
32字节对齐例程不适合uops缓存

KbL i7-8550U
我正在研究uops缓存的行为,但遇到了一个误解。
如《英特尔优化手册》2.5.2.2(emp.mine)所述:
解码的ICache由32组组成。每组包含八种方式。每种方式最多可容纳六个微操作。
-
所有微操作都以某种方式表示代码中静态连续的指令,并且它们的EIP位于相同的对齐32字节区域内。
-
对于相同的32字节对齐块,最多可以使用三种方式,从而允许在原始IA程序的每个32字节区域中缓存总共18个微操作。
-
无条件分支是Way中的最后一个微操作。
案例1:
考虑以下例行程序:
<代码>uop。h
void inhibit_uops_cache(size_t);
<代码>uop。S
align 32
inhibit_uops_cache:
mov edx, esi
mov edx, esi
mov edx, esi
mov edx, esi
mov edx, esi
mov edx, esi
jmp decrement_jmp_tgt
decrement_jmp_tgt:
dec rdi
ja inhibit_uops_cache ;ja is intentional to avoid Macro-fusion
ret
为了确保例程的代码实际上是32字节对齐的,这里是asm
0x555555554820 <inhibit_uops_cache> mov edx,esi
0x555555554822 <inhibit_uops_cache+2> mov edx,esi
0x555555554824 <inhibit_uops_cache+4> mov edx,esi
0x555555554826 <inhibit_uops_cache+6> mov edx,esi
0x555555554828 <inhibit_uops_cache+8> mov edx,esi
0x55555555482a <inhibit_uops_cache+10> mov edx,esi
0x55555555482c <inhibit_uops_cache+12> jmp 0x55555555482e <decrement_jmp_tgt>
0x55555555482e <decrement_jmp_tgt> dec rdi
0x555555554831 <decrement_jmp_tgt+3> ja 0x555555554820 <inhibit_uops_cache>
0x555555554833 <decrement_jmp_tgt+5> ret
0x555555554834 <decrement_jmp_tgt+6> nop
0x555555554835 <decrement_jmp_tgt+7> nop
0x555555554836 <decrement_jmp_tgt+8> nop
0x555555554837 <decrement_jmp_tgt+9> nop
0x555555554838 <decrement_jmp_tgt+10> nop
0x555555554839 <decrement_jmp_tgt+11> nop
0x55555555483a <decrement_jmp_tgt+12> nop
0x55555555483b <decrement_jmp_tgt+13> nop
0x55555555483c <decrement_jmp_tgt+14> nop
0x55555555483d <decrement_jmp_tgt+15> nop
0x55555555483e <decrement_jmp_tgt+16> nop
0x55555555483f <decrement_jmp_tgt+17> nop
运行方式
int main(void){
inhibit_uops_cache(4096 * 4096 * 128L);
}
我拿到柜台了
Performance counter stats for './bin':
6 431 201 748 idq.dsb_cycles (56,91%)
19 175 741 518 idq.dsb_uops (57,13%)
7 866 687 idq.mite_uops (57,36%)
3 954 421 idq.ms_uops (57,46%)
560 459 dsb2mite_switches.penalty_cycles (57,28%)
884 486 frontend_retired.dsb_miss (57,05%)
