
了解lfence对具有两个长依赖链的循环的影响,以增加长度

我在玩这个答案中的代码,稍微修改一下:
BITS 64
GLOBAL _start
SECTION .text
_start:
mov ecx, 1000000
.loop:
;T is a symbol defined with the CLI (-DT=...)
TIMES T imul eax, eax
lfence
TIMES T imul edx, edx
dec ecx
jnz .loop
mov eax, 60 ;sys_exit
xor edi, edi
syscall
如果没有lfence,我得到的结果与该答案中的静态分析一致。
当我引入单个函数时,我希望CPU执行第k次迭代的imul edx,edx序列,与下一次(k 1次)迭代的imul eax,eax序列并行
类似这样的操作(调用A的imul eax,eax序列和D的imul edx,edx序列):
|
| A
| D A
| D A
| D A
| ...
| D A
| D
|
V time
采取或多或少相同的周期数,但对于一个不成对的并行执行。
当我使用taskset-c 2 ocperf测量原始版本和修改版本的周期数时。py stat-r 5-e循环:u’-x’/main-$T用于以下范围内的
T Cycles:u Cycles:u Delta
lfence no lfence
10 42047564 30039060 12008504
15 58561018 45058832 13502186
20 75096403 60078056 15018347
25 91397069 75116661 16280408
30 108032041 90103844 17928197
35 124663013 105155678 19507335
40 140145764 120146110 19999654
45 156721111 135158434 21562677
50 172001996 150181473 21820523
55 191229173 165196260 26032913
60 221881438 180170249 41711189
65 250983063 195306576 55676487
70 281102683 210255704 70846979
75 312319626 225314892 87004734
80 339836648 240320162 99516486
85 372344426 255358484 116985942
90 401630332 270320076 131310256
95 431465386 285955731 145509655
100 460786274 305050719 155735555
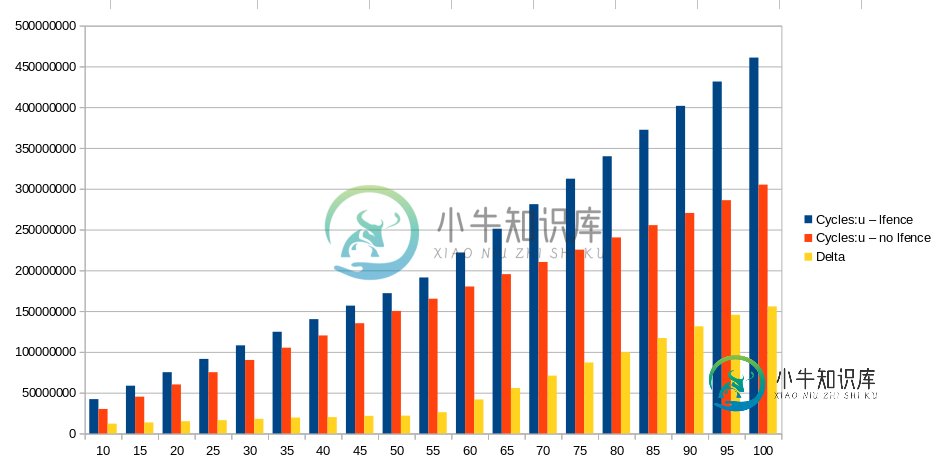
如何解释Cycle: u l栏的值?
