
如何在Keras中实现LSTM单元的层次模型?

我想使用Keras实现下图中描述的模型,但我不知道如何实现。
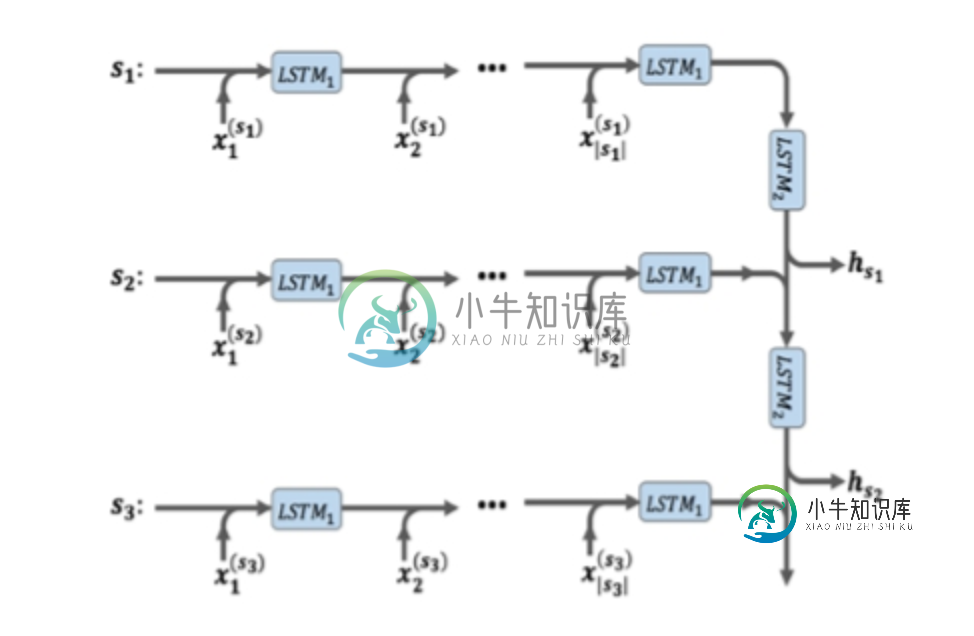
如果模型的输入像(批处理,最大长度句子,最大长度单词),我需要如何实现它?
共有1个答案

如果我正确理解了你的问题,那么每个训练样本由多个句子组成,其中每个句子由多个单词组成(似乎每个训练样本都是文本文档中的句子)。第一个LSTM层处理一个句子,然后在处理所有句子之后,第一个LSTM层对句子的表示被馈送到第二个LSTM层。
要实现此体系结构,需要将第一个LSTM层包装在TimeDistributed层中,以允许它单独处理每个句子。然后,您可以简单地在顶部添加另一个LSTM层,以处理第一个LSTM层的输出。这是一张草图:
lstm1_units = 128
lstm2_units = 64
max_num_sentences = 10
max_num_words = 100
emb_dim = 256
model = Sequential()
model.add(TimeDistributed(LSTM(lstm1_units), input_shape=(max_num_sentences, max_num_words, emb_dim)))
model.add(LSTM(lstm2_units, return_sequences=True))
model.summary()
模型摘要:
Layer (type) Output Shape Param #
=================================================================
time_distributed_4 (TimeDist (None, 10, 128) 197120
_________________________________________________________________
lstm_6 (LSTM) (None, 10, 64) 49408
=================================================================
Total params: 246,528
Trainable params: 246,528
Non-trainable params: 0
_________________________________________________________________
如您所见,由于我们对第二个LSTM层使用了return\u sequences=True,因此返回了对应于每个句子的输出(这与您问题中的图一致)。此外,请注意,这里我们假设单词是使用单词向量(即单词嵌入)表示的。如果不是这样,并且您希望这样做,您可以简单地添加一个嵌入层(包装在时间分布层中)作为第一层,使用单词嵌入来表示单词,其余的都是相同的。
-
我开始学习RNN,并尝试在Keras中实现SimpleRNN。这是我的代码: 系统抛出以下错误: 回溯(最后一次调用):模型中第1行的文件“”。添加(SimpleRN(32))文件“/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site packages/keras/engine/sequential.py”,第18
-
我想创建一个Keras模型,包括一个嵌入层,然后是两个具有dropout 0.5的LSTM,最后是一个具有softmax激活的密集层。 第一个LSTM应该将顺序输出传播到第二层,而在第二层中,我只想在处理完整个序列后获得LSTM的隐藏状态。 我尝试了以下方法: 但是,我遇到以下错误: 显然,LSTM并没有返回我所期望的形状输出。如何修复此问题?
-
问题内容: 更新1: Im所指的代码正是本书中的代码,您可以在这里找到。 唯一的事情是我不想在解码器部分中拥有。这就是为什么我认为根本不需要嵌入层的原因,因为如果我放入嵌入层,则需要包含在解码器部分中(如果Im错误,请更正我)。 总体而言,我试图在不使用嵌入层的情况下采用相同的代码,因为我需要在解码器部分中具有。 我认为评论中提供的建议可能是正确的()我如何面对此错误: 当我做的时候: 我收到此错
-
嘿,伙计们,我已经建立了一个有效的LSTM模型,现在我正在尝试(不成功)添加一个嵌入层作为第一层。 这个解决方案对我不起作用。在提问之前,我还阅读了这些问题:Keras输入解释:输入形状、单位、批次大小、尺寸等,了解Keras LSTM和Keras示例。 我的输入是一种由27个字母组成的语言的字符的单键编码(1和0)。我选择将每个单词表示为10个字符的序列。每个单词的输入大小是(10,27),我有
-
我使用的是多次,每次都负责训练一个层块,其他层被冻结 奇怪的是,在第二次拟合中,第一个历元的精度远低于第一次拟合的最后一个历元的精度。 纪元40/40 6286/6286 [==============================] - 14s 2ms/样品-损耗: 0.2370-精度: 0.9211-val_loss: 1.3579-val_accuracy:0.6762 874/874 [
-
我有一个两层神经网络的例子。第一层接受两个参数并有一个输出。第二个应作为第一层的结果使用一个参数和一个附加参数。应该是这样的: 因此,我创建了一个具有两个层的模型,并尝试将它们合并,但它返回了一个错误:<代码>顺序模型中的第一层必须获得“input\u shape”或“batch\u input\u shape”参数 在线<代码>结果。添加(合并)。 型号: