
为LSTM整形数据,并将密集层的输出输入LSTM

我正试图找出适合我所尝试的模型的正确语法。这是一个时间序列预测问题,我想在将时间序列输入LSTM之前,使用几个密集层来改进时间序列的表示。
下面是我正在处理的一个虚拟系列:
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
import numpy as np
import keras as K
import tensorflow as tf
d = pd.DataFrame(data = {"x": np.linspace(0, 100, 1000)})
d['l1_x'] = d.x.shift(1)
d['l2_x'] = d.x.shift(2)
d.fillna(0, inplace = True)
d["y"] = np.sin(.1*d.x*np.sin(d.l1_x))*np.sin(d.l2_x)
plt.plot(d.x, d.y)

首先,我将拟合一个前面没有密集层的LSTM。这需要我重塑数据:
X = d[["x", "l1_x", "l2_x"]].values.reshape(len(d), 3,1)
y = d.y.values
这是正确的吗?
这些教程使得单个时间序列的第一维度应该是1,然后是时间步数(1000),然后是协变量数(3)。但当我这样做时,模型就无法编译。
在这里,我编译并训练模型:
model = K.Sequential()
model.add(K.layers.LSTM(10, input_shape=(X.shape[1], X.shape[2]), batch_size = 1, stateful=True))
model.add(K.layers.Dense(1))
callbacks = [K.callbacks.EarlyStopping(monitor='loss', min_delta=0, patience=5, verbose=1, mode='auto', baseline=None, restore_best_weights=True)]
model.compile(loss='mean_squared_error', optimizer='rmsprop')
model.fit(X, y, epochs=50, batch_size=1, verbose=1, shuffle=False, callbacks = callbacks)
model.reset_states()
yhat = model.predict(X, 1)
plt.clf()
plt.plot(d.x, d.y)
plt.plot(d.x, yhat)
为什么我不能让模型过拟合??是因为我重塑了我的数据吗?当我在LSTM中使用更多节点时,它并没有真正变得更加过拟合。
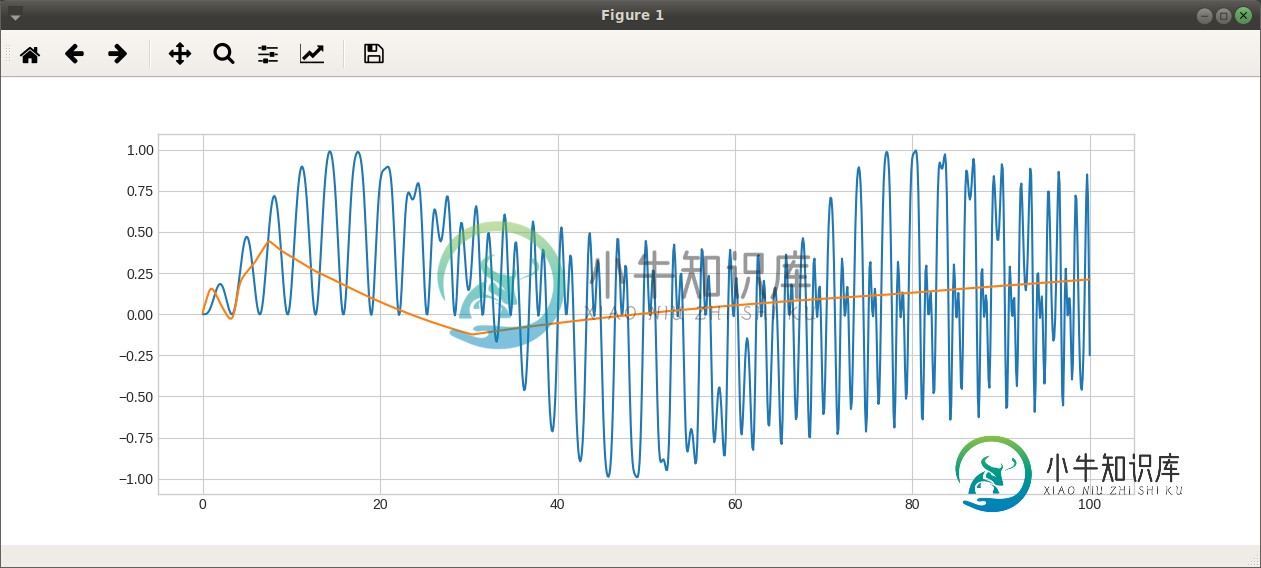
(我也不清楚“有状态”是什么意思。神经网络只是非线性模型。“状态”指的是哪些参数,为什么要重置它们?)
