
Keras:微调初始化时精度下降

我很难用Keras微调Inception模型。
我已经成功地使用教程和文档生成了一个完全连接的顶层模型,该模型从一开始就使用瓶颈特性将我的数据集分类为适当的类别,准确率超过99%。
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dropout, Flatten, Dense
from keras import applications
# dimensions of our images.
img_width, img_height = 150, 150
#paths for saving weights and finding datasets
top_model_weights_path = 'Inception_fc_model_v0.h5'
train_data_dir = '../data/train2'
validation_data_dir = '../data/train2'
#training related parameters?
inclusive_images = 1424
nb_train_samples = 1424
nb_validation_samples = 1424
epochs = 50
batch_size = 16
def save_bottlebeck_features():
datagen = ImageDataGenerator(rescale=1. / 255)
# build bottleneck features
model = applications.inception_v3.InceptionV3(include_top=False, weights='imagenet', input_shape=(img_width,img_height,3))
generator = datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical',
shuffle=False)
bottleneck_features_train = model.predict_generator(
generator, nb_train_samples // batch_size)
np.save('bottleneck_features_train', bottleneck_features_train)
generator = datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical',
shuffle=False)
bottleneck_features_validation = model.predict_generator(
generator, nb_validation_samples // batch_size)
np.save('bottleneck_features_validation', bottleneck_features_validation)
def train_top_model():
train_data = np.load('bottleneck_features_train.npy')
train_labels = np.array(range(inclusive_images))
validation_data = np.load('bottleneck_features_validation.npy')
validation_labels = np.array(range(inclusive_images))
print('base size ', train_data.shape[1:])
model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:]))
model.add(Dense(1000, activation='relu'))
model.add(Dense(inclusive_images, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer='Adam',
metrics=['accuracy'])
proceed = True
#model.load_weights(top_model_weights_path)
while proceed:
history = model.fit(train_data, train_labels,
epochs=epochs,
batch_size=batch_size)#,
#validation_data=(validation_data, validation_labels), verbose=1)
if history.history['acc'][-1] > .99:
proceed = False
model.save_weights(top_model_weights_path)
save_bottlebeck_features()
train_top_model()
纪元50/50 1424/1424 [==============================] - 17s 12ms/步长-损耗:0.0398-acc:0.9909
我还能够将此模型堆叠在《盗梦空间》的顶部,以创建我的完整模型,并使用该完整模型成功地对我的培训集进行分类。
from keras import Model
from keras import optimizers
from keras.callbacks import EarlyStopping
img_width, img_height = 150, 150
top_model_weights_path = 'Inception_fc_model_v0.h5'
train_data_dir = '../data/train2'
validation_data_dir = '../data/train2'
#how many inclusive examples do we have?
inclusive_images = 1424
nb_train_samples = 1424
nb_validation_samples = 1424
epochs = 50
batch_size = 16
# build the complete network for evaluation
base_model = applications.inception_v3.InceptionV3(weights='imagenet', include_top=False, input_shape=(img_width,img_height,3))
top_model = Sequential()
top_model.add(Flatten(input_shape=base_model.output_shape[1:]))
top_model.add(Dense(1000, activation='relu'))
top_model.add(Dense(inclusive_images, activation='softmax'))
top_model.load_weights(top_model_weights_path)
#combine base and top model
fullModel = Model(input= base_model.input, output= top_model(base_model.output))
#predict with the full training dataset
results = fullModel.predict_generator(ImageDataGenerator(rescale=1. / 255).flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical',
shuffle=False))
对该完整模型处理结果的检查与生成的瓶颈完全连接模型的准确性相匹配。
import matplotlib.pyplot as plt
import operator
#retrieve what the softmax based class assignments would be from results
resultMaxClassIDs = [ max(enumerate(result), key=operator.itemgetter(1))[0] for result in results]
#resultMaxClassIDs should be equal to range(inclusive_images) so we subtract the two and plot the log of the absolute value
#looking for spikes that indicate the values aren't equal
plt.plot([np.log(np.abs(x)+10) for x in (np.array(resultMaxClassIDs) - np.array(range(inclusive_images)))])
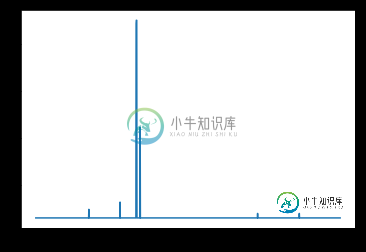
问题是:当我使用这个完整的模型并尝试对其进行训练时,即使验证保持在99%以上,精度也会下降到0。
model2 = fullModel
for layer in model2.layers[:-2]:
