
用最大值更新组中的所有行SQL

我已经研究过了
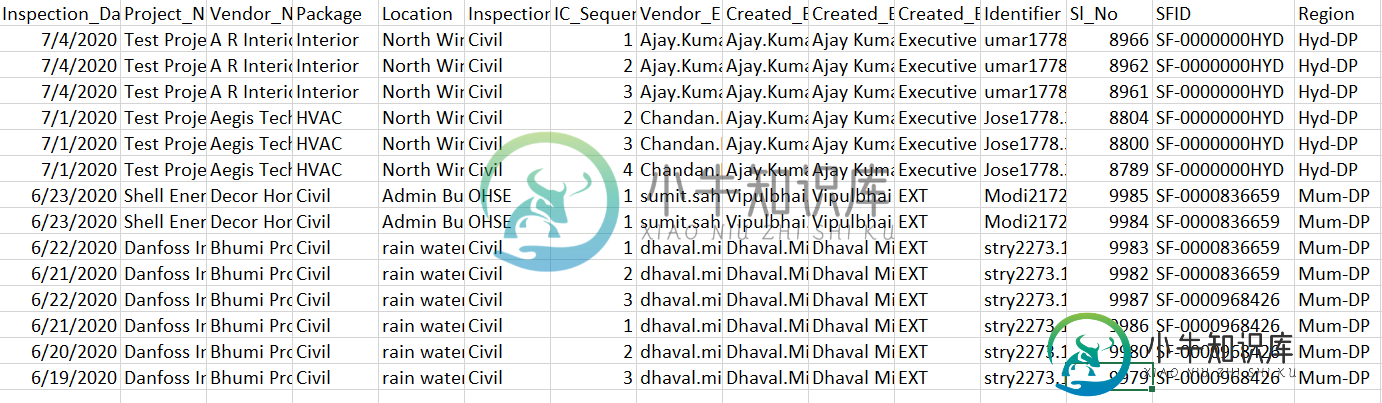
我想将Inspection\u Date和Sl\u No列的所有行更新为SFID组中的最新行。
生成的表应如下所示:-
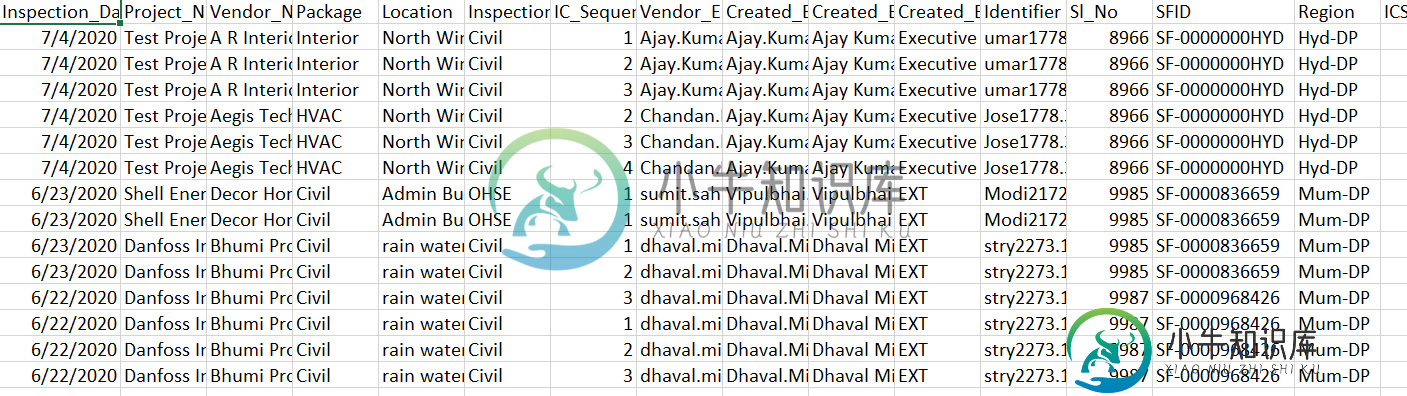
我试过两种方法:-
帮助源:-来自此sqlite的帮助:使用第一行的值更新组中的所有行
代码1:-
UPDATE new_copy_2 set Sl_No = (
SELECT MAX(Sl_No) as max_date
FROM new_copy_2 T2
where Inspection_Type like '%PMCR%'
and exists
(select 1 from new_copy_2 tt
where tt.SFID = T2.SFID
and tt.Inspection_Type like '%PMCR%')
错误:-
Incorrect syntax near ')'.
帮助来源:-MySQL-更新所有记录以匹配组中的最大值
代码2:-
UPDATE new_copy_2
JOIN (
SELECT SFID, MAX(Sl_No) AS flag
FROM new_copy_2
GROUP BY
SFID
) t
ON SFID = t.SFID
SET Sl_No = t.flag
where Inspection_Type like '%PMCR%'
and exists
(select 1 from new_copy_2 tt
where tt.SFID = SFID
and tt.Inspection_Type like '%PMCR%')
错误:-
Incorrect syntax near the keyword 'JOIN'.
Incorrect syntax near 't'.
请帮助!!
输入数据集示例
| : Inspection_Date : | : SFID : | Sl_No
| : 7/4/2020 : | : SF-0000000HYD : | 8868
| : 6/4/2020 : | : SF-0000000HYD : | 8864
| : 3/3/2020 : | : SF-0000836659 : | 7845
| : 3/1/2020 : | : SF-0000836659 : | 7842
| : 4/7/2020 : | : SF-0000836432 : | 7862
| : 4/5/2020 : | : SF-0000836432 : | 7840
预期数据集示例
|: Inspection_Date |: SFID |: Sl_No
|: 7/4/2020 |: SF-0000000HYD |: 8868
|: 7/4/2020 |: SF-0000000HYD |: 8868
|: 3/3/2020 |: SF-0000836659 |: 7845
|: 3/3/2020 |: SF-0000836659 |: 7845
|: 4/7/2020 |: SF-0000836432 |: 7862
|: 4/7/2020 |: SF-0000836432 |: 7862
共有3个答案

