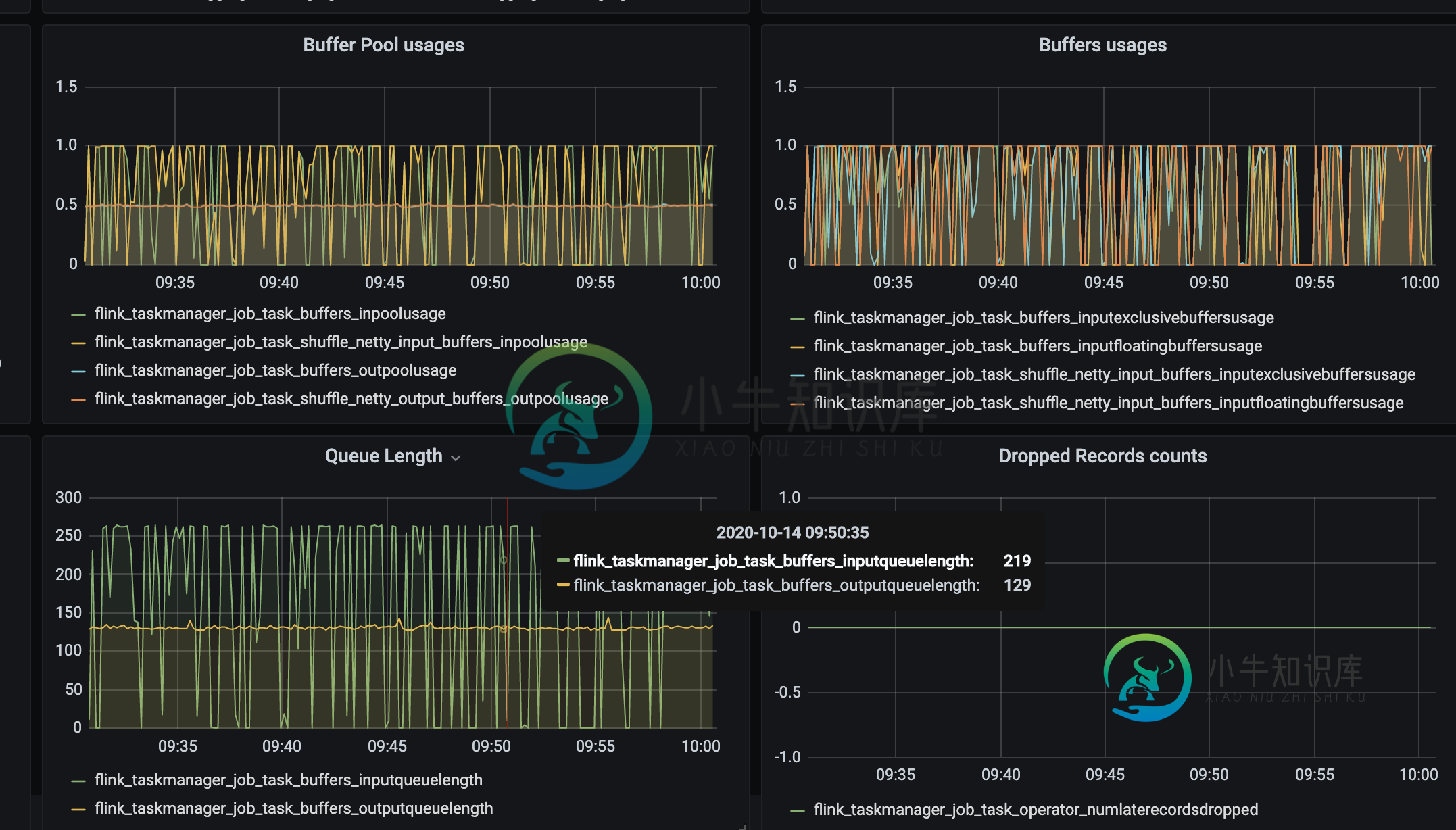
从我们对给定时间的监控来看,rocksdb可管理大小小于10M,我们的堆使用量小于1G,但是我们的直接内存使用量(网络缓冲区)在使用2.5G。缓冲池/缓冲区使用度量值均为1(满)。我们的检查点总是失败,我想知道网络缓冲区部分可能会占用这么多内存是正常的吗?
