
IText使用XML Worker防止跨多个页面的行中断

我们将iText 5.5.7与XML Worker一起使用,在长表中遇到了一个问题,即从页面末尾流出的行被拆分为两行,然后再转到下一页(见图)。
我们尝试在内部使用分页符:避免 如HTML表格中PDF页面之间使用iText、XMLWorker和iText在文本块中防止分页符中建议的那样,但没有效果。
我们已经试过了
- 将每一行包装在
中
我们的印象是支持page-bling-在里面:避免,但尚未看到对此的确认。是否有使用XML工作器创建此效果的示例或最佳实践,或者是否需要Javaapi来执行此级别的操作?
干杯
当前跨页面拆分的行:
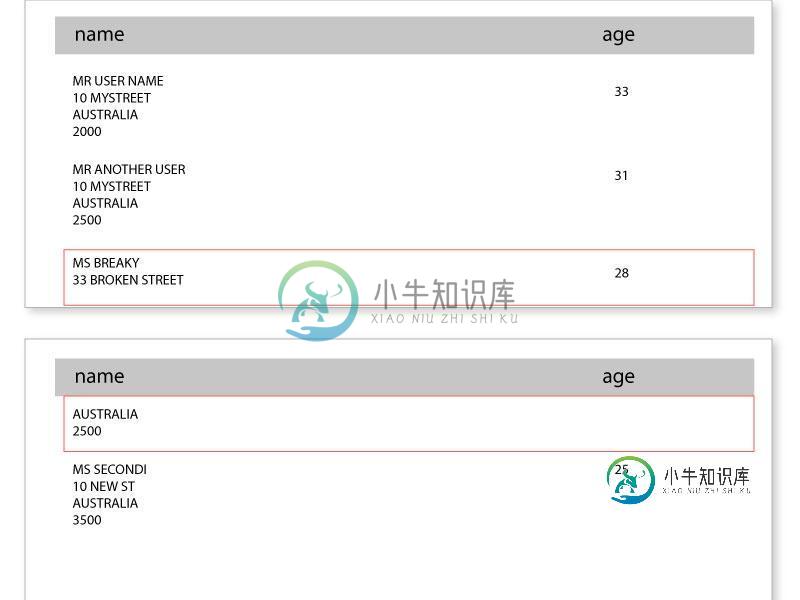

