
为什么我们从下往上而不是从上而下构建最大堆

问题:为什么我们希望BUILD-MAX-HEAP第2行中的循环索引<code>i到1,而不是从1增加到⌊长度[A]/2⌋
?
算法:(算法入门书):
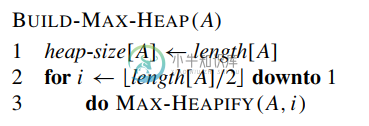

我试着用下面的图来展示这一点。
方法1:如果我们以相反的方式应用构建堆,从1到数组A=的长度[A]/2
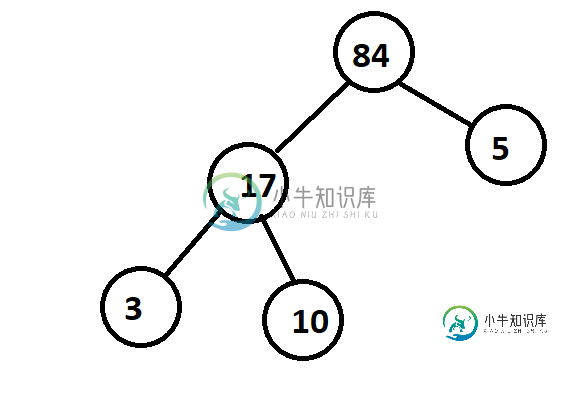
方法2:如果我们以与<code>相反的方式应用构建堆⌊长度[A]/2⌋
并减少到数组A的1=
问题:我发现在这两种情况下,父树大于其子树的堆属性都被保留,所以我不明白为什么一个解决方案说会有这样的问题,“我们不被允许调用MAX-HEAPIFY,因为它不满足子树是max-heaps的条件。也就是说,如果我们从< code>1开始,就不能保证< code>A[2]
共有1个答案

问题是你只能依靠MAX_HEAPIFY来完成它的工作,当根在i的子树在任何地方都服从堆属性时,除了根值(at i)本身,这可能需要向下筛选。MAX_HEAPIFY的工作只是将根的值移动到它的正确位置。它不能修复任何其他违反堆属性的行为。但是,如果保证i下面的树的其余部分服从堆属性,那么您可以确定在MAX_HEAPIFY运行后,i处的子树将是堆。
因此,如果您从top node开始,那么谁知道您将获得什么...树的其余部分不应服从堆属性,因此MAX_HEAPIFY不会(必然)传递堆。而且以自上而下的方式继续工作也无济于事。
如果我们采用html" target="_blank">示例树并执行前向循环替换,那么我们首先在该树上调用MAX_HEAPIFY(1):
5
/ \
3 17
/ \
10 84
...然后5将与17(位置3)交换,然后我们将在该节点上递归调用MAX_HEAPIFY(3),这将无济于事。所以我们会得到:
17
/ \
3 5
/ \
10 84
接下来,我们调用MAX_HEAPIFY(2),它将用84交换3:
17
/ \
84 5
/ \
10 3
在值为3的节点上再次进行递归调用,但这不会做任何事情。
这是前向循环替代中< code>MAX_HEAPIFY的最后一次调用...我们可以看到,值84没有机会找到它应该在的顶端。
-
问题内容: 为什么我们说C这样的语言是自上而下的,而Java或C ++这样的OOP语言是自下而上的呢?这种分类在软件开发中是否有任何重要性? 问题答案: “自上而下”的方法对问题进行了高级定义,并将其细分为子问题,然后您可以递归地进行处理,直到发现明显且易于编码的部分为止。这通常与编程的“功能分解”风格相关联,但不是必须的。 在“自下而上”编程中,您确定了可以构成更大程序的较低级工具。 实际上,几
-
我很困惑,无法理解为什么不应该吞掉InterruptedException。 IBM的文章说 当阻塞方法检测到中断并抛出InterruptedException时,它将清除中断状态。如果捕捉到InterruptedException,但无法重新抛出它,则应保留中断发生的证据,以便调用堆栈上更高的代码能够获悉中断,并在需要时对其做出响应 还请解释一下上面的规则?
-
问题内容: 我在最后一行遇到异常: 我猜这与iPhone 5S是64位而iPhone 5S不是64位有关,但是我在上面的函数中看不到任何处理64位的东西吗? 编辑 通过以下调整,我可以解决此问题,但是我仍然无法解释原因。 问题答案: 的整数类型是在iPhone 5 32位整数,在一个5S 64位整数。由于返回的值是iPhone 5 的正范围的两倍,因此您的第一个版本基本上有50%的机率在此行崩溃:
-
NowCoder 题目描述 从上往下打印出二叉树的每个节点,同层节点从左至右打印。 例如,以下二叉树层次遍历的结果为:1,2,3,4,5,6,7 解题思路 使用队列来进行层次遍历。 不需要使用两个队列分别存储当前层的节点和下一层的节点,因为在开始遍历一层的节点时,当前队列中的节点数就是当前层的节点数,只要控制遍历这么多节点数,就能保证这次遍历的都是当前层的节点。 // java public Ar
-
问题内容: 我正在阅读Java JDBC规范(版本4),并且遇到了以下语句: DataSource-此接口在JDBC 2.0可选软件包API中引入。它优于DriverManager,因为它允许有关基础数据源的详细信息对应用程序透明 我想了解的是a 和a 之间的区别以及它为什么存在。我的意思是,上面的代码块说关于数据源的详细信息对于应用程序是透明的,但是是否不会在属性文件中外部化数据库属性(例如用户
-
我试图理解的是和之间的区别,以及它存在的原因。我的意思是,上面的块表明关于数据源的细节对应用程序是透明的,但是在属性文件中外部化数据库属性如用户名、密码、url等,然后使用DriverManager是否会以同样的方式工作? 创建接口是否只是为了有一种返回可以池化的连接的通用方式?在Java EE中,应用程序服务器是否实现了这个接口,并且部署的应用程序是否具有对数据源的引用而不是连接?