6 782 598 787 cycles (56,82%)
1,749000366 seconds time elapsed
1,748985000 seconds user
0,000000000 seconds sys
这正是我所期望的。
绝大多数UOP来自uops缓存。此外,uops编号与我的预期完全相符
mov edx, esi - 1 uop;
jmp imm - 1 uop; near
dec rdi - 1 uop;
ja - 1 uop; near
4096 * 4096 * 128 * 9 = 19 327 352 832大约等于计数器19 326 755 442 3 836 395 1 642 975
案例2:
考虑一下inhibit\u uops\u cache的实现,它与注释掉的一条指令不同:
align 32
inhibit_uops_cache:
mov edx, esi
mov edx, esi
mov edx, esi
mov edx, esi
mov edx, esi
; mov edx, esi
jmp decrement_jmp_tgt
decrement_jmp_tgt:
dec rdi
ja inhibit_uops_cache ;ja is intentional to avoid Macro-fusion
ret
disas:
0x555555554820 <inhibit_uops_cache> mov edx,esi
0x555555554822 <inhibit_uops_cache+2> mov edx,esi
0x555555554824 <inhibit_uops_cache+4> mov edx,esi
0x555555554826 <inhibit_uops_cache+6> mov edx,esi
0x555555554828 <inhibit_uops_cache+8> mov edx,esi
0x55555555482a <inhibit_uops_cache+10> jmp 0x55555555482c <decrement_jmp_tgt>
0x55555555482c <decrement_jmp_tgt> dec rdi
0x55555555482f <decrement_jmp_tgt+3> ja 0x555555554820 <inhibit_uops_cache>
0x555555554831 <decrement_jmp_tgt+5> ret
0x555555554832 <decrement_jmp_tgt+6> nop
0x555555554833 <decrement_jmp_tgt+7> nop
0x555555554834 <decrement_jmp_tgt+8> nop
0x555555554835 <decrement_jmp_tgt+9> nop
0x555555554836 <decrement_jmp_tgt+10> nop
0x555555554837 <decrement_jmp_tgt+11> nop
0x555555554838 <decrement_jmp_tgt+12> nop
0x555555554839 <decrement_jmp_tgt+13> nop
0x55555555483a <decrement_jmp_tgt+14> nop
0x55555555483b <decrement_jmp_tgt+15> nop
0x55555555483c <decrement_jmp_tgt+16> nop
0x55555555483d <decrement_jmp_tgt+17> nop
0x55555555483e <decrement_jmp_tgt+18> nop
0x55555555483f <decrement_jmp_tgt+19> nop
运行方式
int main(void){
inhibit_uops_cache(4096 * 4096 * 128L);
}
我拿到柜台了
Performance counter stats for './bin':
2 464 970 970 idq.dsb_cycles (56,93%)
6 197 024 207 idq.dsb_uops (57,01%)
10 845 763 859 idq.mite_uops (57,19%)
3 022 089 idq.ms_uops (57,38%)
