
在访问第一个元素--Webscraping Selenium Python之后,无法在循环中通过xpaths访问其余元素

我试图从sciencedirect网站上搜索数据。我试图通过创建一个xpaths列表并循环这些xpaths来一个接一个地访问journal issues,从而自动化刮痧过程。当im运行该循环时,im在访问第一个日记之后无法访问其余的元素。这个过程对我在另一个网站工作,但不是在这个。
我还想知道除了这个过程之外,还有什么更好的方法来访问这些元素。
#Importing libraries
import requests
import os
import json
from selenium import webdriver
import pandas as pd
from bs4 import BeautifulSoup
import time
import requests
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
#initializing the chromewebdriver|
driver=webdriver.Chrome(executable_path=r"C:/selenium/chromedriver.exe")
#website to be accessed
driver.get("https://www.sciencedirect.com/journal/journal-of-corporate-finance/issues")
#generating the list of xpaths to be accessed one after the other
issues=[]
for i in range(0,20):
docs=(str(i))
for j in range(1,7):
sets=(str(j))
con=("//*[@id=")+('"')+("0-accordion-panel-")+(docs)+('"')+("]/section/div[")+(sets)+("]/a")
issues.append(con)
#looping to access one issue after the other
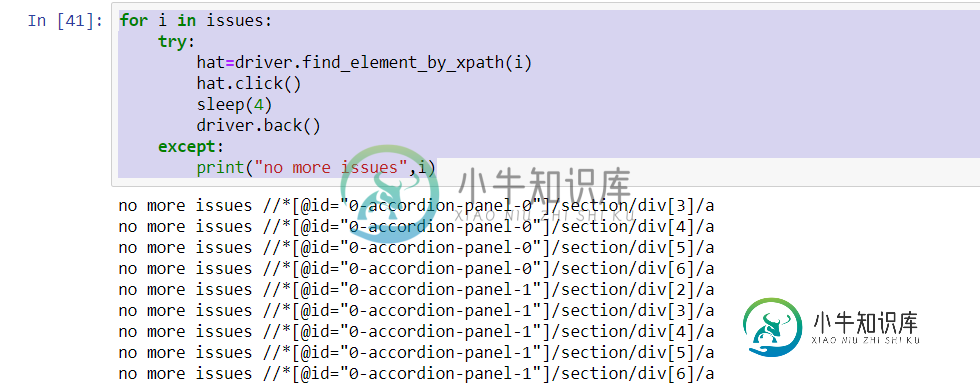
for i in issues:
try:
hat=driver.find_element_by_xpath(i)
hat.click()
sleep(4)
driver.back()
except:
print("no more issues",i)
共有1个答案

要从sciencedirect网站https://www.sciencedirect.com/journal/journal-of-composition-finance/issures中获取数据,可以执行以下步骤:
>
先打开所有的手风琴。
然后使用Ctrl+click()在adjustant选项卡中打开每个问题。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
options = webdriver.ChromeOptions()
options.add_argument("start-maximized")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=options, executable_path=r'C:\Utility\BrowserDrivers\chromedriver.exe')
driver.get('https://www.sciencedirect.com/journal/journal-of-corporate-finance/issues')
accordions = WebDriverWait(driver, 30).until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR, "li.accordion-panel.js-accordion-panel>button.accordion-panel-title>span")))
for accordion in accordions:
ActionChains(driver).move_to_element(accordion).click(accordion).perform()
issues = WebDriverWait(driver, 30).until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR, "a.anchor.js-issue-item-link.text-m span.anchor-text")))
windows_before = driver.current_window_handle
for issue in issues:
ActionChains(driver).key_down(Keys.CONTROL).click(issue).key_up(Keys.CONTROL).perform()
WebDriverWait(driver, 10).until(EC.number_of_windows_to_be(2))
windows_after = driver.window_handles
new_window = [x for x in windows_after if x != windows_before][0]
driver.switch_to_window(new_window)
WebDriverWait(driver, 30).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "a#journal-title>span")))
print(WebDriverWait(driver, 30).until(EC.visibility_of_element_located((By.XPATH, "//h2"))).get_attribute("innerHTML"))
driver.close()
driver.switch_to_window(windows_before)
driver.quit()
Institutions, Governance and Finance in a Globally Connected Environment
Volume 58
Corporate Governance in Multinational Enterprises
.
.
.
您可以在以下内容中找到一些相关的详细讨论:
- 如何使用Selenium WebDriver的控件+单击,在主选项卡中,在同一窗口的新选项卡中打开嵌入在webelement中的链接
- 如何在webtable中打开多个hrefs
- 在Python中使用Selenium WebScraping JavaScript呈现的内容
- StaleElementReferenceException,即使在使用Web搜索从维基百科收集数据时添加了等待
- 如何通过Python使用Selenium在新选项卡中打开网站中的每个产品
-
问题内容: 我对如何在Java中执行此操作有一般的想法,但是我正在学习Python,但不确定如何执行。 我需要实现一个函数,该函数返回一个包含列表中所有其他元素的列表,从第一个元素开始。 到目前为止,我不确定从这里开始该怎么做,因为我只是在学习Python中的for循环是如何不同的: 问题答案:
-
问题内容: 我有一个网页,其中iframe内有一个文本区域。我需要使用JavaScript从其子页面读取此textarea的值。 目前,通过在JavaScript中使用,我能够在iframe中获取父页面中除textarea之外的所有控件的值。 任何人都可以给我任何指示以解决此问题吗? 问题答案: 如果您的iframe与父页面位于同一域中,则可以使用collection 访问元素。 如果您的ifra
-
在实现selenium测试之前,我尝试在工作中为selenium测试解决一个recaptcha。 我使用的用例:https://www.google.com/recaptcha/api2/demo 系统也是如此。我试图找到验证码令牌,但每次它都返回null元素。到目前为止,硒的主要作用是: Bys. CssSelector等也是如此。 我已经在正确的IFrame中了,因为页面源已正确打印出来,但通
-
我是javafX的新手,通过了各种教程,并在Googles上进行了大量搜索。我正在尝试编写一个多屏幕javaFX程序,它的第二个屏幕有一个拆分窗格,其右窗格应该显示一个网格和一个按钮。我用于多屏幕的框架复制自Angela Caiedo的MultipleScreens框架教程(https://github.com/acaicedo/jfx-multiscreen/tree/master/screen
-
问题内容: 我正在从URL获取天气信息。 我得到的是: 如何访问所需的任何元素? 如果我这样做:我收到错误消息: 字符串索引必须是整数,而不是str。 问题答案: 您从url中获得的是一个json字符串。而且您不能直接用索引解析它。您应该将其转换为dict ,然后可以使用index对其进行解析。 与其使用中间方式将其保存到内存,然后将其读取为,不如直接从文件中加载它:
-
[ ]操作符可以对向量进行读和写,这和apstring访问字符类似。同样和apstring一样,索引从0开始,count[ 0 ]指的是向量中的第0个元素,count[ 1 ]指的是向量中的第1个元素。[ ]操作符可以应用在任何表达式中。 count[0] = 7; count[1] = count[0] * 2; count[2]++; count[3] -= 60; 所有的这些语句都是合法的