
带子标题的Python web刮削表

我正试图从一个出现在各种网页上的表格中提取一些信息(我为没有透露网页而道歉)。
<table class="toccolours" style="font-size: 85%;">
<tbody><tr>
<th colspan="8" style="background-color: #ccf; color: #000080; text-align:center;"><b>First sub-class</b></th>
</tr>
<tr>
<td style="padding-right:5px">Info1</td>
<td style="padding-right:5px;"><a title="Object 1">Object 1</a></td>
<td style="text-align:center;padding-right:5px">Info 2</td>
<td style="padding-right:5px"><a title="Object 2">Object 2</a></td>
<td style="padding-right:5px">Info 3</td>
<td style="text-align:center;">Info 4</td>
<td style="text-align:center;">Info 5</td>
<td></td>
</tr>
<tr>
<th colspan="8" style="background-color: #ccf; color: #000080; text-align:center;"><b>Second sub-class</b></th>
</tr>
<tr>
<td style="padding-right:5px">Info11</td>
<td style="padding-right:5px;"><a title="Object 11">Object 11</a></td>
<td style="text-align:center;padding-right:5px">Info 22</td>
<td style="padding-right:5px"><a title="Object 22">Object 22</a></td>
<td style="padding-right:5px">Info 33</td>
<td style="text-align:center;">Info 44</td>
<td style="text-align:center;">Info 55</td>
<td></td>
</tr>
<tr>
<th colspan="8" style="background-color: #ccf; color: #000080; text-align:center;"><b>Third sub-class</b></th>
</tr>
<tr>
<td style="padding-right:5px">Info 111</td>
<td style="padding-right:5px;"><a title="Object 111">Object 111</a></td>
<td style="text-align:center;padding-right:5px">Info 222</td>
<td style="padding-right:5px">Object 222</td>
<td style="padding-right:5px">Info 333</td>
<td style="text-align:center;">Info 444</td>
<td style="text-align:center;">Info 555</td>
<td></td>
</tr>
</tbody></table>
360c-9511-405c-ac58-90f37c9f34af.png" width="100%" height="100%" />
图像1
问题是子类和每个子类的行数都可能发生变化。因此,例如,在某些情况下,第一子类可以具有1个项目,第二子类可以具有3个项目,第三子类可以具有2个项目。另外,我还可以得到一个只有子类1和2的表。
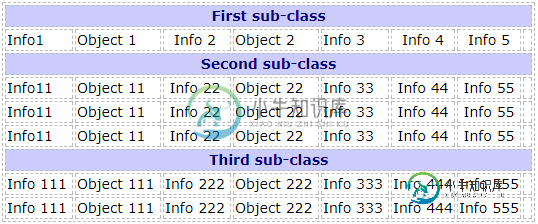
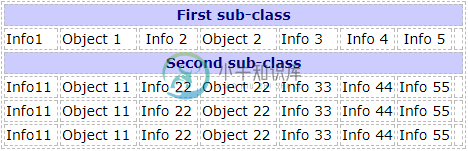
我想以这样一种格式获取数据,即子类值以以下格式出现在相关信息行旁边(如图1所示):

图4
但是,我有点纠结于如何在python上实现这一点,因为表标题不是每个行项都出现在其下的单独类。我可以调用一个网页上使用web驱动程序和提取网页源使用美丽汤。但是,在这种情况下,我不知道如何将子类分配给行(特别是因为info行不是作为子类行的一个元素出现,而是作为表的一个新行出现)。
P
共有1个答案

只需逐行处理HTML:
b = bs4.BeautifulSoup(html)
data = {}
current = None
for row in b.find_all('tr'):
if row.find_all('th'):
# this is a header
current = row.find_all('th')[0].text
else:
# this is not a header, therefore is data under the last header seen
data[current] = row.find_all('td') # do whatever processing you need to do here, you did't specify
如果需要保留标头的顺序,而不是dict,请使用列表的列表:
data = []
headers = []
for row in b.find_all('tr'):
if row.find_all('th'):
# this is a header
headers.append(row.find_all('th')[0].text)
data.append([])
else:
# this is not a header, therefore is data under the last header seen
data[-1].append(row.find_all('td'))
print zip(headers,data)
-
我试图刮一个页面与美丽的汤,有
-
我正试图从Zalora那里获得3件事:1。项目品牌2。项目名称3。项目价格(旧) 以下是我最初的尝试: 输出: 然后我做进一步的调查: 输出: 这是令我困惑的奇怪的事情,在ul标签中应该有很多标签(我需要的3样东西都在那些隐藏的标签中),为什么它们不显示? 事实上,我试图在ul标签中使用BeautifulSoup刮取的所有内容都没有输出。
-
Python Web Project 试图增强 Python 使之更适合用于 Web 开发。
-
在我的过去,我已经实施了一些网页刮取项目--从小型到中型(大约100.000个刮取页面)不等。通常我的起点是一个索引页,它链接到几个页面,上面有我想刮的细节。最后大部分时间我的项目都起作用了。但是我总是觉得我可以改进工作流程(特别是关于减少我给被清除的网站造成的流量的挑战[和连接到那个主题:被禁止的风险:D])。 这就是为什么我想知道你的(最佳实践)web刮板设计方法(针对小型和中型项目)。 通常
-
初学者。我想提取巴克莱的所有作业(https://search.jobs.Barclays/search-jobs) 我通过刮了第一页,但挣扎着去下一页,因为url没有改变。我试着在下一页按钮上刮url,但那个href把我带回主页。 这是否意味着所有的职务数据实际上都存储在原始HTML中?如果是,我该如何提取? 谢谢!
-
我用selenium用python编写了一个脚本,用于解析填充输入框并访问按钮时填充的一些结果。现在我的脚本很好地完成了这一部分。但是,我的主要目标是解析容器的标题,也可以作为来显示。 这是我到目前为止的尝试():