
在node.js中获取256位AES GCM加密的正确标记时遇到麻烦

我需要编写以下解密函数的反向(加密):
const crypto = require('crypto');
let AESDecrypt = (data, key) => {
const decoded = Buffer.from(data, 'binary');
const nonce = decoded.slice(0, 16);
const ciphertext = decoded.slice(16, decoded.length - 16);
const tag = decoded.slice(decoded.length - 16);
let decipher = crypto.createDecipheriv('aes-256-gcm', key, nonce);
decipher.setAuthTag(tag)
decipher.setAutoPadding(false);
try {
let plaintext = decipher.update(ciphertext, 'binary', 'binary');
plaintext += decipher.final('binary');
return Buffer.from(plaintext, 'binary');
} catch (ex) {
console.log('AES Decrypt Failed. Exception: ', ex);
throw ex;
}
}
上面的函数允许我按照规范正确解密加密缓冲区:
| Nonce/IV (First 16 bytes) | Ciphertext | Authentication Tag (Last 16 bytes) |
aesdecrypt之所以以它的方式编写(auth标记为最后16个字节),是因为AES的默认标准库实现就是这样在Java和Go中加密数据的。我需要能够在Go、Java和node.js之间双向解密/加密。node.js中基于crypto库的加密不会将身份验证标记放在任何地方,开发人员希望如何存储身份验证标记,以便在解密期间传递给setauthtag()。在上面的代码中,我正在将标记直接烘焙到最终加密的缓冲区中。
let AESEncrypt = (data, key) => {
const nonce = 'BfVsfgErXsbfiA00'; // Do not copy paste this line in production code (https://crypto.stackexchange.com/questions/26790/how-bad-it-is-using-the-same-iv-twice-with-aes-gcm)
const encoded = Buffer.from(data, 'binary');
const cipher = crypto.createCipheriv('aes-256-gcm', key, nonce);
try {
let encrypted = nonce;
encrypted += cipher.update(encoded, 'binary', 'binary')
encrypted += cipher.final('binary');
const tag = cipher.getAuthTag();
encrypted += tag;
return Buffer.from(encrypted, 'binary');
} catch (ex) {
console.log('AES Encrypt Failed. Exception: ', ex);
throw ex;
}
}
此外,我知道这个问题与aesencrypt的以下行有关:
const tag = cipher.getAuthTag();
encrypted += tag;
对在Go和node.js中加密的同一个文件运行vbindiff时,文件开始显示的差异仅限于最后16个字节(在那里写入了验证标记get)。换句话说,Go和Node.js中的nonce和加密的有效负载是相同的。
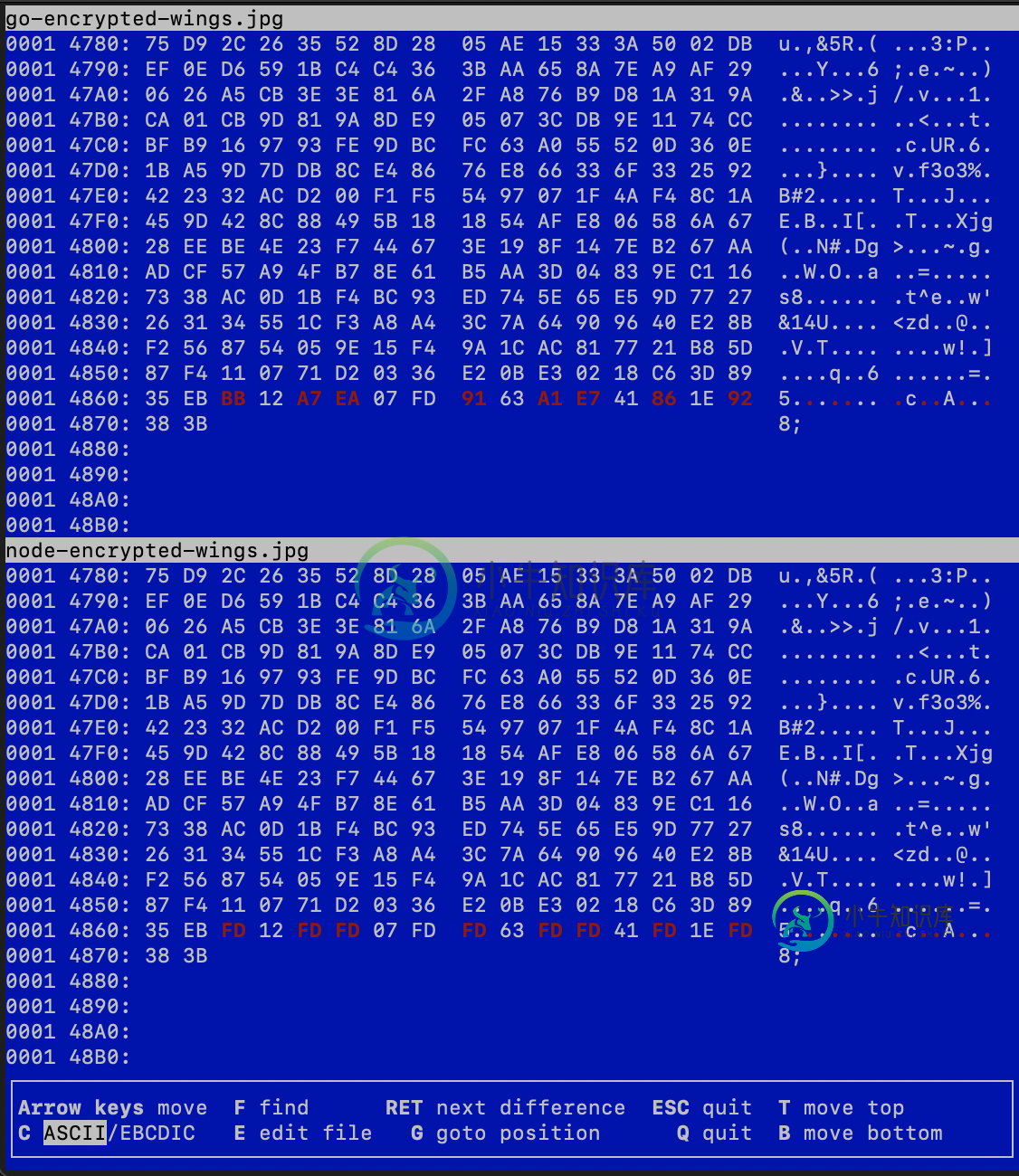
由于getauthtag()非常简单,而且我相信我正确地使用了它,所以我不知道现在可以更改什么。因此,我还考虑了这是标准库中的一个bug的可能性。但是,我想在发布Github问题之前应该先尝试Stackoverflow,因为这很可能是我做错了。
共有1个答案