layer.trainable = False
# compile the model with a SGD/momentum optimizer
# and a very slow learning rate.
#model.compile(loss='binary_crossentropy', optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), metrics=['accuracy'])
model2.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
train_datagen = ImageDataGenerator(rescale=1. / 255)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='categorical')
callback = [EarlyStopping(monitor='acc', min_delta=0, patience=3, verbose=0, mode='auto', baseline=None)]
# fine-tune the model
model2.fit_generator(
#train_generator,
validation_generator,
steps_per_epoch=nb_train_samples//batch_size,
validation_steps = nb_validation_samples//batch_size,
epochs=epochs,
validation_data=validation_generator)
纪元1/50 89/89 [==============================] - 388秒4秒/步-损失: 13.5787-acc: 0.0000e 00-val_loss: 0.0353-val_acc: 0.9937
事情进展得越来越糟
纪元21/50 89/89[=====================]-372s 4s/步-损耗:7.3850-acc:0.0035-val\U损耗:0.5813-val\U acc:0.8272
我能想到的唯一一件事是,在这最后一列火车上,不知何故,培训标签被错误地分配了,但我以前使用VGG16成功地用类似的代码完成了这一点。
我搜索了代码,试图找到一个差异来解释为什么一个模型在99%以上的时间里做出准确的预测会降低其训练精度,同时在微调期间保持验证精度,但我无法弄清楚。任何帮助都将不胜感激。
有关代码和环境的信息:
有些事情会显得很奇怪,但注定是这样的:
- 每个类只有一个图像。此NN旨在对环境和方向条件受到控制的对象进行分类。它们对于每个类来说只有一个可接受的图像,对应于正确的环境和旋转情况。
- 测试和验证集是相同的。此NN仅html" target="_blank">设计用于它正在训练的类。它将处理的图像将是类示例的碳副本。我的意图是使模型过度适合这些类
我正在使用:
- Windows 10
- Anaconda客户端1.6.14下的Python 3.5.6
- Keras 2.2.2
- Tensorflow 1.10.0作为后端
- CUDA 9.0
- CuDNN 8.0
我已退房:
- 微调模型中的Keras精度差异
- VGG16 Keras微调:低精度
- Keras:模型精度达到99%后下降,损失0.01
- Keras inception v3再培训和微调错误
- 如何查找我的系统中安装了哪个版本的TensorFlow
但它们似乎无关。
共有2个答案

像前面的回答一样,我将尝试分享一些想法,看看它是否有帮助。
有几件事引起了我的注意(也许值得回顾)。注意:其中一些也应该给您单独模型的问题。
- 如果我错了,请更正,但似乎您在第一次训练中使用了
sparse_categorical_crossentropy,而在第二次训练中使用了categorical_crossentropy。正确吗?因为我相信他们假设标签不同(稀疏假设整数,另一个假设one-Hot)。 - 您是否尝试过将最终添加的层设置为
trainable=True?我知道您已经将其他层设置为trainable=False,但也许这也是值得检查的东西。 - 数据生成器似乎没有使用Incept v3中使用的默认预处理函数,该函数使用平均通道。
- 您是否尝试过使用FunctionalAPI而不是Sequential API进行任何实验?
