
Kubernetes吊舱重启问题异常

我的Java微服务正在AWS EC2实例上托管的k8s集群中运行。
我有大约30个微服务(nodejs和Java8的良好组合)在K8s集群中运行。我面临一个挑战,我的java应用程序pods意外重启,导致应用程序5xx数量增加。
为了调试它,我在pod和应用程序中启动了一个newrelic代理,并找到了以下图表:
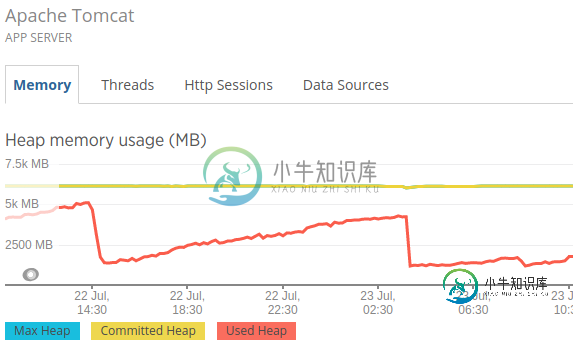
在我可以看到的地方,我的Xmx值为6GB,我的用途最大为5.2GB。
这清楚地表明JVM没有超过Xmx值。
但是当我描述pod并查找最后一个状态时,它显示“原因:错误”和“退出代码:137”

然后在进一步的调查中,我发现我的Pod平均内存使用量一直接近极限。(分配9Gib,使用约9Gib)。我无法理解为什么Pod中的内存使用率如此之高,即使我只有一个进程(JVM)在运行,而这也受到6Gib Xmx的限制。
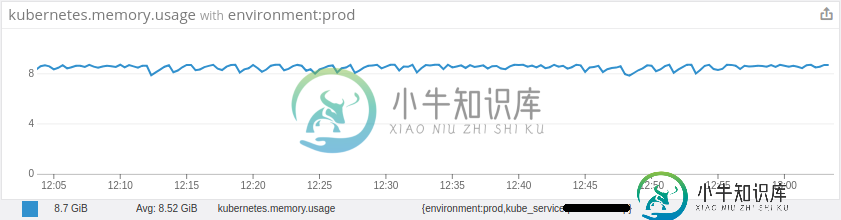
当我登录到我的工作节点并检查docker容器的状态时,我可以看到该通知的最后一个容器处于退出状态,并显示“容器退出,退出代码为非零137”
我可以看到wokernode内核日志如下:

这表明内核正在终止我在容器中运行的进程。
我可以看到我的工作节点中有很多可用内存。

我不知道为什么我的吊舱一次又一次地重新启动,这是k8s的行为还是我的基础设施中的一些令人毛骨悚然的东西。这迫使我再次将应用程序从容器移动到VM,因为这会导致5xx计数的增加。
编辑:在将内存增加到12GB后,我得到了OOM。

我不确定为什么POD会因为OOM而被杀死,因为JVM xmx只有6 GB。
需要帮助!
共有3个答案

在GCloud App Engine中,您可以指定最大CPU使用阈值,e.b.0.6。这意味着,如果CPU达到100%-60%的0.6%,将生成一个新实例。
我没有遇到这样的设置,但可能:Kubernetes吊舱/部署具有类似的配置参数。也就是说,如果POD的RAM达到100%的0.6%,则终止POD。在您的情况下,这将是9GB的60%=5GB。只是一些值得思考的东西。

由于您已将pod的最大内存使用量限制为9Gi,因此当内存使用量达到9Gi时,它将自动终止。

一些较旧的Java版本(Java8 u131版本之前)无法识别它们在容器中运行。因此,即使您使用-Xmx为JVM指定了最大堆大小,JVM也会根据主机的总内存而不是容器的可用存储器来设置最大堆大小,然后当进程尝试分配超过其限制(在pod/部署规范中定义)的内存时,您的容器就会被OOM杀死。
在K8集群中本地运行Java应用程序时,这些问题可能不会出现,因为pod内存限制和本地机器总内存之间的差异不大。但当您在具有更多可用内存的节点上在生产环境中运行它时,JVM可能会超过您的容器内存限制,并将被OOMKilled。
从Java 8(u131版本)开始,可以使JVM具有“容器意识”,以便它识别容器控制组(cgroups)设置的约束。
对于Java8(来自U131版本)和Java9,您可以将此实验标志设置为JVM:
-XX:+UnlockExperimentalVMOptions
-XX:+UseCGroupMemoryLimitForHeap
它将根据容器cgroup内存限制设置堆大小,该限制在pod/部署规范的容器定义部分中定义为“资源:限制”。在Java8中,JVM的堆外内存可能仍然会增加,因此您可能会监控它,但总的来说,这些实验标志也必须处理它。
从Java 10中,这些实验标志是新的默认标志,通过使用此标志启用/禁用:
-XX:+UseContainerSupport
-XX:-UseContainerSupport
-
我们正在使用Docker 1.19运行库伯内特斯(1.18) Container是一个基于Java13的Spring启动应用程序(使用基本图像作为openjdk: 13-alpin),下面是内存设置。 豆荚: 内存-最小448M,最大2500M cpu-最小值0.1 容器: Xms:256M,Xmx:512M 当流量发送更长时间时,容器会突然重新启动;在Prometheus中,我可以看到Pod内存
-
null null null > 将Kubernetes降级为。 使用重新初始化了Kubernetes,因为服务器有另一个外部IP,无法通过其他主机访问,而Kubernetes倾向于选择该IP作为API服务器IP。由Flannel授权。 初始化后没有连接节点的结果输出 看起来API服务器已按其应有的方式部署 然后我将法兰绒网络pod应用于
-
我对Kubernetes是新来的。 我发现了2个pod优先级选项-优先级类别和服务质量。它们之间有什么不同? (https://kubernetes.io/docs/concepts/configuration/pod-priority-preemption/https://kubernetes.io/docs/tasks/configure-pod-container/quality-servi
-
我的要求是在自定义指标上扩展POD,如队列中的挂起消息,PODS必须增加以处理作业。在kubernetes,Scale up在普罗米修斯适配器和普罗米修斯操作员中工作得很好。 我在pods中有长时间运行的进程,但HPA检查自定义度量并试图缩小规模,因为这个进程杀死了操作的中间并丢失了消息。我如何控制HPA只杀死没有进程运行的自由豆荚。 序列查询:‘{namespace=“default”,serv
-
我已经在节点(node1)上的pod(pod1)上部署了一个Spring Boot应用程序。我还在不同节点(node2)上的另一个pod(pod2)上部署了JMeter。我试图从POD2执行自动负载测试。为了执行负载测试,我要求为每个测试用例重新启动pod1。如何从POD2重新启动pod1?