321 614 dsb2mite_switches.penalty_cycles (57,35%)
1 733 465 236 frontend_retired.dsb_miss (57,16%)
8 405 643 642 cycles (56,97%)
2,117538141 seconds time elapsed
2,117511000 seconds user
0,000000000 seconds sys
柜台完全出乎意料。
我希望所有UOP都像以前一样来自dsb,因为例程符合UOP缓存的要求。
相比之下,几乎70%的UOP来自传统解码管道。
问题:案例2有什么问题?要查看哪些计数器以了解发生了什么?
UPD:按照@PeterCordes的想法,我检查了无条件分支目标decrement_jmp_tgt的32字节对齐。这是结果:
案例3:
将条件跳转目标对齐到32字节,如下所示
align 32
inhibit_uops_cache:
mov edx, esi
mov edx, esi
mov edx, esi
mov edx, esi
mov edx, esi
; mov edx, esi
jmp decrement_jmp_tgt
align 32 ; align 16 does not change anything
decrement_jmp_tgt:
dec rdi
ja inhibit_uops_cache
ret
disas:
0x555555554820 <inhibit_uops_cache> mov edx,esi
0x555555554822 <inhibit_uops_cache+2> mov edx,esi
0x555555554824 <inhibit_uops_cache+4> mov edx,esi
0x555555554826 <inhibit_uops_cache+6> mov edx,esi
0x555555554828 <inhibit_uops_cache+8> mov edx,esi
0x55555555482a <inhibit_uops_cache+10> jmp 0x555555554840 <decrement_jmp_tgt>
#nops to meet the alignment
0x555555554840 <decrement_jmp_tgt> dec rdi
0x555555554843 <decrement_jmp_tgt+3> ja 0x555555554820 <inhibit_uops_cache>
0x555555554845 <decrement_jmp_tgt+5> ret
和运行方式
int main(void){
inhibit_uops_cache(4096 * 4096 * 128L);
}
我有以下计数器
Performance counter stats for './bin':
4 296 298 295 idq.dsb_cycles (57,19%)
17 145 751 147 idq.dsb_uops (57,32%)
45 834 799 idq.mite_uops (57,32%)
1 896 769 idq.ms_uops (57,32%)
136 865 dsb2mite_switches.penalty_cycles (57,04%)
161 314 frontend_retired.dsb_miss (56,90%)
4 319 137 397 cycles (56,91%)
1,096792233 seconds time elapsed
1,096759000 seconds user
0,000000000 seconds sys
结果完全在意料之中。超过99%的UOP来自dsb。
平均dsb uops交付率=17 145 751 147 / 4 296 298 295=3.99
接近峰值带宽。
共有2个答案

匿名用户
观察1:从uops缓存的角度来看,目标位于同一32字节区域内的分支的行为与无条件分支非常相似(即它应该是行中的最后一个uop)。
考虑以下抑制uops缓存的实现:
align 32
inhibit_uops_cache:
xor eax, eax
jmp t1 ;jz, jp, jbe, jge, jle, jnb, jnc, jng, jnl, jno, jns, jae
t1:
jmp t2 ;jz, jp, jbe, jge, jle, jnb, jnc, jng, jnl, jno, jns, jae
