
在Spark中阶段是如何拆分为任务的?

下面我们假设每个时间点只有一个Spark作业在运行。
以下是我所理解的在Spark中发生的事情:
- 创建
sparkcontext时,每个工作节点都启动一个执行器。执行程序是单独的进程(JVM),它连接回驱动程序。每个执行器都有驱动程序的jar。退出驱动程序,关闭执行程序。每个执行程序可以保存一些分区。 - 执行作业时,将根据沿袭图创建执行计划。
- 执行作业被拆分为多个阶段,其中阶段包含相同数量的相邻转换和操作(在沿袭图中),但不包含洗牌。这样,阶段就被洗牌分开了。
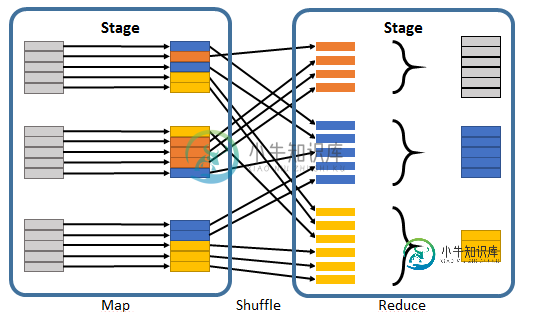
-
null
但是
我如何将阶段划分为那些任务?
具体地说:
-
null
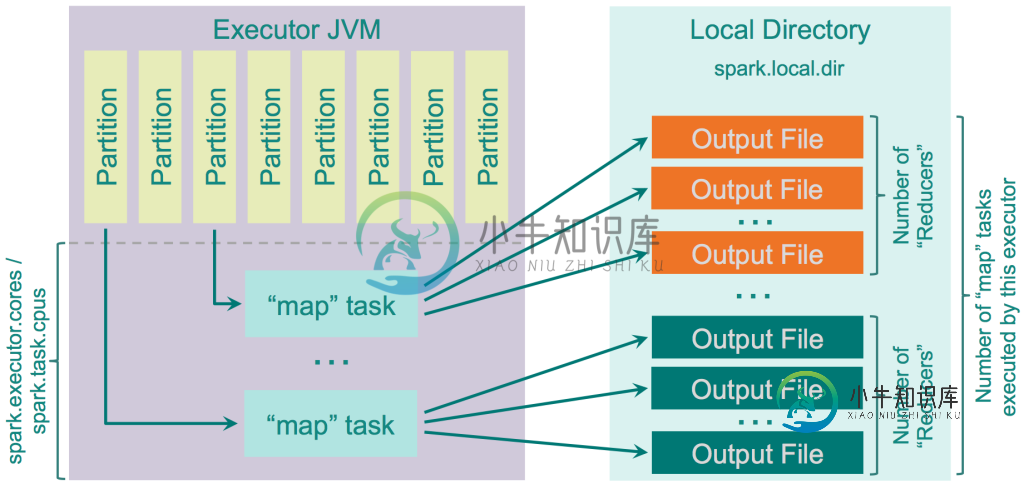
那是正确的吗?但是即使那是正确的,我上面的问题也没有全部得到回答,因为它仍然是开放的,多个操作(例如多个映射)是在一个任务内,还是每个操作被分离成一个任务。
火花中的任务是什么?Spark worker如何执行jar文件?Apache Spark调度器如何将文件拆分为任务?但我觉得我的问题没有得到清楚的回答。
共有1个答案

你的轮廓很不错。回答你的问题
- 需要为每个
阶段的每个数据分区启动单独的任务。考虑每个分区可能驻留在不同的物理位置上-例如HDFS中的块或本地文件系统的目录/卷。
请注意,stages的提交是由DAG调度程序驱动的。这意味着不相互依赖的阶段可能会被提交到集群中并行执行:这使得集群上的并行化能力最大化。因此,如果我们的数据流中的操作可以同时发生,我们将期望看到多个阶段启动。
-
null
- 用于并行加载两个数据源的各1级=2级
- 表示
连接的第三阶段,它依赖于其他两个阶段 - 注意:所有对连接的数据进行的后续操作都可能在同一阶段中执行,因为它们必须顺序发生。启动其他阶段没有任何好处,因为在完成前一个操作之前,这些阶段无法开始工作。
这是玩具程序
val sfi = sc.textFile("/data/blah/input").map{ x => val xi = x.toInt; (xi,xi*xi) }
val sp = sc.parallelize{ (0 until 1000).map{ x => (x,x * x+1) }}
val spj = sfi.join(sp)
val sm = spj.mapPartitions{ iter => iter.map{ case (k,(v1,v2)) => (k, v1+v2) }}
val sf = sm.filter{ case (k,v) => v % 10 == 0 }
sf.saveAsTextFile("/data/blah/out")
这是结果的DAG
-
在这里,我想知道三件事,关于如何将一个阶段拆分为任务? > 在上面的例子中,任务数似乎是根据文件数创建的,对吗? 如果我在第1点上是正确的,那么如果目录名下只有3个文件,它会创建3个任务吗? 非常感谢,我感到困惑的是,这个阶段是如何被分割成任务的。
-
假设我正在从S3文件夹中读取100个文件。每个文件的大小为10 MB。当我执行<code>df=spark.read时。parquet(s3路径),文件(或更确切地说分区)如何在任务之间分布?E、 g.在这种情况下,<code>df</code>将有100个分区,如果spark有10个任务正在运行以将该文件夹的内容读取到数据帧中,那么这些分区是如何分配给这10个任务的?它是以循环方式进行的,还是每
-
我看到分区中的行数和任务的执行时间之间有明显的相关性。由于我的数据集具有无法更改的偏斜性质,我有几个分区,其元素数(>8000)远高于平均值(~3000)。一个分区的平均执行时间为10-20分钟,较大的可达3小时以上。我的一些最大的分区具有较高的,因此相应的任务几乎是在阶段结束时执行的。结果,其中一个Spark阶段在最后5个任务上挂起3个小时。 问题: 是否有一种方法可以重新排序分区的,以便首先执
-
我有一个Spark UDF,它需要在executor的本地磁盘上安装一个特定的文件(在我的例子中是MATLAB运行时)(我们使用的是YARN)。因为我不能直接访问executor机器,所以我必须找到另一种方法在集群上部署我的运行时。由于文件非常大,我不能在每次调用UDF时安装/删除它,所以我考虑了以下策略: null 似乎没有办法为执行者添加关机钩子(Spark worker shutdown-如
-
我有一个Gradle任务,简单地将文件从一个文件夹复制到另一个文件夹。 当在配置阶段调用copy'from''into'方法时,它可以工作,但当在执行阶段调用它们时,它就不工作了。 这样做是有效的 gradle copyServerConfig 如果我把它放在doFirst{}块中,也会发生同样的事情。 我不明白的另一件事是: gradle task1 但如果我改成这样: gradle task1
-
我有一个gradle脚本,其中我使用变量配置了一个插件(在我的例子中是ospackage,但我想这同样适用于另一个插件),如下所示: 首先初始化该变量,然后使用我在构建脚本中首先调用的任务更新该变量: 问题是插件(在我的例子中是ospackage)总是考虑初始值“xxx”,而不是通过执行init任务设置的正确值。我知道这与配置和执行阶段有关,但我仍然找不到一个变通方法来做我想做的事情。 为了了解信