我本以为它们会与Cycle: u no l栏的值相似,因为单个l栏应该只防止两个块并行执行第一次迭代。
我不认为这是由于l栏开销,因为我认为这应该是所有Ts的常量。
我想纠正我的表单在处理代码静态分析时的错误。
使用源文件支持存储库。
共有2个答案

匿名用户
我将对两个代码的T=1的情况进行分析(有和没有lford)。然后,您可以将其扩展为T的其他值。您可以参考英特尔优化手册的图2.4了解视觉效果。
因为只有一个容易预测的分支,所以只有在后端暂停时,前端才会暂停。Haswell的前端宽度为4,这意味着最多可以从IDQ(指令解码队列,它只是一个按顺序保存融合域uop的队列,也称为uop队列)向调度器的保留站(RS)实体发出4个融合uop。每个imul都被解码为一个无法融合的uop。指令包括ecx指令和jnz指令。循环在前端将宏融合到单个uop。微融合和宏融合之间的区别之一是,当调度器将一个宏融合uop(非微融合)分派给它分配给的执行单元时,它将作为单个uop进行分派。相比之下,微流量uop需要拆分为其组成uop,每个uop必须单独分派给执行单元。(然而,微喷UoP的拆分发生在RS入口处,而非发货时,请参见@Peter的答案中的脚注2)<代码>lfence被解码为6个UOP。识别微融合只在后端起作用,在这种情况下,循环中没有微融合。
由于循环分支很容易预测并且迭代次数相对较大,我们可以在不影响准确性的情况下假设分配器始终能够在每个周期分配4个uops。换句话说,调度程序将在每个周期收到4个uops。由于没有微融合,每个uop都将作为单个uop调度。
imul只能由慢速Int执行单元执行(见图2.4)。这意味着执行imul UOP的唯一选择是将其发送到端口1。在Haswell中,Slow Int被很好地管道化,因此每个周期可以调度一个imul。但乘法结果需要三个周期才能用于任何需要的指令(写回阶段是管道调度阶段的第三个周期)。因此,对于每个依赖链,每3个周期最多可以调度一个imul。
由于预计将采用dec/jnz,因此唯一可以执行它的执行单元是端口6上的主分支。
因此,在任何给定周期,只要RS有空间,它将接收4个UOP。但什么样的UOP?让我们在没有lfence的情况下检查循环:
imul eax, eax
imul edx, edx
dec ecx/jnz .loop (macrofused)
有两种可能性:
- 来自同一迭代的两个imul,来自相邻迭代的一个imul,以及来自这两个迭代之一的一个dec/jnz
- 一次迭代产生一个dec/jnz,下一次迭代产生两个imul,同一次迭代产生一个dec/jnz
因此,在任何循环开始时,RS将从每条链接收至少一个dec/jnz和至少一个imul。同时,在同一周期内,调度程序将从RS中已有的UOP中执行以下两个操作之一:
- 将最旧的dec/jnz发送到端口6,并将最旧的imul发送到端口1。总共是2个计量单位
- 由于慢速Int的延迟为3个周期,但只有两条链,因此对于3个周期的每个周期,RS中的任何imul都不会准备好执行。然而,RS中始终至少有一个dec/jnz,因此调度器可以调度它。总共是1个uop
现在,我们可以计算在任何给定周期N结束时,RS中的预期UOP数量XN:
XN=XN-1(在周期N开始时在RS中分配的UOP数量)-(在周期N开始时将调度的UOP的预期数量)
=XN-14-(0 1)*1/3(1 1)*2/3)
=X=X
复发的初始条件是X0=4。这是一个简单的递归,可以通过展开XN-1来解决。
XN=4 2.3*N,对于所有N
Haswell中的RS有60个条目。我们可以确定RS预计将变满的第一个周期:
60=4 7/3*N
N=56/2.3=24.3
因此,在周期24.3结束时,RS预计会已满。这意味着在周期25.3开始时,RS将无法接收任何新的uops。现在,正在考虑的迭代次数I决定了您应该如何进行分析。由于依赖链至少需要3*I周期才能执行,因此需要大约8.1次迭代才能达到周期24.3。因此,如果迭代次数大于8.1,这里就是这种情况,您需要分析周期24.3之后会发生什么。
调度器每个周期按以下速率发送指令(如上所述):
1
2
2
1
2
2
1
2
.
.
