
如何从文本节点中提取文本,隔离表中的标签?

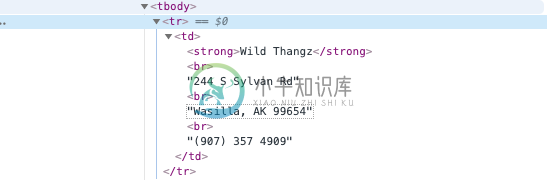
我在打印同一行的表格数据时遇到了问题。当然,我可以用< code>css_selector("td")来标识,但是这样会在同一列中打印出:姓名地址城市/州电话,而我试图在同一行中创建:姓名、地址、城市/州电话
HTML:(见附图)
这似乎是一个非常愚蠢的问题...但是我已经被困了相当长的一段时间,并且无法隔离< code >
代码:
for x in link:
driver.get(x)
try:
i = 0
while 0 < 20:
name = driver.find_elements_by_xpath("/html/body/div[2]/div/div[1]/div/div/table/tbody/tr/td[1]/table/tbody/tr['"+str(i)+"']/td/strong")
if name[i].is_displayed():
print(name[i].text)
i = i + 1
else:
i = i + 1
except(NoSuchElementException,JavascriptException, IndexError):
continue
我以这种方式识别它,试图简单地返回正在进行的兄弟姐妹的文本...再次无济于事。driver.find_elements_by_css_selector("td")还返回整个表数据...但是有了它的中断
共有3个答案

美丽的汤也可以用在这种情况下。
>>>from bs4 import beautifulsoup
>>>import requests
>>>contents=requests.get(url).text
>>>soup=beautifulsoup('lxml',contents)
>>>>Text=soup.find('body').text
并检查是否存在“br”标记,然后跳过

如果您能够识别父
> < li>
名称:
print(WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "td>strong"))).get_attribute("innerHTML"))
地址:
print(driver.execute_script('return arguments[0].childNodes[3].textContent;', WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "td")))).strip())
城市/州:
print(driver.execute_script('return arguments[0].childNodes[5].textContent;', WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "td")))).strip())
电话:
print(driver.execute_script('return arguments[0].lastChild.textContent;', WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "td")))).strip())

tds = driver.find_elements_by_css_selector("td")
for td in tds:
text = td.text.split('\n')
print(text) # list: ['text1', 'text2', 'text3', 'text4']
text = td.text.replace('\n', ' ')
print(text) # str: 'textr text2 text3 text4'
-
我已经复制了某个节点的xpath Chrome返回 //*[@id=“\uuuuuw2\u cEfEsuQ\u列表项目”]/div/div[2]/div/div[1]/div[2]/a[1] 在Chrome控制台中执行此操作将返回 0可以扩展并包含许多子节点(我删除了其中的大部分,因为我在问题中抱怨代码太多),如下所示: 我需要返回和节点的xpath。我在上尝试了不同的变体,但都没有成功。我该怎么
-
问题内容: 我想使用PDFMiner从PDF文件中提取所有文本框和文本框坐标。 其他许多Stack Overflow帖子都介绍了如何以有序方式提取所有文本,但是我该如何做获取文本和文本位置的中间步骤呢? 给定一个PDF文件,输出应类似于: 问题答案: 换行符在最终输出中转换为下划线。这是我发现的最小工作解决方案。
-
问题内容: 我正在尝试使用提取此 PDF文件中包含的文本。 我正在使用PyPDF2模块,并具有以下脚本: 运行代码时,得到以下输出,该输出与PDF文档中包含的输出不同: 如何提取PDF文档中的文本? 问题答案: 要从PDF提取文本,请使用以下代码
-
问题内容: 如何 使用PHP 从PDF文档中提取文本? (我不能使用其他工具,我没有root用户访问权限) 我发现一些函数可用于纯文本,但是它们不能很好地处理Unicode字符: http://www.hashbangcode.com/blog/zend-lucene-and-pdf-documents-part-2-pdf- data-extraction-437.html 问题答案: 下载 c
-
问题内容: 我有一段这样的HTML: 我有一个与此HTML匹配的WebElement。如何从中仅提取“标题”?方法.getText()返回“ Title \ nAuthor”。 问题答案: 您无法在WebDriver API中执行此操作,而必须在代码中执行。例如: 请注意,结尾的换行符实际上是元素文本的一部分,因此,如果您不想要它,则需要将其删除。
-
我有一个Excel工作表,其中一栏填充了专利号。我需要提取每个相应专利的标题,并将其放在专利号旁边的单元格中。因此,代码应执行以下操作: 访问espacenet.com并打开需要名称的专利号。 获取标题。 将其放在所需单元格的Excel工作表中。 这是一个完美适用于第一个专利号的代码,但在这之后会立即出现错误。错误显示:“运行时错误'-2147417848(80010108)': 自动化错误调用的