
问题:

通过添加列“count”合并重复行[duplicate]
孔欣可
我想通过添加新列“count”来合并重复行
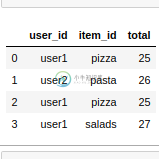
我想要的最终数据帧

行可以按任何顺序排列
共有1个答案

郭志泽
您可以使用:
df["count"] = 1
df = df.groupby(["user_id", "item_id", "total"])["count"].count().reset_index()
类似资料:
-
使用以下数据帧: 我想获得 我分别尝试了和 但我不知道如何将两者结合起来,或者是否有其他方法。
-
我有两列,一列有年份,另一列有月份数据,我正试图从中创建一列(包含年份和月份)。 示例: 我想拥有 我试过了 但它给了我“无法从重复轴重新编制索引”错误。
-
问题内容: 我的MySQL表具有以下结构: 我想将以上三列合并为一列,如下所示: 我想将此“组合”列添加到表的末尾而不破坏原始的3个字段。 问题答案: 创建列: 更新当前值: 自动更新所有未来值:
-
我有一个来自excel电子表格的数据框,其中我找到了每个域出现的频率。我想添加域频率计数到它的相应域。 下面是查找频率并尝试将其添加到相应域的代码。 当我从数据帧打印出频率时:
-
问题内容: 如果我的数据框具有包含相同名称的列,是否可以将具有相同名称的列与某种功能(即求和)结合起来? 例如: 如何通过对列名称相同的每一行求和来折叠NY-WEB01列(有一堆重复的列,而不仅仅是NY-WEB01)? 问题答案: 我相信这可以满足您的要求: 或者,取决于df的长度,快3%至15%: 编辑:要将其扩展到总和之外,请使用(的缩写):
-
问题内容: 我非常确定应该有一种更Python化的方法来执行此操作-但我想不起来:如何将二维列表合并到一维列表中?有点像zip / map,但是有两个以上的迭代器。 示例-我有以下列表: 我希望有 到目前为止,我想出的是: 但这对我来说似乎不是很优雅/ Pythonic。除了不检查2D数组中的所有“线”是否都具有相同的长度,可以相互添加等等之外,还有什么更好的方法呢? 问题答案: