
使用spark-submit部署应用程序:应用程序已添加到调度程序,但尚未激活

我有带Linux Centos 12g内存的VirtualBox。我需要将2个应用程序部署到以非分布式配置运行的hadoop中。这是我的纱线配置:
<configuration>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>0.0.0.0:8032</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>130</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>1</value>
<description>Ratio between virtual memory to physical memory when
setting memory limits for containers</description>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>1</value>
</property>
</configuration>
我部署第一个应用程序并使其正确运行:
spark-submit--主纱--部署模式客户端--名称oryxbatchlayer-alsexample-class com.cloudera.oryx.batch.main--文件oryx.conf--驱动程序--内存500M--驱动程序-java-options“-dconfig.file=oryx.conf”--executor-memory 500M--executor-cores 1--conf spark.executor.extrajavaoptions=“-dconfig.file=oryx.conf”--conf spark.io.compression.codec=lzf--conf
8088处的纱线管理器指示我正在使用8个vCore中的2个和8G内存中的2个:
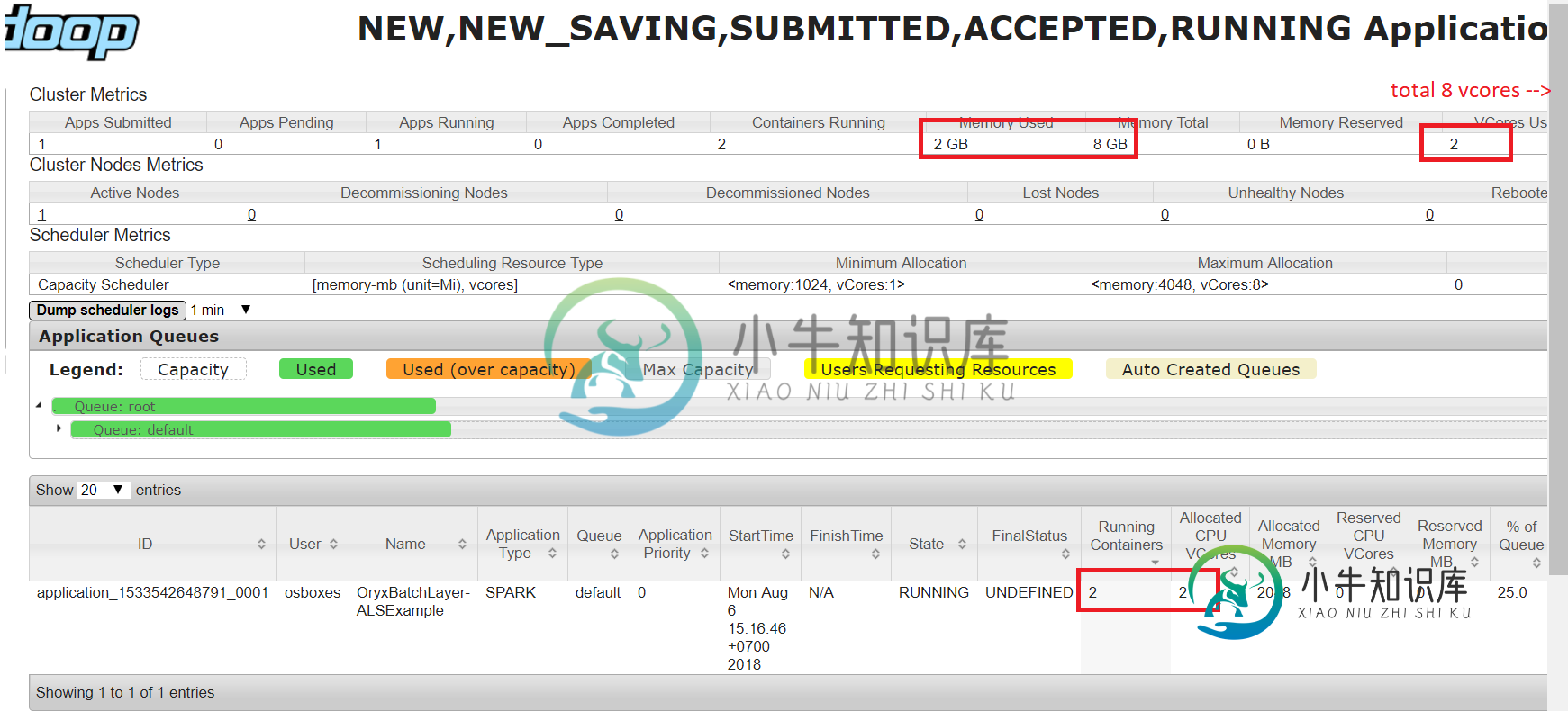
现在我部署第二个应用程序:
spark-submit--主纱--部署模式客户端--名称oryxspeedlayer-alsexample-class com.cloudera.oryx.speed.main--文件oryx.conf--驱动程序--内存500M--驱动程序-java-options“-dconfig.file=oryx.conf”--executor-memory 500M--executor-cores 1--conf spark.executor.extrajavaoptions=“-dconfig.file=oryx.conf”--conf spark.io.compression.codec=lzf--conf
但这一次我得到了一个警告,似乎第二个应用程序被冻结了,至少它没有分配内存:
2018-08-06 04:49:10信息客户端:54-客户端令牌:N/A诊断:[Mon Aug 06 04:49:09-0400 2018]应用程序已添加到计划程序,但尚未激活。超过队列的AM资源限制。细节:AM分区=;AM资源请求=;AM=的队列资源限制;队列的用户AM资源限制=;队列AM资源使用量=;ApplicationMaster主机:n/a ApplicationMaster RPC端口:-1队列:默认开始时间:1533545349902最终状态:未定义跟踪URL:http://master:8088/proxy/application_1533542648791_0002/user:osboxs
