
如何从列表中找到前10排遮阳篷。CSV文件,并将结果存储在新文件中。使用Python的CSV文件?

从2年的数据中,找到AWND的前10个读数/行。将结果存储在文件中。csv文件并将其命名为top10AWND. csv。新文件将包含filteredData.csv的所有列,但只有前10个AWND。
过滤的一小部分ata.csv:
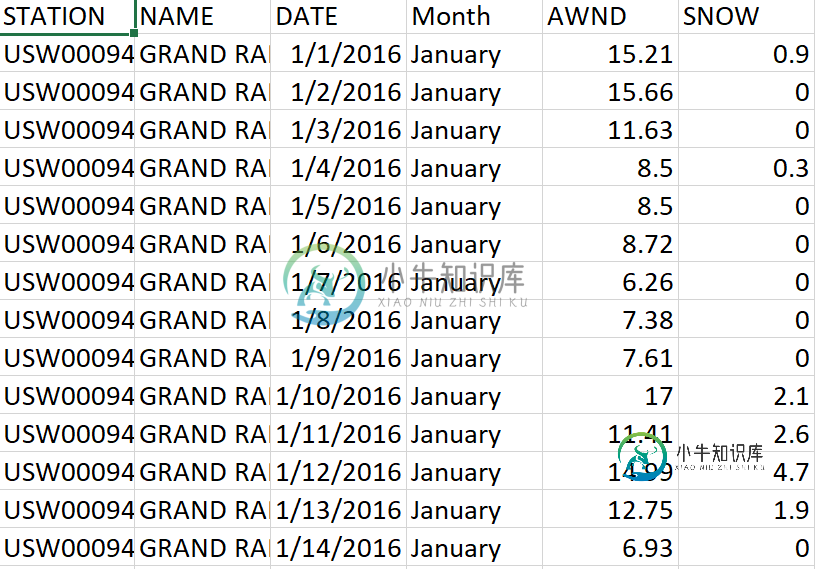
我正在使用Python 3.8和Pandas。
我需要从我的Filteredata中找到AWND的前10个读数。csv文件。然后,我需要将结果存储在一个新文件中。新文件需要包含前10个读数的列、站、名称、数据、月份、雨天和雪。
我不知道该怎么做。这是我到目前为止所做的,它不起作用。它给了我错误。我遇到的一个错误是TyperError:列表索引必须是整数或切片,而不是代码中过滤的_weather=行的列表。
import numpy as np
import pandas as pd
import re
for filename in ['filteredData.csv']:
file = pd.read_csv(filename)
all_loc =dict(file['AWND'].value_counts()).keys()
most_loc = list(all_loc)[:10]
filtered_weather = ['filteredData.csv'][['STATION','NAME','DATE','Month','AWND','SNOW']] #Select the column names that you want
filtered_weather.to_csv('top10AWND.csv',index=False)
共有1个答案

你可以这样做:
#This not neccessary unless you want to read several files
for filename in ['filteredData.csv']:
file = pd.read_csv(filename)
file = file.sort_values('AWND', ascending = False).head(10)
# If it's only one file you can do
#
#file = pd.read_csv(filename)
#file = file.sort_values('AWND', ascending = False).head(10)
#Considering you want to keep all the columns you can just write the dataframe to the file
file.to_csv('top10AWND.csv',index=False)
-
问题内容: import csv 我得到奇怪的输出!此代码有什么问题? 问题答案: 用途:
-
对文件中的数据进行排序average2016。csv和平均值2017。csv。仅存储每个文件中前3个位置。前3个位置的数据将存储在一个文件中,命名为top3。csv。前三名中的每一列。csv文件将存储每年的结果。因此,排名前三。csv文件将包含2016列和2017列。 我正在使用Python 3.8与熊猫 我不知道该怎么办。我需要对这些文件中的数据进行排序。我只需要存储每个位置的前3个位置。CSV
-
此函数返回以下内容: 我想让我的python脚本可以将股票历史数据保存到一个csv文件中,这样我就可以在以后的项目中使用它。我试着用csv模块做这件事,但是找不到任何与我正在尝试做的事情相匹配的东西。是否有任何方法可以将这些数据存储到一个新的csv文件中,而不需要一个现有的文件。
-
问题内容: 我有一个列表列表,我想将其写入csv文件中。示例列表: data [0]应该是列名,其他都是行数据 请给我建议一种方法。 问题答案: 这与模块无关紧要: 您已经具有标题作为第一行;您可以使用该方法一次性写入所有行。真的,这就是全部。
-
我试图从csvfile中编写两个txt文件(Test_8.txt和Test_9.txt)。从COL4行我得到单引号和双引号以及“[”。 我怎样才能摆脱他们?
-
问题内容: 我有几个CSV文件,如下所示: 我想在所有CSV文件中添加一个新列,使其看起来像这样: 到目前为止,我的脚本是: (Python 3.2) 但是在输出中,脚本跳过了每一行,新列中仅包含Berry: 问题答案: 这应该使您知道该怎么做: 编辑,注意在py3k中必须使用 感谢您接受答案。在这里,您有一个好处(您的工作脚本): 请注意 中的参数。默认情况下,它设置为,这就是为什么间距为两倍的