但分配器不会在RS中分配任何UOP,除非至少有4个可用条目。否则,它不会在以次优吞吐量发布UOP时浪费电力。然而,只有在每4个周期开始时,RS中才有至少4个可用条目。因此,从周期24.3开始,分配器预计每4个周期中会有3个停止。
对所分析代码的另一个重要观察是,可以调度的UOP从来不会超过4个,这意味着每个周期离开其执行单元的UOP的平均数量不超过4个。最多可以从再订购缓冲区(ROB)中停用4个UOP。这意味着ROB永远不会走上关键的道路。换句话说,性能由调度吞吐量决定。
我们现在可以很容易地计算IPC(每个周期的指令数)。ROB条目如下所示:
imul eax, eax - N
imul edx, edx - N + 1
dec ecx/jnz .loop - M
imul eax, eax - N + 3
imul edx, edx - N + 4
dec ecx/jnz .loop - M + 1
右侧的列显示了指令可以失效的周期。退役是按顺序发生的,并且受到关键路径延迟的限制。这里,每个依赖链都有相同的路径长度,因此都构成了两条长度为3个周期的相等关键路径。因此,每3个周期,就有4条指令可以失效。因此,IPC为4/3=1.3,CPI为3/4=0.75。这比理论上的最佳IPC 4小得多(即使不考虑微观和宏观融合)。因为退休是按顺序发生的,所以退休行为将是相同的。
我们可以使用perf和IACA检查我们的分析。我将讨论perf。我有一个Haswell CPU。
perf stat -r 10 -e cycles:u,instructions:u,cpu/event=0xA2,umask=0x10,name=RESOURCE_STALLS.ROB/u,cpu/event=0x0E,umask=0x1,cmask=1,inv=1,name=UOPS_ISSUED.ANY/u,cpu/event=0xA2,umask=0x4,name=RESOURCE_STALLS.RS/u ./main-1-nolfence
Performance counter stats for './main-1-nolfence' (10 runs):
30,01,556 cycles:u ( +- 0.00% )
40,00,005 instructions:u # 1.33 insns per cycle ( +- 0.00% )
0 RESOURCE_STALLS.ROB
23,42,246 UOPS_ISSUED.ANY ( +- 0.26% )
22,49,892 RESOURCE_STALLS.RS ( +- 0.00% )
0.001061681 seconds time elapsed ( +- 0.48% )
有100万次迭代,每次大约需要3个周期。每次迭代包含4条指令,IPC为1.33<代码>资源暂停。ROB显示由于ROB满而导致分配器暂停的周期数。这当然不会发生<代码>UOPS\U发布。任何都可以用来计算发给RS的UOP数量和分配器暂停的周期数(无具体原因)。第一种方法很简单(在性能输出中未显示);100万*3=300万小噪音。后者更有趣。它显示,大约73%的时间分配程序由于完全的RS而停止,这与我们的分析相匹配<代码>资源暂停。RS统计分配程序因RS满而暂停的周期数。这接近发出的UOPS\U。任何,因为分配器不会因任何其他原因暂停(尽管由于某种原因,差异可能与迭代次数成正比,但我必须查看
如果在两个imul之间添加了一个lfence,则可以扩展对没有lfence的代码的分析,以确定会发生什么。让我们先检查一下性能结果(很遗憾,IACA不支持lfence):
perf stat -r 10 -e cycles:u,instructions:u,cpu/event=0xA2,umask=0x10,name=RESOURCE_STALLS.ROB/u,cpu/event=0x0E,umask=0x1,cmask=1,inv=1,name=UOPS_ISSUED.ANY/u,cpu/event=0xA2,umask=0x4,name=RESOURCE_STALLS.RS/u ./main-1-lfence