共有1个答案

值得注意的是,会话窗口确实在内部使用Flink状态。(大多数源和汇也是如此。)根据您将会话事件收集到会话累加器中的方式,这可能是一个性能问题。如果您需要将所有事件聚集在一起,为什么要使用AggregateFunction来完成这一操作,而不是让Flink为您完成这一操作?
为了获得最佳的窗口性能,您希望使用ReduceFunction或AggregateFunction来递增地缩小/聚合窗口,只保留一小部分最终将成为窗口结果的状态。另一方面,如果您只使用ProcessWindowFunction,而不使用预聚合,那么Flink将在内部使用一个附加列表状态对象,该对象与RocksDB一起使用时非常有效--它只需要序列化每个事件以将其附加到列表的末尾。当窗口最终被触发时,列表将作为一个以块形式反序列化的可迭代文件传递给您。另一方面,如果您使用AggregateFunction滚动您自己的解决方案,您可能会让RocksDB在每次访问/更新时反序列化和保留累加器。这可能会变得非常昂贵,并可能解释为什么检查点正在失败。
您分享的另一个有趣的事实是,缓冲池/缓冲区使用度量表明它们已被充分利用。这表明存在着巨大的背压,这反过来也解释了为什么检查点会失败。检查点依赖于检查点屏障能够遍历整个执行图,在每个操作符执行时对它们进行检查,并在超时前完成作业的全部扫描。如果有背压,这可能会失败。
-
我正在kubernetes中运行一个Flink作业。我的设置如下 1个作业管理器吊舱 我的flink作业从kafka源获取时间序列数据(时间、值),进行聚合和其他转换,并将其发布到kafka接收器。 有时,我的作业因检查点异常(10分钟后超时)而失败,主要是由一名操作员完成的。我不理解异步持续时间(在图中)的含义,为什么它花费的时间最长。在这个异常之前,Kafka的吞吐量非常高,有500-800万
-
下面是我对Flink的疑问。 我们可以将检查点和保存点存储到RockDB等外部数据结构中吗?还是只是我们可以存储在RockDB等中的状态。 状态后端是否会影响检查点?如果是,以何种方式? 什么是状态处理器API?它与我们存储的保存点和检查点直接相关吗?状态处理器API提供了普通保存点无法提供的哪些额外好处? 对于3个问题,请尽可能描述性地回答。我对学习状态处理器API很感兴趣,但我想深入了解它的应
-
我的工作流程工作原理如下: src[Kafka]- 但我的工作是运行精细的数据完美地流向Kafka和MySQL,但它在检查点失败,附加图像相同。 Ps :目前我已经禁用了检查点,但是当我使用相同的属性启用时,它会失败
-
主程序正在消费kafka事件,然后过滤- 但是我得到了以下例外: 以下是flink-conf.yaml中的一些配置 任何想法为什么会发生异常以及如何解决问题? 谢谢
-
我有一份很轻松的工作,在创建检查站方面很吃力。它几乎没有州(除了一些Kafka偏移)。 工作本身有以下基本设置: Kafka索资源- 迭代函数再次执行HTTP调用并转发成功的消息,丢弃4xx并重试5xx。从我的指标中可以看到,所有这些都发生了,我得到了一些5xx(返回迭代源)、一些4xx(忽略)和很多2xx(转发到HDFS)。 如果我查看线程转储,我可以看到某个任务被阻止了: 这一个正在等待对象监
-
我正在使用至少一次检查点模式,这应该是异步化进程。有人能建议吗?我的检查点设置 我的工作有128个容器。 我想用一个30分钟的检查站看看