在NodeJS代码中,密文生成为二进制字符串,即使用binary/Latin1或ISO-8859-1编码。ISO-8859-1是一个单字节字符集,它唯一地将0x00和0xFF之间的每个值分配给一个特定字符,因此允许将任意二进制数据转换为字符串而不损坏,参见此处。
相反,cipher.getauthTag()不将身份验证标记作为二进制字符串返回,而是作为缓冲区返回。
当将两个部分连接在一起时:
encrypted += tag;
return Buffer.from(encrypted, 'binary');
仅考虑替换字符的最后一个字节(0xFD)。
屏幕截图中标记的字节(0xBB、0xA7、0xEA等)都是无效的UTF-8字节序列。UTF-8表,因此被带有0xFD的NodeJS代码替换,从而导致损坏的标记。
要修复该错误,必须将标记转换为binary/latin1,即与密文的编码一致:
let AESEncrypt = (data, key) => {
const nonce = 'BfVsfgErXsbfiA00'; // Static IV for test purposes only
const encoded = Buffer.from(data, 'binary');
const cipher = crypto.createCipheriv('aes-256-gcm', key, nonce);
let encrypted = nonce;
encrypted += cipher.update(encoded, 'binary', 'binary');
encrypted += cipher.final('binary');
const tag = cipher.getAuthTag().toString('binary'); // Fix: Decode with binary/latin1!
encrypted += tag;
return Buffer.from(encrypted, 'binary');
}
let AESEncrypt_withBuffer = (data, key) => {
const nonce = 'BfVsfgErXsbfiA00'; // Static IV for test purposes only
const encoded = Buffer.from(data, 'binary');
const cipher = crypto.createCipheriv('aes-256-gcm', key, nonce);
return Buffer.concat([ // Fix: Concatenate buffers!
Buffer.from(nonce, 'binary'),
cipher.update(encoded),
cipher.final(),
cipher.getAuthTag()
]);
}
-
问题内容: 这可能是一个非常琐碎的问题。我试图通过给予NLTK使用斯坦福POS恶搞这里的问题是,我NLTK的lib犯规包含斯坦福模块。因此,我将其复制到相应的文件夹中并进行了编译。现在,当我尝试运行示例时,将检测到模块,但未检测到模块内的类。谁能告诉我我要去哪里错了吗?同样,这可能是非常愚蠢的。 我使用py_compile编译stanford.py文件。我错过了什么吗 问题答案: 您仅在导入。要访
-
就像我说的,一切都很好,除了这个小的decypt...我搜索了谷歌和所有的东西,尝试了示例代码,但似乎我的代码有些东西不对。
-
我有以下java代码用于加密纯文本:
-
我正在从一个文件中读取文本,但在试图将和读入两个不同的时遇到了困难。指示第一个列表的结束位置。我试过使用数组,但数组只存储最后一个*符号。 以下是我目前尝试的方法:
-
问题内容: 试图了解如何在Go中解组XML。通读多个示例和stackoverflow问题。我想要的是一个切片,其中包含系统上安装的所有修补程序。我什至无法解开补丁,没有错误,只是一片空白。可能所做的事情基本上是错误的,在此先感谢您的任何建议。 问题答案: 我认为您遇到的问题是程序包未填充未导出的字段。xml文档说: 因为Unmarshal使用了反射包,所以它只能分配给导出的(大写)字段。 您要做的
-
问题内容: 我需要实现256位AES加密,但是我在网上找到的所有示例都使用“ KeyGenerator”来生成256位密钥,但是我想使用自己的密码。如何创建自己的密钥?我尝试将其填充到256位,但是随后出现错误消息,提示密钥太长。我确实安装了无限管辖权补丁,所以那不是问题:) 就是 KeyGenerator看起来像这样… 从这里获取的代码 编辑 我实际上是将密码填充到256个字节而不是位,这太长了