
从Docx文件中读取Tables数据

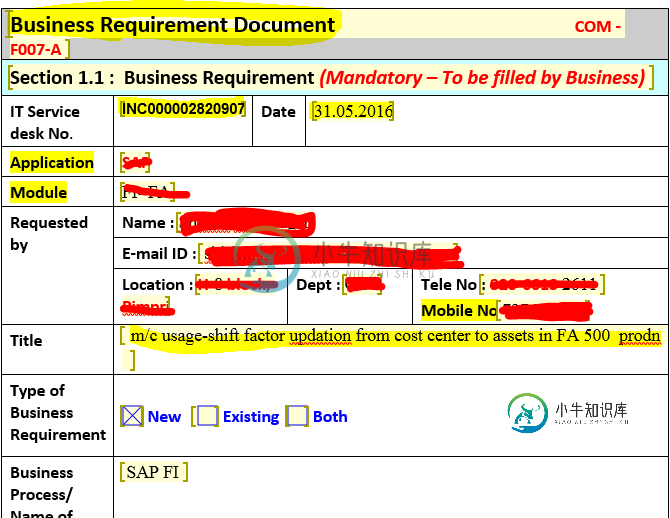
必须从文档中检索突出显示的数据。
public static void readDocxFile(String fileName){
try {
File file = new File(fileName);
FileInputStream fis = new FileInputStream(file.getAbsolutePath());
XWPFDocument document = new XWPFDocument(fis);
List<XWPFParagraph> paragraphs = document.getParagraphs();
System.out.println("Total Number of Paragraphs:: "+paragraphs.size());
for (int i = 0; i < paragraphs.size(); i++) {
System.out.println(paragraphs.get(i).getParagraphText());
}
fis.close();
} catch (Exception e) {
e.printStackTrace();
}
}
这是我用来返回页面中的数据的方法,但没有得到用黄色标记的数据,只有那些数据被输入到输出中,而这些数据在word文档的表中没有提到。
共有1个答案

public class ReadTableWord {
static String temp = "";
static String cellValue;
public static void main(String[] args) throws IOException {
File file = new File("D:/Test111/BRD-+machine-usage+updation.docx");
FileInputStream fis = new FileInputStream(file);
XWPFDocument doc = new XWPFDocument(fis);
List<XWPFTable> tables = doc.getTables();
for (XWPFTable table : tables) {
for (XWPFTableRow row : table.getRows()) {
for (XWPFTableCell cell : row.getTableCells()) {
System.out.println(cell.getText());
String sFieldValue = cell.getText();
if (sFieldValue.matches("Whatever you want to match with the string") || sFieldValue.matches("Approved")) {
System.out.println("The match as per the Document is True");
}
// System.out.println("\t");
}
System.out.println(" ");
}
}
}
}-
我正在使用库python-docx解析docx文件。我需要阅读文档和段落的标题,但是我在文档中找不到任何关于文档标题的东西。有关于将标头写入新文件的文档,但没有关于读取标头的文档。有办法做到这一点吗?
-
我面临的例外情况如下: java.lang.nosuchmethoderror:org.apache.xml.utils.DefaulTerrorHandler.(Z)V在org.docx4j.org.apache.xalan.transformer.transformerIdentityImpl.(TransformerIdentityImpl.transformerIdentityImpl.(
-
我有一个非常简单的问题:使用Python从txt文件中读取不同条目的最有效方法是什么? 假设我有一个文本文件,如下所示: 在C中,我会这样做: 用Python做这样的事情最好的方法是什么?以便将每个值存储到不同的变量中(因为我必须在整个代码中使用这些变量)。 提前感谢!
-
在我的应用程序中,我想读取一个文档文件(.doc或.odt或.docx)并将该文本存储在字符串中。为此,我使用下面的代码:
-
问题内容: 我有以下格式的文本文件: Details.txt 该文件是.txt文件。我想从该文件中读取课程标题,并打印相应的教科书和教师信息。但是我不确定该遵循什么程序?将信息存储在数组中效率不高!我应该如何进行?注意:我无法更改文件中的信息,因此不应更改!显然,文件将通过以下代码读取: 但是我应该如何根据课程名称,教科书和讲师的标签从该文件中提取数据! 问题答案: 首先正确地逐行阅读文件,然后搜
-
问题内容: 如何从文件中读取浮点数? 在文件第一列之前和数字之间的2个空格中。我立即有错误: 问题答案: 所以,我理解我的错误。我需要用 因为该扫描程序会干扰“。” 作为小数点分隔符,在我的语言环境(默认)中为“,”。另请注意,nextDouble可以识别1.1和3(整数) //根据此链接