
在使用uid将流拆分到作业时闪烁,重新平衡

我是一个新的flink和即将载入我们的第一个生产版本。我们有一个数据流。状态筛选器正在检查数据是否为新数据。
dataStream
.uid("firstid")
.keyBy(0)
.flatMap(flatMapFunction)
.uid("mappedId)
共有1个答案

您只需要为您的有状态运算符定义.uid(“somename”)。不太需要不保持状态的运算符,因为保存点中没有任何东西需要映射回它们(这里有更多内容)。即使你这么做也不会有什么坏处。rebalance只在存在数据偏斜的情况下才会帮助您,而且只有在您不使用键控流的情况下才会这样。如果您基于一个键处理数据,并且您的负载不是均匀地分布在您的键上(即您有“热”键的负载),那么重新平衡对您没有太大帮助。
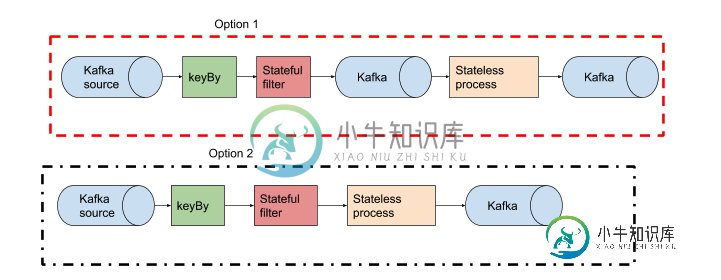
在上面的示例中,如果工作太重,我将启动选项2,并可能转到选项1。通常,无状态进程在Flink中是非常快的,所以除非您想将其他使用者添加到有状态过滤器的输出中,否则就不必费心在这个阶段将其拆分。但是没有对错,这取决于你的问题。从简单开始,从那里开始。
[Update]Re 4,setmaxParallelism(如果我没有弄错的话)定义了密钥组的数量,从而定义了流可以重新缩放到的最大并行实例数。这是Flink在内部使用的,但它不设置工作的并行性。您通常必须将其设置为您为作业设置的实际并行度的一些倍数(在部署作业时,通过CLI/UI中的-p
)。
-
我有一个使用Apache Flink(Flink版本:1.8.1)使用Scala进行流式处理的工作。flow作业要求如下:Kafka->写给Hbase->用不同的主题再次发送给Kafka 在向Hbase写入过程中,需要从另一个表中检索数据。为确保数据不为空(NULL),作业必须(在一定时间内)重复检查数据是否为空。 编辑:我的意思是,有了我在内容中描述的问题,我想过必须在作业流中创建某种类型的作业
-
我想运行流作业。 当我尝试使用和Flink Web界面在本地运行该作业时,没有问题。 但是,我当前正在尝试使用Flink on YARN(部署在Google Dataproc上)运行我的作业,并且当我尝试取消它时,取消状态将永远持续,并且TaskManager中仍有一个插槽被占用。 这是我得到的日志:
-
我有一个flink流媒体作业,它从Kafka读取数据并写入文件系统中适当的分区。例如,作业被配置为使用一个bucketing接收器,该接收器写入/数据/日期=${date}/小时=${hour}。 如何检测分区是否已准备好使用,以便相应的气流管道可以在这一小时内进行批处理?
-
我试图在Flink中编写一个需要两个阶段的计算。 在第一阶段,我创建一个Graph并获取它的顶点id: 在第二阶段,我想使用这些ID为每个顶点运行SingleSourceShortestPath。 它在本地工作(在IntelliJ IDE和命令行中使用),但当我使用其WebUI在Flink上提交作业时,程序只是执行直到方法并且不运行程序的剩余部分(用于语句和)。 问题是什么? 这是我的代码:
-
我有一个关于在Kinesis流中分片数据的问题。我想在向我的kinesis流发送用户数据时使用一个随机分区键,这样碎片中的数据是均匀分布的。为了使这个问题更简单,我想通过在Flink应用程序中键入用户ID来聚合用户数据。
-
我正在运行一个简单的示例来测试基于EventTime的Windows。我能够生成带有处理时间的输出,但当我使用EventTime时,没有输出。请帮助我明白我做错了什么。