t2:
jmp t3 ;jz, jp, jbe, jge, jle, jnb, jnc, jng, jnl, jno, jns, jae
t3:
dec rdi
ja inhibit_uops_cache
ret
代码针对评论中提到的所有分支进行了测试。结果发现差异非常微不足道,所以我只提供了其中的2个:
jmp:
Performance counter stats for './bin':
4 748 772 552 idq.dsb_cycles (57,13%)
7 499 524 594 idq.dsb_uops (57,18%)
5 397 128 360 idq.mite_uops (57,18%)
8 696 719 idq.ms_uops (57,18%)
6 247 749 210 dsb2mite_switches.penalty_cycles (57,14%)
3 841 902 993 frontend_retired.dsb_miss (57,10%)
21 508 686 982 cycles (57,10%)
5,464493212 seconds time elapsed
5,464369000 seconds user
0,000000000 seconds sys
JGE:
Performance counter stats for './bin':
4 745 825 810 idq.dsb_cycles (57,13%)
7 494 052 019 idq.dsb_uops (57,13%)
5 399 327 121 idq.mite_uops (57,13%)
9 308 081 idq.ms_uops (57,13%)
6 243 915 955 dsb2mite_switches.penalty_cycles (57,16%)
3 842 842 590 frontend_retired.dsb_miss (57,16%)
21 507 525 469 cycles (57,16%)
5,486589670 seconds time elapsed
5,486481000 seconds user
0,000000000 seconds sys
IDK为什么dsb uops的数量是7 494 052 019,这比4096 * 4096 * 128 * 4 = 8 589 934 592要少得多。
将任何jmp替换为预计不会执行的分支会产生显著不同的结果。例如:
align 32
inhibit_uops_cache:
xor eax, eax
jnz t1 ; perfectly predicted to not be taken
t1:
jae t2
t2:
jae t3
t3:
dec rdi
ja inhibit_uops_cache
ret
以下计数器中的结果:
Performance counter stats for './bin':
5 420 107 670 idq.dsb_cycles (56,96%)
10 551 728 155 idq.dsb_uops (57,02%)
2 326 542 570 idq.mite_uops (57,16%)
6 209 728 idq.ms_uops (57,29%)
787 866 654 dsb2mite_switches.penalty_cycles (57,33%)
1 031 630 646 frontend_retired.dsb_miss (57,19%)
11 381 874 966 cycles (57,05%)
2,927769205 seconds time elapsed
2,927683000 seconds user
0,000000000 seconds sys
考虑另一个类似于案例1的例子:
align 32
inhibit_uops_cache:
nop
nop
nop
nop
nop
xor eax, eax
jmp t1
t1:
dec rdi
ja inhibit_uops_cache
ret
结果在
Performance counter stats for './bin':
6 331 388 209 idq.dsb_cycles (57,05%)
19 052 030 183 idq.dsb_uops (57,05%)
343 629 667 idq.mite_uops (57,05%)
2 804 560 idq.ms_uops (57,13%)