Performance counter stats for './main-1-lfence' (10 runs):
1,32,55,451 cycles:u ( +- 0.01% )
50,00,007 instructions:u # 0.38 insns per cycle ( +- 0.00% )
0 RESOURCE_STALLS.ROB
1,03,84,640 UOPS_ISSUED.ANY ( +- 0.04% )
0 RESOURCE_STALLS.RS
0.004163500 seconds time elapsed ( +- 0.41% )
观察到循环数增加了大约1000万,即每次迭代增加10个循环。循环数并不能告诉我们太多。退役指令的数量增加了一百万,这是意料之中的。我们已经知道lford不会使指令更快完成,因此RESOURCE_STALLS. ROB不应该改变。UOPS_ISSUED. ANY和RESOURCE_STALLS. RS特别有趣。在这个输出中,UOPS_ISSUED. ANY计算循环,而不是uops。也可以计算uops的数量(使用cpu/event=0x0E, umask=0x1, name=UOPS_ISSUED. ANY/u而不是cpu/event=0x0E, umask=0x1, cMAC=1, inv=1, name=UOPS_ISSUED. ANY/u)并且每次迭代增加了6个uops(没有融合)。这意味着放置在两个imuls之间的lford被解码为6个uops。现在价值一百万美元的问题是这些uops做什么以及它们如何在管道中移动。
RESOURCE_STALLS. RS为零。这是什么意思?这表明分配器,当它在IDQ中看到l栏时,它会停止分配,直到ROB中所有当前的uops退休。换句话说,分配器不会分配RS中超过l栏的条目,直到l栏退休。由于循环正文仅包含3个其他uops,因此60个条目的RS永远不会满。事实上,它总是几乎是空的。
IDQ实际上并不是一个简单的队列。它由多个可以并行运行的硬件结构组成。l栏需要的uops数量取决于IDQ的确切设计。分配器也由许多不同的硬件结构组成,当它看到IDQ的任何结构的前面都有一个l栏uops时,它会暂停该结构的分配,直到ROB为空。因此不同的uops用于不同的硬件结构。
已发布UOPS\U。ANY显示分配器在每次迭代大约9-10个周期内没有发出任何UOP。这里发生了什么?lfence的一个用途是,它可以告诉我们一条指令退役并分配下一条指令需要多长时间。以下汇编代码可用于执行此操作:
TIMES T lfence
对于T的小值,性能事件计数器将不能很好地工作。对于足够大的T,并且通过测量UOPS_ISSUED. ANY,我们可以确定需要大约4个周期来停用每个l栏。这是因为UOPS_ISSUED. ANY将每5个周期增加大约4次。因此,在每4个周期之后,分配器发出另一个l栏(它不会停止),然后再等待另外4个周期,依此类推。也就是说,根据指令的不同,产生结果的指令可能需要1个或几个周期才能停用。IACA总是假设需要5个周期才能停用一条指令。
我们的循环如下所示:
imul eax, eax
lfence
imul edx, edx
dec ecx
jnz .loop
在lfence边界的任何循环中,ROB将包含以下从ROB顶部开始的指令(最旧的指令):
imul edx, edx - N
dec ecx/jnz .loop - N
imul eax, eax - N+1
其中,N表示调度相应指令的周期数。要完成的最后一条指令(到达写回阶段)是imul eax,eax。这发生在循环n4。在周期N 1、N 2、N 3和N 4期间,分配器暂停周期计数将增加。然而,在imul eax、eax失效之前,它将再进行大约5个周期。此外,在失效后,分配器需要清理IDQ中的lfence UOP,并分配下一组指令,然后才能在下一个周期中调度它们。性能输出告诉我们,每次迭代大约需要13个周期,并且分配器在这13个周期中暂停了10个周期(由于性能不足)。
问题中的图表仅显示了T=100的循环次数。然而,此时还有另一个(最终)膝盖。因此,最好绘制T=120的循环以查看完整的模式。

我认为你测量得很准确,解释是微观建筑,而不是任何测量误差。
