
如何使用自定义格式的Apache Beam将BigQuery结果以JSON格式写入GCS?

我正在尝试使用python中的ApacheBeam将BigQuery表记录作为JSON文件写入GCS桶中。
我有一个大查询表-< code > my _ project . my _ dataset . my _ table ,如下所示
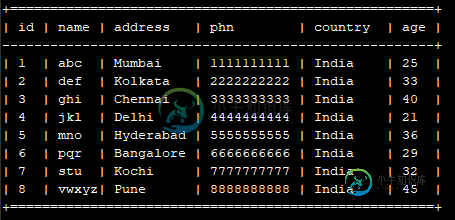
我希望将表记录/条目写入一个JSON文件中的GCS存储桶位置-“GS://my _ core _ bucket/data/my _ data . JSON”
预期的 JSON 格式:
[
{"id":"1","values":{"name":"abc","address":"Mumbai","phn":"1111111111"}},
{"id":"2","values":{"name":"def","address":"Kolkata","phn":"2222222222"}},
{"id":"3","values":{"name":"ghi","address":"Chennai","phn":"3333333333"}},
{"id":"4","values":{"name":"jkl","address":"Delhi","phn":"4444444444"}}
]
但是,在我当前的apache pipeline实现中,我看到创建的JSON文件在文件“GS://my _ core _ bucket/data/my _ data . JSON”中有这样的条目
{"id":"1","values":{"name":"abc","address":"Mumbai","phn":"1111111111"}}
{"id":"2","values":{"name":"def","address":"Kolkata","phn":"2222222222"}}
{"id":"3","values":{"name":"ghi","address":"Chennai","phn":"3333333333"}}
{"id":"4","values":{"name":"jkl","address":"Delhi","phn":"4444444444"}}
如何创建一个干净的JSON文件,其中BigQuery记录作为JSON数组元素?
这是我的管道代码。
import os
import json
import logging
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
class PrepareData(beam.DoFn):
def process(self, record): # sample record - {"id": "1", "name": "abc", "address": "Mumbai", "phn": "1111111111"}
rec_columns = [ "id", "name", "address", "phn", "country", "age"] # all columns of the bigquery table
rec_keys = list(record.keys()) # ["id", "name", "address", "phn"] # columns needed for processing
values = {}
for x in range(len(rec_keys)):
key = rec_keys[x]
if key != "id" and key in rec_columns:
values[key] = record[key]
return [{"id": record['id'], "values": values}]
class MainClass:
def run_pipe(self):
try:
project = "my_project"
dataset = "my_dataset"
table = "my_table"
region = "us-central1"
job_name = "create-json-file"
temp_location = "gs://my_core_bucket/dataflow/temp_location/"
runner = "DataflowRunner"
# set pipeline options
argv = [
f'--project={project}',
f'--region={region}',
f'--job_name={job_name}',
f'--temp_location={temp_location}',
f'--runner={runner}'
]
# json file name
file_name = "gs://my_core_bucket/data/my_data"
# create pipeline
p = beam.Pipeline(argv=argv)
# query to read table data
query = f"SELECT id, name, address, phn FROM `{project}.{dataset}.{table}` LIMIT 4"
bq_data = p | 'Read Table' >> beam.io.Read(beam.io.ReadFromBigQuery(query=query, use_standard_sql=True))
# bq_data will be in the form
# {"id": "1", "name": "abc", "address": "Mumbai", "phn": "1111111111"}
# {"id": "2", "name": "def", "address": "Kolkata", "phn": "2222222222"}
# {"id": "3", "name": "ghi", "address": "Chennai", "phn": "3333333333"}
# {"id": "4", "name": "jkl", "address": "Delhi", "phn": "4444444444"}
# alter data in the form needed for downstream process
prepared_data = bq_data | beam.ParDo(PrepareData())
# write formatted pcollection as JSON file
prepared_data | 'JSON format' >> beam.Map(json.dumps)
prepared_data | 'Write Output' >> beam.io.WriteToText(file_name, file_name_suffix=".json", shard_name_template='')
# execute pipeline
p.run().wait_until_finish()
except Exception as e:
logging.error(f"Exception in run_pipe - {str(e)}")
if __name__ == "__main__":
main_cls = MainClass()
main_cls.run_pipe()
共有2个答案

您可以直接在BigQuery中执行,只需使用Dataflow打印结果即可。
仅更改查询
query = f"Select ARRAY_AGG(str) from (SELECT struct(id as id, name as name, address as address, phn as phn) as str FROM `{project}.{dataset}.{table}` LIMIT 4)"
请记住
- BigQuery 处理总是比数据流处理(或同等芯片上的其他处理)更快、更便宜。
- 数据流将始终生成有效的 JSON(JSON 无效,无法从数组开始)