367 020 dsb2mite_switches.penalty_cycles (57,27%)
55 220 850 frontend_retired.dsb_miss (57,27%)
7 063 498 379 cycles (57,19%)
1,788124756 seconds time elapsed
1,788101000 seconds user
0,000000000 seconds sys
JZ:
Performance counter stats for './bin':
6 347 433 290 idq.dsb_cycles (57,07%)
18 959 366 600 idq.dsb_uops (57,07%)
389 514 665 idq.mite_uops (57,07%)
3 202 379 idq.ms_uops (57,12%)
423 720 dsb2mite_switches.penalty_cycles (57,24%)
69 486 934 frontend_retired.dsb_miss (57,24%)
7 063 060 791 cycles (57,19%)
1,789012978 seconds time elapsed
1,788985000 seconds user
0,000000000 seconds sys
JNO:
Performance counter stats for './bin':
6 417 056 199 idq.dsb_cycles (57,02%)
19 113 550 928 idq.dsb_uops (57,02%)
329 353 039 idq.mite_uops (57,02%)
4 383 952 idq.ms_uops (57,13%)
414 037 dsb2mite_switches.penalty_cycles (57,30%)
79 592 371 frontend_retired.dsb_miss (57,30%)
7 044 945 047 cycles (57,20%)
1,787111485 seconds time elapsed
1,787049000 seconds user
0,000000000 seconds sys
所有这些实验让我认为,观察结果与uops缓存的真实行为相对应。我还运行了另一个实验,并通过计数器判断br\u inst\u是否已退休。near\u TAKED和br\u inst\u retired。未采取结果与观察结果相关。
考虑以下抑制uops缓存的实现:
align 32
inhibit_uops_cache:
t0:
;nops 0-9
jmp t1
t1:
;nop 0-6
dec rdi
ja t0
ret
收集dsb2mite_switches.penalty_cycles和frontend_retired.dsb_miss我们有:
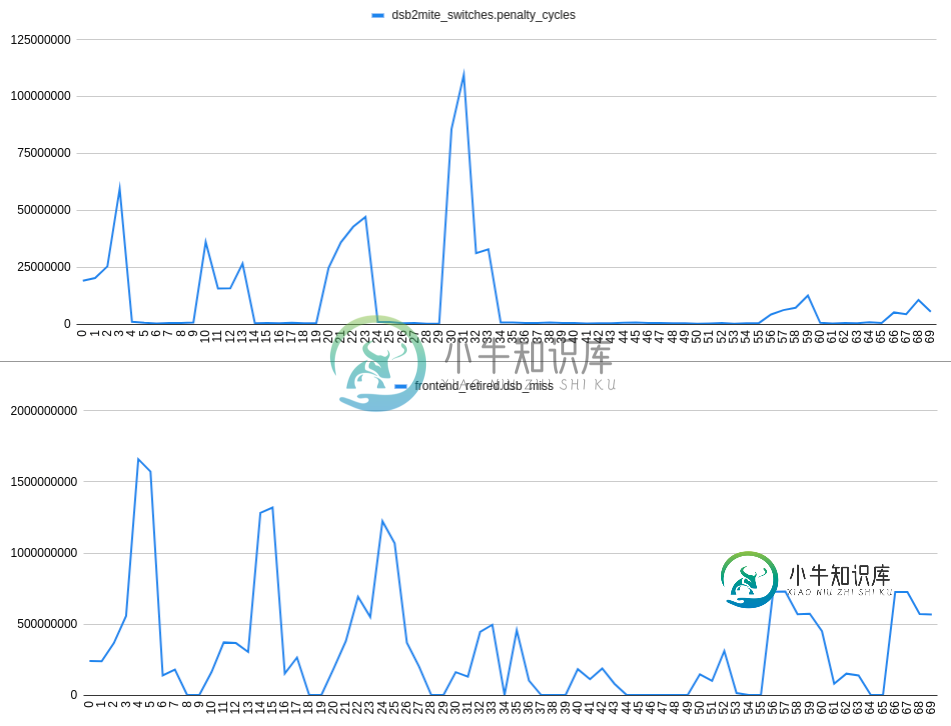
图的X轴代表nop的编号,例如24表示t1标签后的2个nop,t0标签后的4个nop:
align 32
inhibit_uops_cache:
t0:
nop
nop
nop
nop
jmp t1
t1:
nop
nop
dec rdi
ja t0
ret
根据情节判断,我来到了
观察2:如果预测在32字节区域内有2个分支,则dsb2mite开关和dsb未命中之间没有明显的相关性。因此dsb未命中可能独立于dsb2mite开关发生。
增加frontend_retired.dsb_miss速率与增加idq.mite_uops速率和减少idq.dsb_uops速率密切相关。这可以在以下图表中看到:
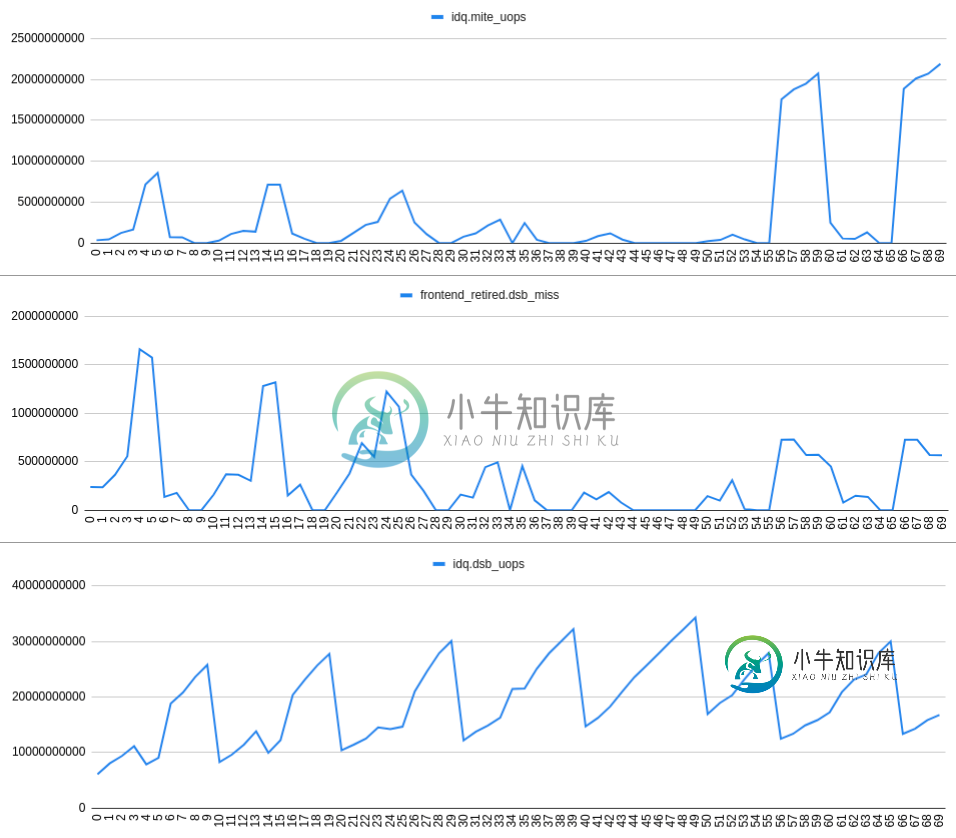
观察3:由于某些原因(不清楚?)发生的dsb未命中导致IDQ读取气泡,因此RAT下限溢位。
结论:考虑到所有测量值,英特尔优化手册2.5.2.2解码ICache中定义的行为之间肯定存在一些差异

请参见“代码对齐极大地影响编译器的性能”选项,以解决英特尔引入Skylake衍生CPU的性能缺陷,这是此解决方案的一部分。
其他观察结果:由6条mov指令组成的块应该填充uop缓存行,而jmp指令本身应该填充一行。在情况2中,5个mov应该放在一条缓存线中(或者更合适的“方式”)。
(为了将来可能有相同症状但原因不同的读者的利益,我发表了这篇文章。写完后,我意识到,0x…30不是32字节的边界,只有0x…20和40,所以这个勘误表不应该是问题代码的问题。)