我希望这有帮助。

注意:由于您的问题有点奇怪,并且在没有经过培训的模型和数据集的情况下很难调试,因此在考虑了许多可能出错的事情之后,这个答案只是一个(最佳)猜测。请提供您的反馈,如果不起作用,我将删除此答案。
由于inception_V3包含BatchNormize层,当您将trainable参数设置为False(1, 2, 3, 4)时,问题可能是由于该层的行为(不知何故含糊不清或意外)。
现在,让我们看看这是否是问题的根源:正如@fchollet所建议的,在定义模型进行微调时设置学习阶段:
from keras import backend as K
K.set_learning_phase(0)
base_model = applications.inception_v3.InceptionV3(weights='imagenet', include_top=False, input_shape=(img_width,img_height,3))
for layer in base_model.layers:
layer.trainable = False
K.set_learning_phase(1)
top_model = Sequential()
top_model.add(Flatten(input_shape=base_model.output_shape[1:]))
top_model.add(Dense(1000, activation='relu'))
top_model.add(Dense(inclusive_images, activation='softmax'))
top_model.load_weights(top_model_weights_path)
#combine base and top model
fullModel = Model(input= base_model.input, output= top_model(base_model.output))
fullModel.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
#####################################################################
# Here, define the generators and then fit the model same as before #
#####################################################################
旁注:这不会在您的情况下造成任何问题,但请记住,当您使用顶部模型(基本模型.输出)时,整个顺序模型(即顶部模型)存储为完整模型的一层。您可以使用fullModel验证这一点。summary()或打印(fullModel.layers[-1])。因此,当您使用:
for layer in model2.layers[:-2]:
layer.trainable = False
您实际上也没有冻结base_model的最后一层。但是,由于它是Concatenate层,因此没有可训练的参数,因此不会出现问题,它会按照您的预期运行。
-
问题内容: 我有数千个音频文件,我想使用Keras和Theano对它们进行分类。到目前为止,我为每个音频文件生成了一个28x28的声谱图(可能更大一些,但我现在只是想让算法起作用),然后将图像读入矩阵。因此,最终我得到了这个大图像矩阵,以馈入网络进行图像分类。 在一个教程中,我找到了这个mnist分类代码: 此代码运行,并且我得到预期的结果: 到现在为止,一切都运行良好,但是,当我将上述算法应用于
-
本文向大家介绍keras之权重初始化方式,包括了keras之权重初始化方式的使用技巧和注意事项,需要的朋友参考一下 在神经网络训练中,好的权重 初始化会加速训练过程。 下面说一下kernel_initializer 权重初始化的方法。 不同的层可能使用不同的关键字来传递初始化方法,一般来说指定初始化方法的关键字是kernel_initializer 和 bias_initializer 几种初始化
-
我使用velocity作为Java代码生成器,我正在运行一个Eclipse应用程序,它有多个插件,不同的插件调用velocity模块进行代码生成。 每当我运行一个特定的插件时,不管我运行多少次,它都可以单独工作,现在如果我试图运行另一个插件,它会抛出速度异常(我在下面提供了堆栈跟踪),我将再次重启eclipse,其他插件也可以工作。 结论:当一个插件在某个插件已经执行后运行时,Velocity初始
-
我是kubernetes的新手,正在尝试配置kubernetes主节点,我已经安装了kubeadm、kubectl和kubelet,如下所示 https://kubernetes.io/docs/setup/independent/create-cluster-kubeadm/ 但是当我尝试通过键入 kubeadm 时,它会给我以下错误
-
Initialization 初始化 Although it doesn’t look superficially very different from initialization in C or C++, initialization in Go is more powerful. Complex structures can be built during initialization a
-
初始化是为类、结构体或者枚举准备实例的过程。这个过需要给实例里的每一个存储属性设置一个初始值并且在新实例可以使用之前执行任何其他所必须的配置或初始化。 你通过定义初始化器来实现这个初始化过程,它更像是一个用来创建特定类型新实例的特殊的方法。不同于 Objective-C 的初始化器,Swift 初始化器不返回值。这些初始化器主要的角色就是确保在第一次使用之前某类型的新实例能够正确初始化。 类类型的