正如评论中所建议的,请尝试将所有结果合并为一个。为了成功地序列化作为组合过程的结果而获得的< code>set,可以使用自定义序列化程序。
您的代码可能如下所示:
import os
import json
import logging
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
# Based on https://stackoverflow.com/questions/8230315/how-to-json-serialize-sets
class SetEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, set):
return list(obj)
return json.JSONEncoder.default(self, obj)
# utility function for list combination
class ListCombineFn(beam.CombineFn):
def create_accumulator(self):
return []
def add_input(self, accumulator, input):
accumulator.append(input)
return accumulator
def merge_accumulators(self, accumulators):
merged = []
for accum in accumulators:
merged += accum
return merged
def extract_output(self, accumulator):
return accumulator
class PrepareData(beam.DoFn):
def process(self, record): # sample record - {"id": "1", "name": "abc", "address": "Mumbai", "phn": "1111111111"}
rec_columns = [ "id", "name", "address", "phn", "country", "age"] # all columns of the bigquery table
rec_keys = list(record.keys()) # ["id", "name", "address", "phn"] # columns needed for processing
values = {}
for x in range(len(rec_keys)):
key = rec_keys[x]
if key != "id" and key in rec_columns:
values[key] = record[key]
return [{"id": record['id'], "values": values}]
class MainClass:
def run_pipe(self):
try:
project = "my_project"
dataset = "my_dataset"
table = "my_table"
region = "us-central1"
job_name = "create-json-file"
temp_location = "gs://my_core_bucket/dataflow/temp_location/"
runner = "DataflowRunner"
# set pipeline options
argv = [
f'--project={project}',
f'--region={region}',
f'--job_name={job_name}',
f'--temp_location={temp_location}',
f'--runner={runner}'
]
# json file name
file_name = "gs://my_core_bucket/data/my_data"
# create pipeline
p = beam.Pipeline(argv=argv)
# query to read table data
query = f"SELECT id, name, address, phn FROM `{project}.{dataset}.{table}` LIMIT 4"
bq_data = p | 'Read Table' >> beam.io.Read(beam.io.ReadFromBigQuery(query=query, use_standard_sql=True))
# bq_data will be in the form
# {"id": "1", "name": "abc", "address": "Mumbai", "phn": "1111111111"}
# {"id": "2", "name": "def", "address": "Kolkata", "phn": "2222222222"}
# {"id": "3", "name": "ghi", "address": "Chennai", "phn": "3333333333"}
# {"id": "4", "name": "jkl", "address": "Delhi", "phn": "4444444444"}
# alter data in the form needed for downstream process
prepared_data = bq_data | beam.ParDo(PrepareData())
# combine all the results in one PCollection
# see https://beam.apache.org/documentation/transforms/python/aggregation/combineglobally/
prepared_data | 'Combine results' >> beam.CombineGlobally(ListCombineFn())
# write formatted pcollection as JSON file. We will use a
# custom encoder for se serialization
prepared_data | 'JSON format' >> beam.Map(json.dumps, cls=SetEncoder)
prepared_data | 'Write Output' >> beam.io.WriteToText(file_name, file_name_suffix=".json", shard_name_template='')
# execute pipeline
p.run().wait_until_finish()
except Exception as e:
logging.error(f"Exception in run_pipe - {str(e)}")
if __name__ == "__main__":
main_cls = MainClass()
main_cls.run_pipe()
-
问题内容: 我正在Ruby中创建哈希,并希望以正确的格式将其写入JSON文件。 这是我的代码: 这是结果文件的内容: 我正在使用Sinatra(不知道哪个版本)和Ruby v 1.8.7。 如何以正确的JSON格式将其写入文件? 问题答案: 需要JSON库,并使用。 您的temp.json文件现在看起来像:
-
我试图用以下格式转换一个JSON: 我已经计算了JSON,现在我需要使用evaluatejsonpath输出中的属性来获得以下格式: 它们是内置的处理器来完成此转换吗,还是需要在executionscript处理器中开发一个Python脚本?
-
本文向大家介绍.NET Framework 格式:自定义DateTime格式,包括了.NET Framework 格式:自定义DateTime格式的使用技巧和注意事项,需要的朋友参考一下 示例
-
ObjectMapper不会将对象格式化为自定义对象。 波乔不在我的控制之下,所以我不能改变它。我需要序列化WS的POJO对象。POJO有(我不知道为什么,因为它的日期来自数据库)。 我使用的是Spring boot 2.1.8。释放,所以。。。我将其放入我的依赖项中: 我还在应用程序中添加了这个。特性: 在配置文件中,我在配置文件中添加了这个bean,因为尽快配置ObjectMapper以接受更
-
问题内容: 我正在使用Jersey + Jackson为我的应用程序提供REST JSON服务层。我的问题是默认的日期序列化格式如下所示: 起初我以为这是UNIX时间戳…但是太长了。我的客户端JS库在反序列化此格式时遇到了问题(它支持一堆不同的日期格式,但我认为不支持)。我想更改格式,以便可以由我的库使用(例如ISO)。我该怎么做…我发现了一段代码可能会有所帮助,但是…由于我不控制Jackson序
-
我从web服务中获得了字符串ResultedValue的结果,该结果处于循环中,如下面的代码所示, 我想将ResultedValue的每个值存储在任何外部JSON文件格式中,当我使用 它给我的输出为[“target:q1/2013:17”]在字符串本身,我不知道我将如何存储在外部文件,因为我是一个新的JSON我不能做到这一点,我会请求请提供我的任何帮助链接
-
我需要以.csv格式输出我的hadoop结果。我要怎么做?我的代码:https://github.com/studhadoop/xml/blob/master/xmlparser11.java 我是否应该简单地在代码中包含csvoutputFormat。我正在使用mapreduce API MyJob.sh 解决方案
-
问题内容: 与MySQL使用Python在控制台中打印结果一样,最简单的打印MySQL查询结果的方法是什么?例如,我想得到类似的东西: 注意:我不知道每列的最大宽度是先验的,但是我希望能够不重复两次就可以做到这一点。是否应为每列添加查询的length()?MySQL如何做到这一点,以免严重影响内存或处理时间? 编辑 我认为这与问题无关,但这是我发送的查询: 这是我使用的python代码: 但是此代