最近(2019年末)的微码更新引入了一个新的性能漏洞。它围绕英特尔的JCC勘误表对Skylake衍生的微体系结构进行工作。(KBL142专门针对您的卡比湖)。
微码更新(MCU)以缓解JCC错误
可以通过微码更新(MCU)防止此错误。当跳转指令跨越32字节边界或结束于32字节边界时,MCU防止跳转指令缓存在解码的ICache中。在此上下文中,跳转指令包括所有跳转类型:条件跳转(Jcc)、宏融合运算Jcc(其中op是cmp、test、add、sub和inc或dec之一)、直接无条件跳转、间接跳转、直接/间接调用和返回。
Intel的白皮书还包括触发这种非uop可缓存效果的案例图。(PDF截图摘自Phoronix的一篇文章,其中包含前后的基准测试,以及使用GCC/GAS中的一些变通方法进行重建,以避免这种新的性能陷阱)。
代码中ja的最后一个字节是
...30,所以它是罪魁祸首。
如果这是一个32字节的边界,而不仅仅是16字节,那么我们这里就有问题了:
0x55555555482a <inhibit_uops_cache+10> jmp # fine
0x55555555482c <decrement_jmp_tgt> dec rdi
0x55555555482f <decrement_jmp_tgt+3> ja # spans 16B boundary (not 32)
0x555555554831 <decrement_jmp_tgt+5> ret # fine
本节未完全更新,仍在讨论跨越32B边界
JA本身跨越了一个边界。
在dec rdi之后插入NOP应该可以工作,将2字节的ja完全放在边界之后,并添加一个新的32字节块。反正dec/ja的宏融合是不可能的,因为JA读取CF(和ZF),但DEC不写入CF。
使用子rdi,1移动JA将不起作用;它将进行宏融合,与该指令相对应的6字节x86代码组合仍将跨越边界。
您可以在jmp之前使用单字节nops而不是mov来更早地移动所有内容,如果这样可以在块的最后一个字节之前将所有内容都移入。
ASLR可以更改虚拟页代码的执行来源(地址的第12位及更高),但不能更改页内或相对于缓存线的对齐方式。因此,我们在一种情况下看到的拆卸每次都会发生。
-
问题内容: 我如何使用,以及在性能?的,如果我不使用工作正常。但是,如果我使用浮点数,那么它将不起作用。对我来说,在最后一个div中使用至关重要。 我正在尝试遵循,如果您从所有div中删除浮点数,那么它将正常工作: CSS: JSFiddle 问题答案: 您需要设置行高。
-
我试图清楚地了解谁(调用者或被调用者)负责堆栈对齐。64位程序集的情况相当清楚,它是由调用者完成的。 参考System V AMD64 ABI,第3.2.2节堆栈框架: 输入参数区域的末尾应在16(32,如果__m256在堆栈上传递)字节边界上对齐。 换句话说,应该可以安全地假设,对于被调用函数的每个切入点: 保持(额外的8是因为调用隐式地将返回地址推送到堆栈上)。 它在32位世界中看起来如何(假
-
结构体字节对齐 接下来我们学习的C中的第三种空间-结构体空间,结构体空间是将基本数据类型或者是其它构造数据类型打包的工具。打包就是结构体最主要的一种功能,在打包过程中,我们要引入一个新的概念-字节对齐。这个打包不是随随便便就OK的,不像我们装行李只要全部装进去就好了。 首先我们先来看一段代码,我们将一个结构体里面包含了一个char和int类型,然后声明一个结构体变量,这个变量在内存中占的大小会是1
-
libdyld.dylib`STACK_NOT_16_BYTE_ALIGNED_ERROR:->0x7FFFC12DA2FA<+0>:movdqa%xMM0,(%RSP)0x7FFFC12DA2FF<+5>:int3 libdyld.dylib`_dyld_func_lookup:0x7fffc12da300<+0>:pushq%rbp 0x7fffc12da301<+1>:movq%rsp,%r
-
问题内容: 我刚刚更新到Firefox 32,当我尝试运行Selenium Webdriver Test时,我得到以下信息 我期望能够正常运行测试。 有没有人遇到过同样的事情?您是如何解决该问题的? selenium版本:2.41.0(作为Nuget软件包安装)操作系统:Windows 7浏览器:Firefox浏览器版本:32 问题答案: Selenium2.41.0正式支持的最新Firefox版