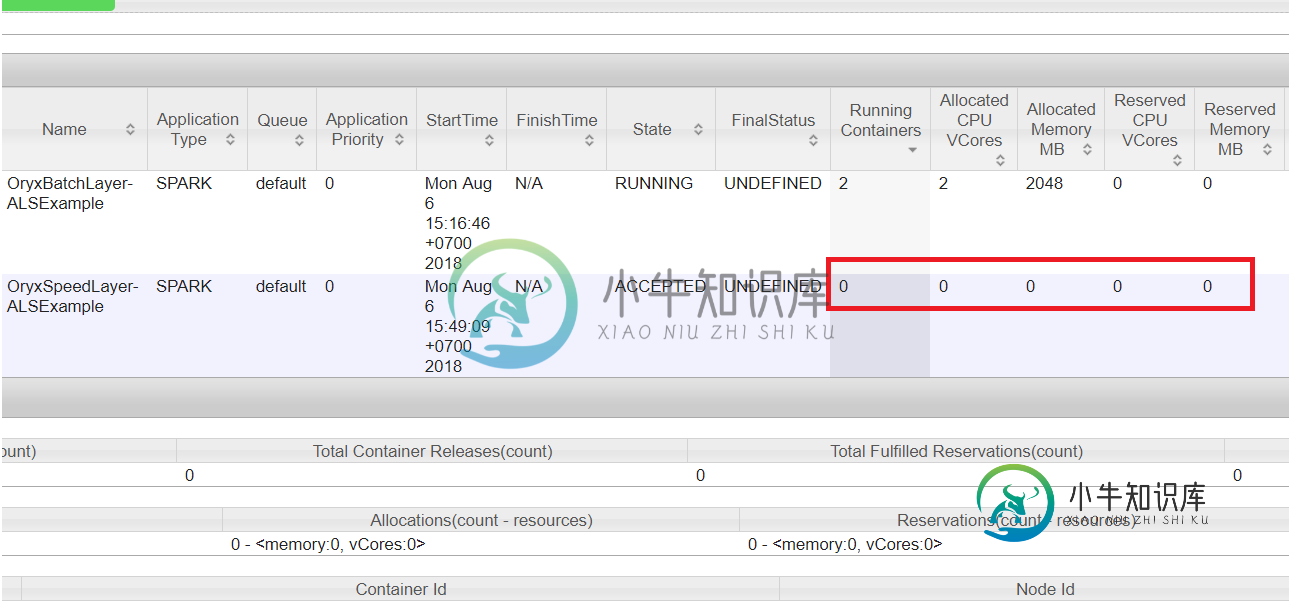
问题的根源是什么?如何增加队列的AM资源限制和用户AM资源限制?
共有1个答案

修复方法是编辑
~/hadoop-3.1.0/etc/hadoop/capacity-scheduler.xml
和更新。1到1:
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>1</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>
-
我正在尝试将一个.ear应用程序部署到WildFly10.1Final。ear有2个嵌套的.war文件。war文件中没有“jboss-web.xml”文件。 信息[org.jboss.as.server.deployment.scanner](DeploymentScanner-Threads-1)WFLYDS0004:在部署目录中找到MyApp.ear。要触发部署,请创建一个名为myapp.ea
-
我是Spark的新手。我有一个应用程序,通过调用spark shell来运行每个spark sql查询。因此,它将生成一组如下所示的查询,并调用spark shell命令逐个处理这些查询。 Val Query=spark.sql(""SELECT userid as userid,评级为评级,电影为电影从default.movie表""); 现在我想用spark submit而不是spark sh
-
Requirements 运行一个Spark Streaming应用程序,有下面一些步骤 有管理器的集群-这是任何Spark应用程序都需要的需求,详见部署指南 将应用程序打为jar包-你必须编译你的应用程序为jar包。如果你用spark-submit启动应用程序,你不需要将Spark和Spark Streaming打包进这个jar包。 如果你的应用程序用到了高级源(如kafka,flume),你需
-
[错误]无法执行目标组织。阿帕奇。专家插件:maven编译器插件:3.8。1:在project Divi up后端上编译(默认编译):编译时出现致命错误:目标版本无效:15- 我得到了上面的错误,有人知道为什么会这样吗?
-
我运行< code>heroku open时出现应用程序错误。我查了日志,这是: 2016-06-19T05:22:44.640391 00:00 heroku[路由器]:at=错误代码=H10 desc=“应用程序崩溃”方法=获取路径=“/”主机=drawparty-.herokuapp。com request_id=6712804b-95f9-49ce-92a5-7f45df7bb79e fw
-
我试图在NetBeans中构建一个可以部署到用户和最终用户的应用程序。我对部署项目还是相当陌生的,这是迄今为止我做过的最复杂的一个,所以请容忍我。我目前在NetBeans中有一个工作应用程序,它利用JDK15和JavaFX15。只要我在NetBeans内部运行,一切都会按预期运行。我已经到了我想确保我可以在NetBeans之外发布这个应用程序的地步。为此,我进行了一些搜索,找到了以下教程。 htt