我可以使用一种变通方法来解决这个问题,首先提取每个SFID中Sl\U No最大值的行
Select * into trial_data_extract from trial_data AS dat1
where Sl_No =
( Select MAX(Sl_No) from trial_data As dat2 where dat1.SFID =dat2.SFID)
Update trial_data
Set Identifier = dat2.Identifier,
Inspection_Date = dat2.Inspection_Date
from trial_data dat1
Inner Join
trial_data_extract dat2
on dat1.SFID = dat2.SFID
谢谢大家的帮助!!

您可以按如下方式使用子查询:
UPDATE new_copy_2 set Sl_No = (
SELECT MAX(Sl_No) as max_date
FROM new_copy_2 T2
where sfid = T2.sfid)
where exists
(select 1 from new_copy_2 tt
where tt.SFID = SFID)

您可以使用以下窗口功能尝试cte:
with cte as (
select *, max(sl_no)over (partition by sfid order by Inspection_Date desc) MaxSL
from new_copy_2 )
update cte set sl_no=MaxSL
where sl_no <> maxsl;
恐怕无法更新sql server中的标识列,但可以通过设置identity\u insert on插入新行,然后删除现有行。检查下面的链接。
https://stackoverflow.com/questions/19155775/how-to-update-identity-column-in-sql-server#:~:text=您不能更新标识,类似的要求。
-
问题内容: 我想更新表中的一个字段,以便所有行都具有与第一行相同的值。我认为这很简单: 但是MySql不喜欢那样。 问题答案: 您可以将子查询嵌套在另一个查询中:
-
如果我想将一个名为“maximum_num”的新列突变到x上,其值为5.1,4.9,4.7等,我该怎么做?(我意识到糟糕的例子,因为这里都是Sepal.Length,但如果最大值每次来自不同的cols) 我想我可以用which.max但不知道如何编织。 我也试过 如何追加包含最大行值的新列? 有dplyr esque的方式吗?对base r也很满意。
-
在oracle DB中检索具有大组最大值的行时遇到问题。 我的桌子看起来是这样的: id,col1,col2,col3,col4,col5,date_col 谢谢你的提示! 干杯
-
预期输出:获取组之间计数为max的结果行,如: 示例2:这个数据帧,我按分组: 对于上面的示例,我希望获取每个组中等于max的所有行,例如:
-
给定一个数组,编写一个程序以在大小的所有子数组中找到最大 gcd 我的代码: 它是O(N^2),还能再优化吗?
-
问题内容: 我需要一种快速的方法来保持运行最大的numpy数组。例如,如果我的数组是: 我想要: 显然我可以做一个小循环: 但是我的数组有成千上万的条目,我需要多次调用。似乎必须要有一个小技巧才能删除循环,但我似乎找不到任何有效的方法。另一种选择是将其编写为C扩展,但似乎我会重新发明轮子。 问题答案: 为我工作。