共有1个答案

。NET开发人员,但您应该能够轻松地翻译以下C#代码。
每当默认的XML Worker实现不能满足您的需求时,您基本上就只能进行查看源代码的练习。首先,查看XML Worker是否支持您在Tags类中想要的标签。有一个很好的实现
如果不支持该标记,则需要通过继承AbstractTagProcessor来滚动您自己的自定义标记处理器,但不要去那里获取这个答案。
不管怎样,继续代码。我们可以使用自定义的超文本标记语言属性并拥有两全其美的效果,而不是通过更改page-bling-inter:避免样式的行为来破坏默认实现:
public class TableProcessor : Table
{
// custom HTML attribute to keep <tr> on same page if possible
public const string NO_ROW_SPLIT = "no-row-split";
public override IList<IElement> End(IWorkerContext ctx, Tag tag, IList<IElement> currentContent)
{
IList<IElement> result = base.End(ctx, tag, currentContent);
var table = (PdfPTable)result[0];
if (tag.Attributes.ContainsKey(NO_ROW_SPLIT))
{
// if not set, table **may** be forwarded to next page
table.KeepTogether = false;
// next two properties keep <tr> together if possible
table.SplitRows = true;
table.SplitLate = true;
}
return new List<IElement>() { table };
}
}
以及生成一些test超文本标记语言的简单方法:
public string GetHtml()
{
var html = new StringBuilder();
var repeatCount = 15;
for (int i = 0; i < repeatCount; ++i) { html.Append("<h1>h1</h1>"); }
var text = "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Integer vestibulum sollicitudin luctus. Curabitur at eros bibendum, porta risus a, luctus justo. Phasellus in libero vulputate, fermentum ante nec, mattis magna. Nunc viverra viverra sem, et pulvinar urna accumsan in. Quisque ultrices commodo mauris, et convallis magna. Duis consectetur nisi non ultrices dignissim. Aenean imperdiet consequat magna, ac ornare magna suscipit ac. Integer fermentum velit vitae porttitor vestibulum. Morbi iaculis sed massa nec ultricies. Aliquam efficitur finibus dolor, et vulputate turpis pretium vitae. In lobortis lacus diam, ut varius tellus varius sed. Integer pulvinar, massa quis feugiat pulvinar, tortor nisi bibendum libero, eu molestie est sapien quis odio. Lorem ipsum dolor sit amet, consectetur adipiscing elit.";
// default iTextSharp.tool.xml.html.table.Table (AbstractTagProcessor)
// is at the <table>, **not <tr> level
html.Append("<table style='page-break-inside:avoid;'>");
html.AppendFormat(
@"<tr><td style='border:1px solid #000;'>DEFAULT IMPLEMENTATION</td>
<td style='border:1px solid #000;'>{0}</td></tr>",
text
);
html.Append("</table>");
// overriden implementation uses a custom HTML attribute to keep:
// <tr> together - see TableProcessor
html.AppendFormat("<table {0}>", TableProcessor.NO_ROW_SPLIT);
for (int i = 0; i < repeatCount; ++i)
{
html.AppendFormat(
@"<tr><td style='border:1px solid #000;'>{0}</td>
<td style='border:1px solid #000;'>{1}</td></tr>",
i, text
);
}
html.Append("</table>");
return html.ToString();
}
最后,解析代码:
using (var stream = new FileStream(OUTPUT_FILE, FileMode.Create))
{
using (var document = new Document())
{
PdfWriter writer = PdfWriter.GetInstance(
document, stream
);
document.Open();
// instantiate custom tag processor and add to `HtmlPipelineContext`.
var tagProcessorFactory = Tags.GetHtmlTagProcessorFactory();
tagProcessorFactory.AddProcessor(
new TableProcessor(),
new string[] { HTML.Tag.TABLE }
);
var htmlPipelineContext = new HtmlPipelineContext(null);
htmlPipelineContext.SetTagFactory(tagProcessorFactory);
var pdfWriterPipeline = new PdfWriterPipeline(document, writer);
var htmlPipeline = new HtmlPipeline(htmlPipelineContext, pdfWriterPipeline);
var cssResolver = XMLWorkerHelper.GetInstance().GetDefaultCssResolver(true);
var cssResolverPipeline = new CssResolverPipeline(
cssResolver, htmlPipeline
);
var worker = new XMLWorker(cssResolverPipeline, true);
var parser = new XMLParser(worker);
using (var stringReader = new StringReader(GetHtml()))
{
parser.Parse(stringReader);
}
}
}
完整来源。
默认实现被维护-first
自定义实现在第二个
-
我正在为一个项目评估itext,该项目将动态生成的HTML文档转换为pdf文档。XMLWorker完全符合要求。当我的HTML文档包含中文/韩文等字符时,我遇到了问题。 我听说在Itext中,我们可以使用字体而不嵌入它们。我看过FontSelector的例子,FontSelector使我们能够在不嵌入字体的情况下使用字体。生成的pdf提示从adobe网站下载语言包,这就是我想要的。 但我不确定这对
-
我知道如何生成单个超文本标记语言页面。我想知道如何从多个超文本标记语言页面生成的pdf生成单个pdf页面。 例如,有和另一个文件我可以生成单独的pdf文件和分别来自html。我可以将它们写入文件系统,然后像iTextConcatenate示例中那样连接它们。 我只是想知道我是否可以在不将它们写入文件系统的情况下动态地组合此操作。我无法识别丢失的链接
-
问题内容: 我们正在使用iText从Java代码生成PDF文件,该文件在大多数情况下效果很好。几天前,我们开始生成PDF / A,而不是需要嵌入所有字体的普通PDF文件。iText 主要是自定义类和其他类的构建,在这些类中我们直接控制字体。所有使用的字体都是通过通过以下代码加载的TTF文件创建的- 效果很好: 现在,我们在使用HTML代码生成的PDF中使用一种特定的内容类型。我们使用来处理该部分。
-
本文向大家介绍一个页面引用多个文件,如何防止样式冲突?相关面试题,主要包含被问及一个页面引用多个文件,如何防止样式冲突?时的应答技巧和注意事项,需要的朋友参考一下 编码层面: 1、定制规则:不同的样式文件表,增加不同的前缀。 2、按照功能区分文件:不同的文件样式表,针对页面不同的部分写样式,通过样式层级的方式,确认样式的边界。(例如header部分:#header p { },footer部分:#
-
问题内容: 我希望在后台使用jQuery作为“心跳”进行AJAX调用,以便我的Web应用程序可以检查新数据。例如,每10秒。 我在其他帖子上看到,可以使用调用每X毫秒进行一次调用的方法。 但是,如果我的AJAX通话时间超过10秒怎么办?我仍然希望它完成上一个请求,并且当正在进行中的一个请求时,我不希望发出另一个呼叫。这可能导致相同的信息两次被放置到页面上! 当我的方法等待原始AJAX调用完成时,而