
Bdsk采样错误

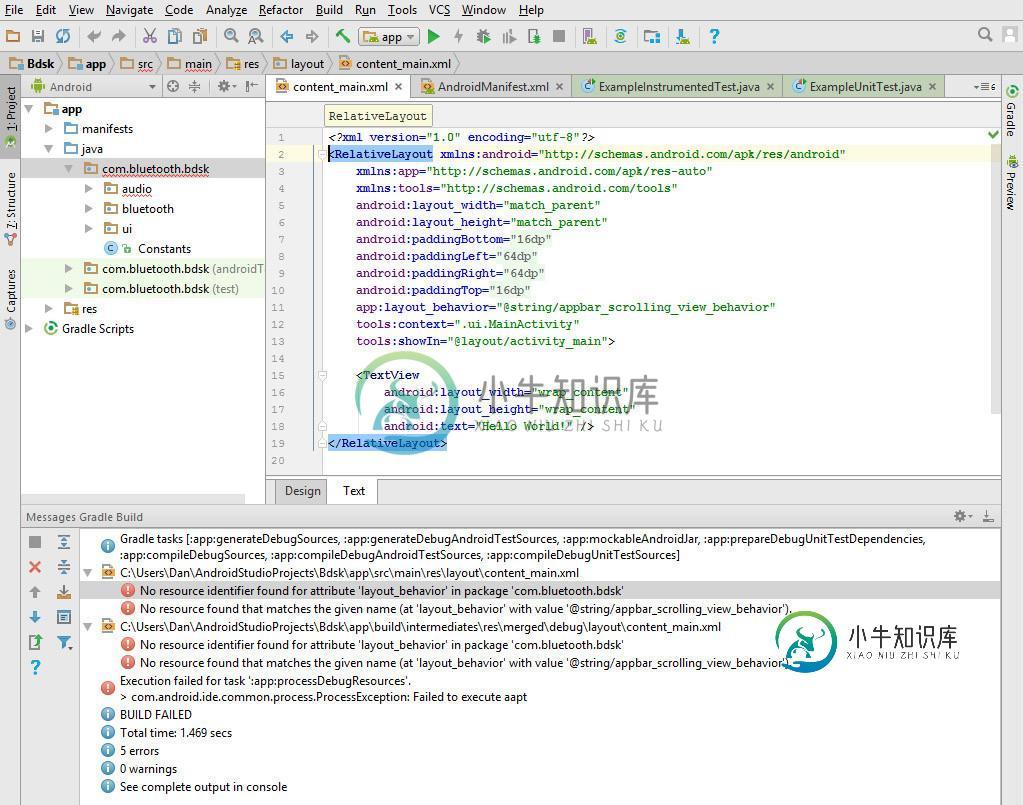
我在尝试制作Bdsk样例文件时出现了一些错误。作为Android Studio的新手,如果能让我知道如何修复这些错误,我将非常感激。
我根据以下说明使用示例源代码:要使用解决方案代码,使用名称“bdsk”和公司域名“bluetooth.com”创建一个新的Android Studio项目。创建项目后,将BDSK\app\src\main文件夹中的内容替换为Bluetooth Developer Starter Kit文件夹“Android\Source\Solution”(除了以下自述文件)中的内容。
共有1个答案

-
在分布式跟踪中,数据量可能非常高,因此采样可能很重要(您通常不需要导出所有spans以获得正在发生的情况)。Spring Cloud Sleuth具有Sampler策略,您可以实现该策略来控制采样算法。采样器不会停止生成跨度(相关)ids,但是它们确实阻止了附加和导出的标签和事件。默认情况下,您将获得一个策略,如果跨度已经处于活动状态,则会继续跟踪,但新策略始终被标记为不可导出。如果您的所有应用程
-
如果非周期马尔科夫链的状态转移矩阵P和概率分布$$pi(x)$$对于所有的i,j满足:$$pi(i)P(i,j) = pi(j)P(j,i)$$ 则称概率分布$$pi(x)$$是状态转移矩阵P的平稳分布。 在M-H采样中我们通过引入接受率使细致平稳条件满足。现在我们换一个思路。 从二维的数据分布开始,假设$$pi(x_1,x_2)$$是一个二维联合数据分布,观察第一个特征维度相同的两个点$$A(x
-
本文向大家介绍储层采样,包括了储层采样的使用技巧和注意事项,需要的朋友参考一下 水库采样是一种随机算法。在该算法中,从具有n个不同项的列表中选择k个项。 我们可以通过创建一个数组作为大小为k的容器来解决它。然后从主列表中随机选择一个元素,然后将该项目放置在容器列表中。一次选择一项时,下次将不再选择。但是他的方法无效,我们可以通过这种方法增加复杂性。 在存储库列表中,复制列表中的前k个项目,现在从列
-
目前 SOFATracer 提供了两种采样模式,一种是基于 BitSet 实现的基于固定采样率的采样模式;另外一种是提供给用户自定义实现采样的采样模式。下面通过案例来演示如何使用。 本示例基于 tracer-sample-with-springmvc 工程;除 application.properties 之外,其他均相同。 基于固定采样率的采样模式 在 application.propertie
-
我正在尝试在使用的Scikit学习SVM分类器中使用类权重。 我有四节课。现在对于class_weight,我希望四个类中的每一个都有介于0和1之间的随机值。可以用 但这仅适用于一个类,并且值是离散的,而不仅仅是在 0 和 1 之间采样。 我该如何解决这个问题? 最后但同样重要的是,如果我使用0到1之间或1到10之间的值,这有关系吗(即权重是否被重新调整)? 所有4类的权重总和是否应该总是相同的值
-
在解决从平稳分布$$pi$$, 找到对应的马尔科夫链状态转移矩阵P之前,我们还需要先看看马尔科夫链的细致平稳条件。定义如下: 如果非周期马尔科夫链的状态转移矩阵P和概率分布$$pi(x)$$对于所有的i,j满足:$$pi(i)P(i,j) = pi(j)P(j,i)$$ 则称概率分布$$pi(x)$$是状态转移矩阵P的平稳分布。 证明很简单,由细致平稳条件有:$$sumlimits_{i=1}{i