我认为您对中低T的结果支持这样的结论,即l栏甚至会阻止前端发出超过l栏的指令,直到所有早期指令退出,而不是让所有来自两个链的uops已经发出,只是等待l栏翻转开关并让每个链的乘数开始在交替循环中调度。
(如果lfence没有阻塞前端,并且开销不会随着时间的推移而增加,那么对于Skylake的3c延迟/1c吞吐量乘数,port1将立即获得edx、eax、empty、edx、eax、empty等。)
当调度程序中只有来自第一条链的UOP时,您将失去imul吞吐量,因为前端尚未完成imul edx、edx和循环分支。对于窗口末端的相同循环次数,当管道大部分排空且仅剩下第二条链的UOP时。
开销增量看起来是线性的,最高约为T=60。我没有运行这些数字,但是T*0.25时钟发出第一条链与3c延迟执行瓶颈的斜率看起来是合理的。即增量增长速度可能是无栅栏周期总数的1/12。
因此(考虑到我在下面测量的开销),T
no_lfence cycles/iter ~= 3T # OoO exec finds all the parallelism
lfence cycles/iter ~= 3T + T/4 + 9.3 # lfence constant + front-end delay
delta ~= T/4 + 9.3
@Margaret报告说,T/4比2*T/4更适合,但我预计T/4在开始和结束时都会出现,因为三角洲的总坡度为2T/4。
在大约T=60之后,增量增长得更快(但仍然是线性的),斜率大约等于总无lfence周期,因此每T约3c。我认为在这一点上,调度程序(保留站)的大小限制了无序窗口。您可能在Haswell或Sandybridge/IvyBridge上进行了测试(分别有60个条目或54个条目的调度程序。Skylake的是97个条目(但没有完全统一;IIRC BeeOnRope的测试表明,并非所有条目都可以用于任何类型的uop。例如,有些条目特定于加载和/或存储)
RS跟踪未执行的uops。每个RS条目都包含1个未融合的域uop,它正在等待其输入准备就绪,以及它的执行端口,然后才能调度和离开RS1。
在一次失效后,前端每时钟发出4条指令,而后端每3个时钟执行1条指令,在大约15个周期内发出60个UOP,在此期间,仅执行了来自edx链的5条imul指令。(此处没有加载或存储微熔合,因此前端的每个熔合域uop在RS中仍然只有1个未熔合域uop)
对于大T,RS会很快填满,此时前端只能以后端的速度前进。(对于小T,我们在它发生之前先进行下一次迭代的lfence,这就是前端停滞的原因)。当T
请记住,从第一节开始,仅在执行第一个链之后所花费的时间=仅在执行第二个链之前所花费的时间。这在这里也适用。
对于T,即使没有lfence,我们也会得到一些这种效果
ROB和寄存器文件不应该在这种假设情况或您的真实情况下限制乱序窗口大小(http://blog.stuffedcow.net/2013/05/measuring-rob-capacity/)。它们都应该很大。
阻塞前端是Intel uarches上lfence的一个实现细节。手册只说以后的指令不能执行。这种措辞将允许前端在lfence仍在等待的情况下,将它们全部发布/重命名到调度程序(预留站)和ROB中,只要没有一个被调度到执行单元。
因此,较弱的lfence可能会有平坦的开销,直到T=RS\U大小,然后与您现在看到的T的斜率相同
请注意,关于在lfence之后推测执行条件/间接分支的保证适用于执行,而不是(据我所知)代码获取。仅仅触发代码提取对幽灵或熔毁攻击(AFAIK)没有用处。可能是一个用于检测其解码方式的定时侧通道可以告诉您有关获取的代码的信息。。。
我认为,当相关的MSR启用时,AMD的LFENCE至少在实际的AMD CPU上同样强大。(LFENCE是否在AMD处理器上序列化?)。
您的结果很有趣,但我一点也不惊讶,lfence本身(对于小t)以及随t扩展的组件都有显著的恒定开销。
请记住,在早期指令退出之前,lford不允许稍后的指令启动。这可能比它们的结果准备好绕过转发到其他执行单元时至少晚了几个周期/管道阶段(即正常延迟)。
因此,对于小T,通过要求结果不仅要准备好,还要写回寄存器文件,在链中添加额外的延迟,这无疑是非常重要的。
在检测到之前的最后一条指令失效后,可能需要一个额外的周期左右,才能允许发布/重命名阶段再次开始运行。发布/重命名过程需要多个阶段(周期),可能会在这一阶段开始时阻止lfence,而不是在UOP添加到核心OoO部分之前的最后一步。
根据Agner Fog的测试,即使是背靠背的lford本身在SnB系列上也有4个循环吞吐量。Agner Fog报告了2个融合域uops(没有未融合的),但在Skylake上,如果我只有1个lford,我将其测量为6个融合域(仍然没有未融合的)。但是背靠背的lford越多,它的uops就越少!通过许多背靠背,每个lford下降到约2个uops,这就是Agner的测量方式。
lfence在SKL上每10个周期运行1次,因此我们可以了解lfence在没有前端和RS完全瓶颈的情况下给dep链增加的真正额外延迟。
仅使用一个dep链测量开销,OoO exec不相关:
.loop:
;mfence ; mfence here: ~62.3c (with no lfence)
lfence ; lfence here: ~39.3c
times 10 imul eax,eax ; with no lfence: 30.0c
; lfence ; lfence here: ~39.6c
dec ecx
jnz .loop
如果没有lford,则以预期的30.0c/iter运行。使用lford,每iter运行约39.3c,因此lford有效地为关键路径dep链添加了约9.3c的“额外延迟”。(和6个额外的融合域uops)。
如果在imul链之后,就在循环分支之前,使用lford,它会稍微慢一点。但不是整个周期都慢,因此这表明前端在lford允许执行恢复后在单个问题组中发出循环分支和imul。既然如此,IDK为什么它更慢。它不是来自分支未命中。
按照程序顺序交错链,就像注释中的@BeeOnRope建议的那样,利用ILP不需要无序执行,所以这非常简单:
.loop:
lfence ; at the top of the loop is the lowest-overhead place.
%rep T
imul eax,eax
imul edx,edx
%endrep
dec ecx
jnz .loop
您可以将成对的短乘以8 imul链放入%rep中,让OoO exec轻松执行。
我的心理模型是前端的问题/重命名/分配阶段同时为RS和ROB添加新的uops。
UOP在执行后离开RS,但留在ROB,直到订单退役。ROB可能很大,因为它从未无序扫描以查找第一个准备就绪的uop,而扫描只是为了检查最旧的uop是否已完成执行,从而准备退役。
(我假设ROB在物理上是一个带有开始/结束索引的循环缓冲区,而不是一个实际上在每个周期向右复制uops的队列。但请将其视为具有固定最大大小的队列/列表,其中前端在前端添加uops,并且退休逻辑从末尾退休/提交uops,只要它们被完全执行,直到每个周期每个超线程退休限制,这通常不是瓶颈。Skylake确实增加了它以获得更好的超线程,可能每个逻辑线程每个时钟8个。也许退休也意味着释放物理寄存器,这有助于HT,因为当两个线程都处于活动状态时,ROB本身是静态分区的。这就是为什么退休限制是每个逻辑线程的原因。)
诸如nop、xor eax、eax或lfence之类的UOP(在前端处理)(在任何端口上不需要任何执行单元)仅在已执行状态下添加到ROB。(一个ROB条目可能有一个位标记它已准备就绪,而不是仍在等待执行完成。这就是我所说的状态。对于确实需要执行端口的UOP,我假设ROB位是通过执行单元的完成端口设置的。相同的完成端口信号释放其RS条目。)
Uops从发行到退休都留在ROB。
UOP从发布到执行都在RS中。在少数情况下,RS可以重播UOP,例如,对于缓存线拆分负载的另一半,或者如果它是在预期负载数据到达的情况下调度的,但事实上它没有重播UOP。(缓存未命中或其他冲突,如IvyBridge上指针跟踪循环中附近依赖存储的奇怪性能影响。添加额外负载会加快速度?)或者,当加载端口推测它可以在开始TLB查找之前绕过AGU,以小偏移量缩短指针跟踪延迟时,如果基偏移量位于与基偏移量不同的页面中,是否会受到惩罚?
