
对于前一层的每个信道,一个卷积滤波器总是具有不同的系数吗?

例如,我们有3个通道(红色、绿色、蓝色)的RGB图像。我们使用卷积神经网络。
每个卷积滤波器是否总是对图像的每个通道(R、G、B)具有3个不同的系数?
>
即filter-W1是否有3个不同的系数矩阵:W1[::0],W1[::1],W1[::2]如下图所示?
或者在现代神经网络的一个滤波器中经常使用相同的系数(<代码>W1[::0]=W1[::1]=W1[::2] )?
链接:http://cs231n.github.io/convolutional-networks/
此外:http://cs231n.github.io/convolutional-networks/#conv
卷积层
。。。
沿深度轴的连接范围始终等于输入体积的深度。在我们如何处理空间维度(宽度和高度)和深度维度时,必须再次强调这种不对称性:连接在空间上是局部的(沿宽度和高度),但总是沿着输入体积的整个深度。
共有1个答案

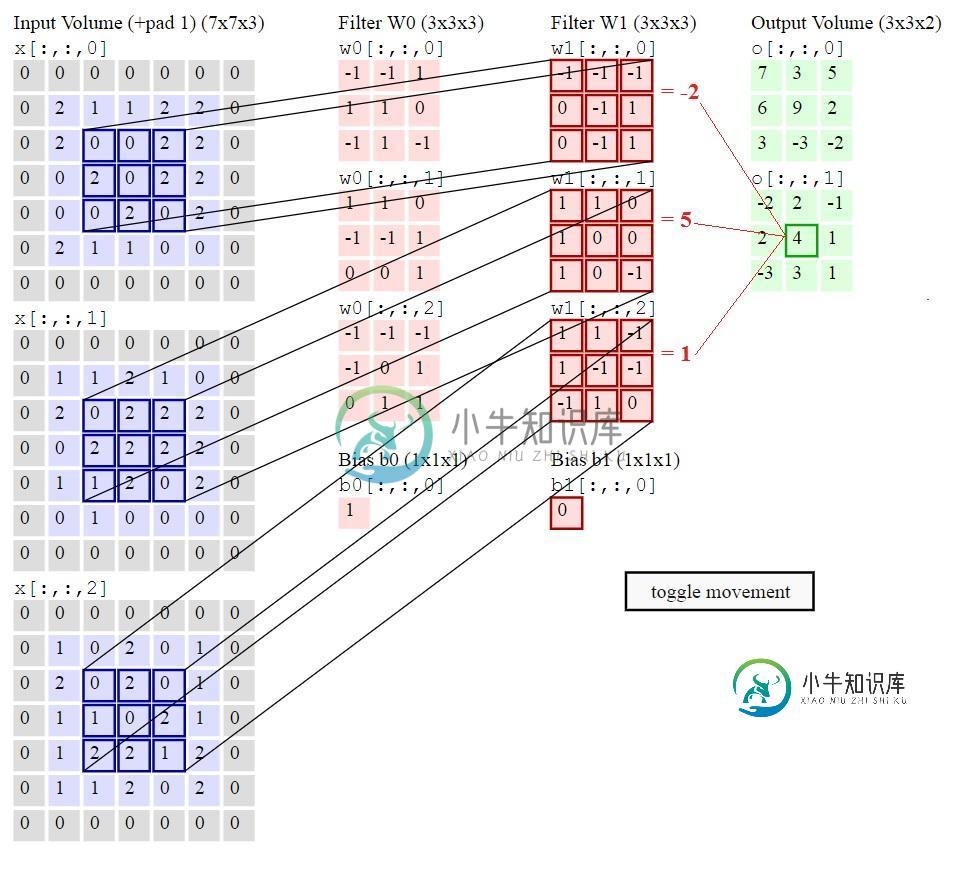
这里表示的是第一个隐藏的(这里是卷积层)。每个过滤器都有3个通道,因为您的输入(对于该层,您的图像)有3个通道(RGB)。导致您连接的2个特征映射(这解释了(3x3)x2大小的输出卷)。
更一般地说,对于大小为(1x)WxHxC的输入(为简单起见,让我们考虑批大小为1),每个过滤器的大小将为NxNxC(为简单起见,让我们考虑跨距为1和“相同”的填充,即使对于您的示例,它是“有效”的填充),因此对于F过滤器,您的输出大小将为(1x)WxHxF。
希望它足够清楚(例如W=H=7,C=3,N=3和F=2)。
如果不够清楚,请随时发表评论:)
-
我问了一个关于我上周建立的一个网络的问题,我重复了一些建议,这些建议导致我发现了一些问题。我回到这个项目,解决了所有问题,并在这个过程中了解了更多关于CNN的信息。现在我陷入了一个问题:我所有的权重都变成了巨大的负值,再加上输出图像中的RELU端总是完全是黑色的(这使得分类器无法完成它的工作)。 在两个标记的图像上: 这些数据被传递到一个两层网络、一个分类器(它自己获得100%)和一个单过滤器3×
-
我正在从事一个语义分割项目,该项目涉及动态过滤器,以学习多尺度表示。 为了创建这些过滤器,我使用Unet主干并从瓶颈层提取特征图。特征图的大小为H x W X 512,其中H是特征图的高度,W是宽度,512是通道(图)的数量。 这些特征被传递到1x1卷积,以将滤波器的数量减少到H X W X 128,并且这些特征也被传递到自适应池层,以将H X W X 512减少到k X k X 512,其中k是
-
我在keras建立了一个ConvNet,这是其中的两层 第一层大小的输出,我完全理解,因为有8个大小为3x3的过滤器,每个过滤器都被应用于生成单独的特征图,因此 第二层的输出大小为24x24x16,我不理解。由于第二层的每个过滤器将作用于第一层输出的每个特征映射,因此输出的大小不应该是24x24x128吗? 基本上,我不明白一层的输出是如何馈送到另一层的输入的
-
该脚本可以在几分钟内在 CPU 上运行完。 结果示例: from __future__ import print_function import time import numpy as np from PIL import Image as pil_image from keras.preprocessing.image import save_img from keras import la
-
我正在构建一个卷积网络图像分类的目的,我的网络受到VGG conv网络的启发,但我更改了每层的层数和过滤器,因为我的图像数据集非常简单。 然而,我想知道为什么VGG中的Fitler数总是2:64的幂- 我猜这是因为每个池将输出大小除以2 x 2,因此需要将过滤器的数量乘以2。 但我仍然想知道,这一选择背后的真正原因是什么;这是为了优化吗?分配计算是否更容易?我应该在我的人际网络中保持这种逻辑吗。
-
我正在实现一个三维卷积神经网络,我有两个问题。 问题一 每个输入是一个大小为(201,10,4)的3D矩阵。我希望我的过滤器能够在第二和第三维度上移动,因为它们是完全连接的。第三个维度是特征维度。所以我不想看第二和第三维度的当地社区。因此,我的过滤器大小将是例如(3,10,4)的大小。所以过滤器大小等于第二和第三维度,但我们在第一维度中有权重共享。以下是我的卷积代码: 所以我应该在这里使用步幅,这