如何在输入和LSTM之间插入密集层?最后,我想添加一组密集层,在到达LSTM之前,基本上在x上进行基展开。但LSTM需要一个3D阵列,而密集层则会生成一个矩阵。我在这里做什么?这不起作用:
model = K.Sequential()
model.add(K.layers.Dense(10, activation = "relu", input_dim = 3))
model.add(K.layers.LSTM(3, input_shape=(10, X.shape[2]), batch_size = 1, stateful=True))
model.add(K.layers.Dense(1))
ValueError: Input 0 is incompatible with layer lstm_2: expected ndim=3, found ndim=2
共有1个答案

对于第一个问题,我正在做同样的事情,我没有得到任何错误,请分享您的错误。
注意:我将为您提供使用函数式API的示例,它几乎没有更多的自由度(个人观点)
from keras.layers import Dense, Flatten, LSTM, Activation
from keras.layers import Dropout, RepeatVector, TimeDistributed
from keras import Input, Model
seq_length = 15
input_dims = 10
output_dims = 8
n_hidden = 10
model1_inputs = Input(shape=(seq_length,input_dims,))
model1_outputs = Input(shape=(output_dims,))
net1 = LSTM(n_hidden, return_sequences=True)(model1_inputs)
net1 = LSTM(n_hidden, return_sequences=False)(net1)
net1 = Dense(output_dims, activation='relu')(net1)
model1_outputs = net1
model1 = Model(inputs=model1_inputs, outputs = model1_outputs, name='model1')
## Fit the model
model1.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_11 (InputLayer) (None, 15, 10) 0
_________________________________________________________________
lstm_8 (LSTM) (None, 15, 10) 840
_________________________________________________________________
lstm_9 (LSTM) (None, 10) 840
_________________________________________________________________
dense_9 (Dense) (None, 8) 88
_________________________________________________________________
对于你的第二个问题,有两种方法:
- 如果您在发送数据时未按顺序进行排序(dims为
(batch,input\u dims)),则可以使用此方法RepeatVector,它通过n\u步重复相同的权重,这只不过是LSTM中的滚动步
{
seq_length = 15
input_dims = 16
output_dims = 8
n_hidden = 20
lstm_dims = 10
model1_inputs = Input(shape=(input_dims,))
model1_outputs = Input(shape=(output_dims,))
net1 = Dense(n_hidden)(model1_inputs)
net1 = Dense(n_hidden)(net1)
net1 = RepeatVector(3)(net1)
net1 = LSTM(lstm_dims, return_sequences=True)(net1)
net1 = LSTM(lstm_dims, return_sequences=False)(net1)
net1 = Dense(output_dims, activation='relu')(net1)
model1_outputs = net1
model1 = Model(inputs=model1_inputs, outputs = model1_outputs, name='model1')
## Fit the model
model1.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_13 (InputLayer) (None, 16) 0
_________________________________________________________________
dense_13 (Dense) (None, 20) 340
_________________________________________________________________
dense_14 (Dense) (None, 20) 420
_________________________________________________________________
repeat_vector_2 (RepeatVecto (None, 3, 20) 0
_________________________________________________________________
lstm_14 (LSTM) (None, 3, 10) 1240