所以我们知道RS不能在调度时删除uop权限,因为它可能需要重播。(甚至可能发生在消耗负载数据的非加载uops上。)但是任何需要重播的猜测都是短期的,不是通过一系列uops,所以一旦结果从执行单元的另一端出来,uop就可以从RS中删除。这可能是完成端口的一部分,以及将结果放在旁路转发网络上。
TL:DR:P6-家族:RS已熔断,SnB-家族:RS未熔断。
微熔合uop针对Sandybridge系列中的两个单独的RS条目发布,但只有一个ROB条目。(假设它在发布前未进行分层,请参阅《英特尔优化手册》第2.3.5节中的HSW或第2.4.2.4节中的SnB以及微融合和寻址模式。Sandybridge系列更紧凑的uop格式不能在所有情况下表示ROB中的索引寻址模式。)
加载可以在ALU uop的其他操作数准备就绪之前独立分派。(或对于微熔合存储,存储地址或存储数据UOP中的任何一个都可以在其输入就绪时进行调度,而无需等待两者。)
我使用问题中的双dep链方法在Skylake(RS size=97)上进行了实验测试,使用微融合的或edi,[rdi]vs.mov或,以及rsi中的另一条dep链。(完整测试代码,戈德博尔特上的NASM语法)
; loop body
%rep T
%if FUSE
or edi, [rdi] ; static buffers are in the low 32 bits of address space, in non-PIE
%else
mov eax, [rdi]
or edi, eax
%endif
%endrep
%rep T
%if FUSE
or esi, [rsi]
%else
mov eax, [rsi]
or esi, eax
%endif
%endrep
查看每个周期的uops_executed.thread(未融合域)(或perf为我们计算的每秒),我们可以看到不依赖于单独负载与折叠负载的吞吐量。
在小T(T=30)的情况下,所有ILP都可以利用,并且我们在有或没有微融合的情况下,每个时钟可以获得约0.67个UOP。(我忽略了dec/jnz每个循环迭代额外1个uop的小偏差。与微熔合uop仅使用1个RS条目的效果相比,这可以忽略不计)
请记住,load或是2个UOP,我们有2个dep链在运行中,因此这是4/6,因为或edi,[rdi]有6个周期延迟。(不是5,令人惊讶的是,见下文。)
在T=60时,对于保险丝=0,每个时钟仍有约0.66个未熔合UOP执行,对于保险丝=1,每个时钟仍有0.64个未熔合UOP执行。我们仍然可以找到基本上所有的ILP,但它只是刚刚开始下降,因为两条dep链的长度为120 UOP(而RS的大小为97)。
在T=120时,对于保险丝=0,每个时钟有0.45个未熔合UOP,对于保险丝=1,每个时钟有0.44个未熔合UOP。我们肯定已经超过膝盖了,但仍能找到一些ILP。
如果一个微融合的uop只需要1个RS入口,FUSE=1 T=120应该与FUSE=0 T=60的速度大致相同,但事实并非如此。相反,FUSE=0或1在任何T上几乎没有区别。(包括较大的T=200:FUSE=0:0.395 uops/时钟,FUSE=1:0.391 uops/时钟)。在我们开始飞行1 dep链的时间之前,我们必须先去非常大的T,才能完全控制飞行2的时间,并降低到0.33 uops/时钟(2/6)。
奇怪的是:我们在熔合和未熔合的吞吐量上有如此小但仍然可以测量的差异,单独的mov加载速度更快。
其他奇怪之处:在任何给定的T上,FUSE=0的总uops_executed.thread略低。就像2,418,826,591与T=60的2,419,020,155。这种差异可以重复到2.4G中的-60k,足够精确。FUSE=1在总时钟周期中较慢,但大部分差异来自每个时钟较低的uops,而不是更多的uops。
像rdi这样的简单寻址模式应该只有4个周期的延迟,所以加载ALU应该只有5个周期。但我测量了6个周期的延迟,用于加载使用延迟(rdi)或rdi,或单独的MOV加载,或任何其他ALU指令,我无法将加载部分设置为4c。
