
FireStore-io.grpc.statusException:failed_precondition:查询需要索引

我正在建设聊天应用程序与后端firestore数据库与下面的结构。
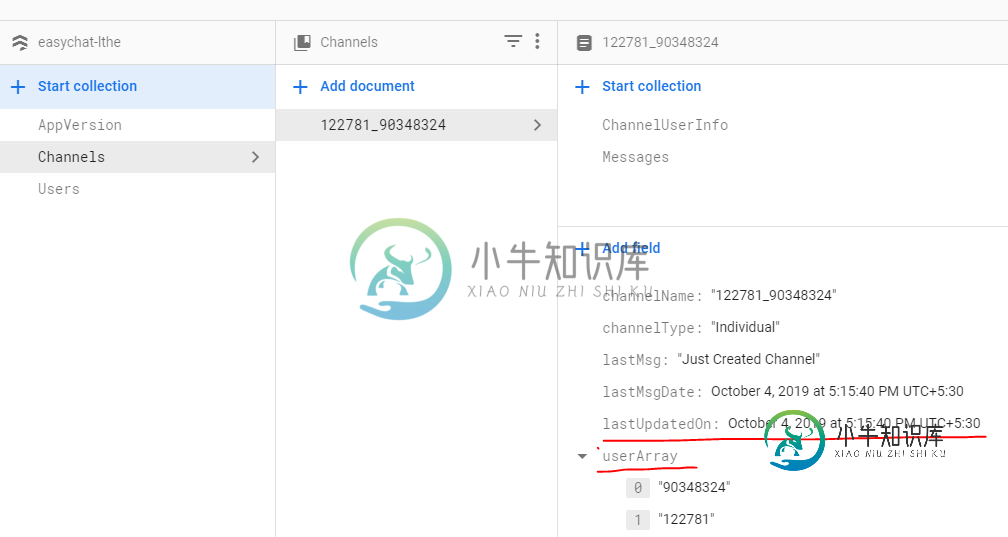
我正在获取下面提到的数据。它返回我的用户id在字段“UserArray”中涉及的通道列表,并根据给定的日期/时间获取“LASTUPDATEDON”数据。
registration = fireStoreDb.collection(clsUtility.RootCollections.Channels.toString())
.whereArrayContains("userArray", loggedInPsno)
.whereGreaterThanOrEqualTo("lastUpdatedOn", lastChannelUpdateDateTime)
.orderBy("lastUpdatedOn", Query.Direction.ASCENDING)
.addSnapshotListener((queryDocumentSnapshots, e) -> {
if (e != null) {
Log.w("loadUsers", "Listen failed.", e);
return;
}
在上面的例子中,它显示了我在android logcat中创建复合索引的错误。复合索引创建完成,但仍得到相同的错误消息。

共有1个答案

-
我在云Firestore里查询了一下, 我收到了错误,但我有一个索引。
-
我正在尝试搜索Spotify中的曲目元数据。我想看看Spotify是否有一首来自YouTube视频的歌曲。这是我用于进行搜索的URL模板: 由于很难确定搜索查询的哪一部分是艺术家还是曲目,因此我将这两种类型添加为搜索查询的类型。 然而,当我得到一个YouTube的视频,标题是这样的:“凯蒂·佩里——我们是这样做的(官方视频)[·莱特拉·西班牙语——歌词英语”,并将其用作我的搜索词时,我得到了0个结
-
根据firestore文档,我可以通过组合'>'和'<'查询来执行相当于‘!='的查询: 但我到底该怎么做呢?如果可能,请提供精确示例的代码(查询结果!=30)。
-
我正在尝试按文档 ID 查询火库集合,但不是使用火库 CLI,而是使用结构化查询(因为我使用 Zapier 来自动执行某些工作流)。有没有办法按记录为字段进行搜索?到目前为止,我已经尝试了下面的代码和变体,我将名称替换为“documentId()”,“文档Id”,但似乎没有任何效果。当我使用名称时,我得到以下错误: "error":"code": 400,"message":"key filter
-
我明白分区键对于可伸缩性和数据存储方式很重要。但是如果我们考虑搜索,分区键是不是有点像额外的filter/where子句?所有文档都被索引,所以我可以执行查询,如下所示: 在使用此SQL查询语法时,我是否还应该指定分区键,或者指出如何允许跨分区查询?
-
我收集了大约75000份文件。 数据库的总大小约为45GB 在75k个文档中,约45k个文档的大小分别为900 KB(约42 GB),其余文档的大小分别约为120 KB。 每个文档都映射到其他集合中的ObjectId,并具有一个,两者都已索引。 现在,我需要获取上个月特定客户ID的文档。数量约为5500份文件。这个custId包含大小约为120 KB的小文档。 以下是我的查询: 不过,查询需要2分