_________________________________________________________________
lstm_15 (LSTM) (None, 10) 840
_________________________________________________________________
dense_15 (Dense) (None, 8) 88
=================================================================
{
seq_length = 15
input_dims = 10
output_dims = 8
n_hidden = 10
lstm_dims = 6
model1_inputs = Input(shape=(seq_length,input_dims,))
model1_outputs = Input(shape=(output_dims,))
net1 = TimeDistributed(Dense(n_hidden))(model1_inputs)
net1 = LSTM(output_dims, return_sequences=True)(net1)
net1 = LSTM(output_dims, return_sequences=False)(net1)
net1 = Dense(output_dims, activation='relu')(net1)
model1_outputs = net1
model1 = Model(inputs=model1_inputs, outputs = model1_outputs, name='model1')
## Fit the model
model1.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_17 (InputLayer) (None, 15, 10) 0
_________________________________________________________________
time_distributed_3 (TimeDist (None, 15, 10) 110
_________________________________________________________________
lstm_18 (LSTM) (None, 15, 8) 608
_________________________________________________________________
lstm_19 (LSTM) (None, 8) 544
_________________________________________________________________
dense_19 (Dense) (None, 8) 72
=================================================================
注意:我堆叠了两层,在这样做的时候,在第一层我使用了return_sequence,它返回每个时间步的输出,这是由第二层使用的,它只在最后返回输出time_step。
-
问题内容: 我正在尝试为我要适应的模型找出正确的语法。这是一个时间序列预测问题,在将其输入LSTM之前,我想使用一些密集层来改善时间序列的表示形式。 这是我正在使用的虚拟系列: 首先,我将安装没有密集层的LSTM。这要求我重塑数据: 这个对吗? 这些教程使单个时间序列在第一个维度上应该具有1,然后是时间步数(1000),然后是协变量数(3)。但是,当我这样做时,模型无法编译。 在这里,我编译并训练
-
问题内容: 我有一个由 N = 4000个样本 组成的数据集X ,每个样本都包含 d = 2个特征 (连续值),这些特征跨越 t = 10个时间步长 。在时间步骤11,我还具有每个样本的相应“标签”,它们也是连续值。 目前,我的数据集的形状为X:[4000,20],Y:[4000]。 给定d个功能的10个先前输入,我想使用TensorFlow训练LSTM来预测Y值(回归),但是我在TensorFl
-
问题内容: 我正在尝试使用Keras实施LSTM。 我知道Keras中的LSTM需要3D张量与形状作为输入。但是,我不能完全确定输入在我的情况下的样子,因为我对每个输入只有一个观察样本,而不是多个样本,即。将我的每个输入分成长度样本是否更好?对我而言,大约有几百万个观测值,因此在这种情况下,每个样本应保留多长时间,即我将如何选择? 另外,我是对的,这个张量应该看起来像: 其中M和N如前所述,x对应
-
问题内容: 我正在尝试构建LSTM模型,以解决https://keras.io/layers/recurrent/中的文档示例 以下三行代码(加上注释)直接来自上面的文档链接: ValueError:输入0与层lstm_2不兼容:预期ndim = 3,找到的ndim = 2 在执行第二个model.add()语句之后,但在将模型暴露给我的数据甚至编译它之前,我在上面得到了该错误。 我在这里做错了什
-
我正在开发一款使用强化学习的赛车游戏。为了训练模型,我在实现神经网络时面临一个问题。我找到了一些使用CNN的例子。但似乎添加额外的LSTM层将提高模型效率。我找到了以下示例。 https://team.inria.fr/rits/files/2018/02/ICRA18_EndToEndDriving_CameraReady.pdf 我需要实施的网络 问题是我不确定如何在这里实现LSTM层。我如何
-
嘿,伙计们,我已经建立了一个有效的LSTM模型,现在我正在尝试(不成功)添加一个嵌入层作为第一层。 这个解决方案对我不起作用。在提问之前,我还阅读了这些问题:Keras输入解释:输入形状、单位、批次大小、尺寸等,了解Keras LSTM和Keras示例。 我的输入是一种由27个字母组成的语言的字符的单键编码(1和0)。我选择将每个单词表示为10个字符的序列。每个单词的输入大小是(10,27),我有