当dep链中有ALU指令时,像rdi rbx 2064这样的复杂寻址模式具有相同的延迟,因此似乎只有当一个负载转发到另一个负载的基址寄存器时(位移高达0..2047且无索引),Intel的4c简单寻址模式延迟才适用。
指针跟踪非常常见,因此这是一种有用的优化,但我们需要将其视为一种特殊的加载转发快速路径,而不是一种通用的数据,可以更快地供ALU指令使用。
P6系列不同:RS条目包含融合域uop。
@Hadi发现了2002年的英特尔专利,图12显示了融合域中的RS。
在Conroe(first gen Core2Duo,E6600)上进行的实验测试表明,T=50时,保险丝=0和保险丝=1之间存在很大差异。(RS大小为32个条目)。
>
T=50保险丝=1:2.346G循环的总时间(0.44IPC)
T=50保险丝=0:3.272G周期的总时间(0.62IPC=0.31负载或每个时钟)。(perf/ocperf.py在Nehalem之前的uarches上没有执行uops\U的事件,并且我没有在该机器上安装oprofile。)
T=24保险丝=0和保险丝=1之间的差别可以忽略不计,约为0.47 IPC vs 0.9 IPC(约0.45负载或每个时钟)。
T=24仍然是循环中超过96字节的代码,对于Core 2的64字节(预解码)循环缓冲区来说太大了,所以它不会更快,因为它适合循环缓冲区。没有uop缓存,我们不得不担心前端,但我认为我们很好,因为我只使用2字节的单uop指令,它应该可以在每个时钟4个融合域uop下轻松解码。
-
考虑以下java代码: 此代码输出“”。所以是64字节,而SHA-256是32字节哈希。 我知道我指定了512位(64字节)作为密钥长度 然而,我希望生成的密钥(PBKDF2)将由SHA-256进行散列,这样无论我使用的密钥大小如何,输出都应始终为32字节。 我错过了什么(或者为什么我的期望是错误的)?
-
我知道循环依赖通常是不被鼓励的——然而,在C#和TypeScript中,我有时发现它们很有用。这可能是因为我缺乏python方面的经验,也可能是因为我的思维方式不对,或者是因为我没有找到谷歌应该使用的词语。我将如何解决以下问题? 我试图创建一个处理请求的类,每个处理事件都伴随着一个上下文。所以,我想创建handler类和context类,但它们是依赖的,linter在第2行给了我问题,说Handl
-
问题内容: 我有3个div,如果我给出前两个div,则如果给出了,最后一个div应该移到下一行。如果我错了,请更正。 以下是我的html / css: 提前致谢。 问题答案: 该属性旨在在弹性项目之间分配容器中的自由空间。 它 不适 用于直接或精确调整弹性项目的大小。 从 规格: …确定当分配正的自由空间时,flex项目相对于flex容器中其余flex项目将增长多少。 因此,不会强迫物品包装。这是
-
让我们看看下面的例子 对这个注释的一些解释说,如果注释的bean被另一个bean引用,那么它将被初始化。但我认为不管有它还是没有它,“带注释的bean如果被另一个bean引用总是会被初始化”,那么它怎么解决循环依赖问题呢? 另一种解释是,如果调用了带注释的bean的方法,它就会被初始化,这听起来很合理,但我尝试了,在我看来,即使没有调用AService中的任何方法,B仍然可以持有对AService
-
问题内容: 我们有一个分为静态库的代码库。不幸的是,这些库具有循环依赖关系。例如,取决于,反之亦然。 我知道处理此问题的“正确”方法是使用链接器和选项,如下所示: 但是在我们现有的Makefile文件中,问题通常是这样处理的: (想象一下,它扩展到了约20个具有相互依赖关系的库。) 我一直在研究Makefile,将第二种格式更改为第一种,但是现在我的同事问我为什么…除了“因为它更干净”和模糊的感觉
-
我尝试用JNI在Java项目中加载C代码。我要加载多个DLL,不幸的是,其中两个之间存在循环依赖关系:DLL a需要DLL B,而DLL B又需要DLL a!我知道在DLL之间有循环依赖关系是一种糟糕的编程设计,但在我的项目中,C代码对我来说是一个黑盒子。 有没有办法加载具有循环依赖关系的DLL? 我的代码非常简单: Java库路径是OK的,并且包含两个DLL(它作为VM参数给出,我也将其转储并在