
执行多个数据帧连接时PySpark OutOfMemoryErrors

有很多关于这个问题的帖子,但没有一个回答我的问题。
在尝试将许多不同的数据帧连接在一起时,我在PySpark中遇到了<code>OutOfMemoryError
我的本地机器有16GB内存,我已将Spark配置设置为:
class SparkRawConsumer:
def __init__(self, filename, reference_date, FILM_DATA):
self.sparkContext = SparkContext(master='local[*]', appName='my_app')
SparkContext.setSystemProperty('spark.executor.memory', '3g')
SparkContext.setSystemProperty('spark.driver.memory', '15g')
关于Spark中OOM错误的SO帖子显然很多很多,但基本上大多数都是说增加你的内存属性。
我实际上是对50-60个较小的数据帧执行连接,这些数据帧有两列< code>uid和< code > data _ in _ the _ form _ of _ lists (通常是一个Python字符串列表)。我正在联接的主数据帧大约有10列,但还包含一个< code>uid列(我正在联接)。
我只尝试加入1,500行数据。但是,当显然所有这些数据都可以放入内存时,我会经常遇到OutOfMemory错误。我通过在我的存储中查看我的SparkUI来确认这一点:

在代码中,我的连接如下所示:
# lots of computations to read in my dataframe and produce metric1, metric2, metric3, .... metric 50
metrics_df = metrics_df.join(
self.sqlContext.createDataFrame(metric1, schema=["uid", "metric1"]), on="uid")
metrics_df.count()
metrics_df.repartition("gid_value")
metrics_df = metrics_df.join(
self.sqlContext.createDataFrame(metric2, schema=["uid", "metric2"]),
on="gid_value")
metrics_df.repartition("gid_value")
metrics_df = metrics_df.join(
self.sqlContext.createDataFrame(metric3, schema=["uid", "metric3"]),
on="uid")
metrics_df.count()
metrics_df.repartition("gid_value")
其中,metric1、metric2和metic3是我在加入之前转换为数据帧的RDD(请记住,我正在加入的这些较小的metricdfs中实际上有50个)。
我调用metric.count()来强制评估,因为它似乎有助于防止内存错误(否则在尝试最终收集时,我会得到更多的驱动程序错误)。
这些错误是非确定性的。我没有看到它们始终出现在我的连接中的任何特定位置,有时似乎发生在我最后的metrics_df.collect()调用中,有时在较小的连接期间。
我真的怀疑任务序列化/反序列化存在一些问题。例如,当我查看典型阶段的事件时间线时,我发现大部分都被任务反序列化占用了:
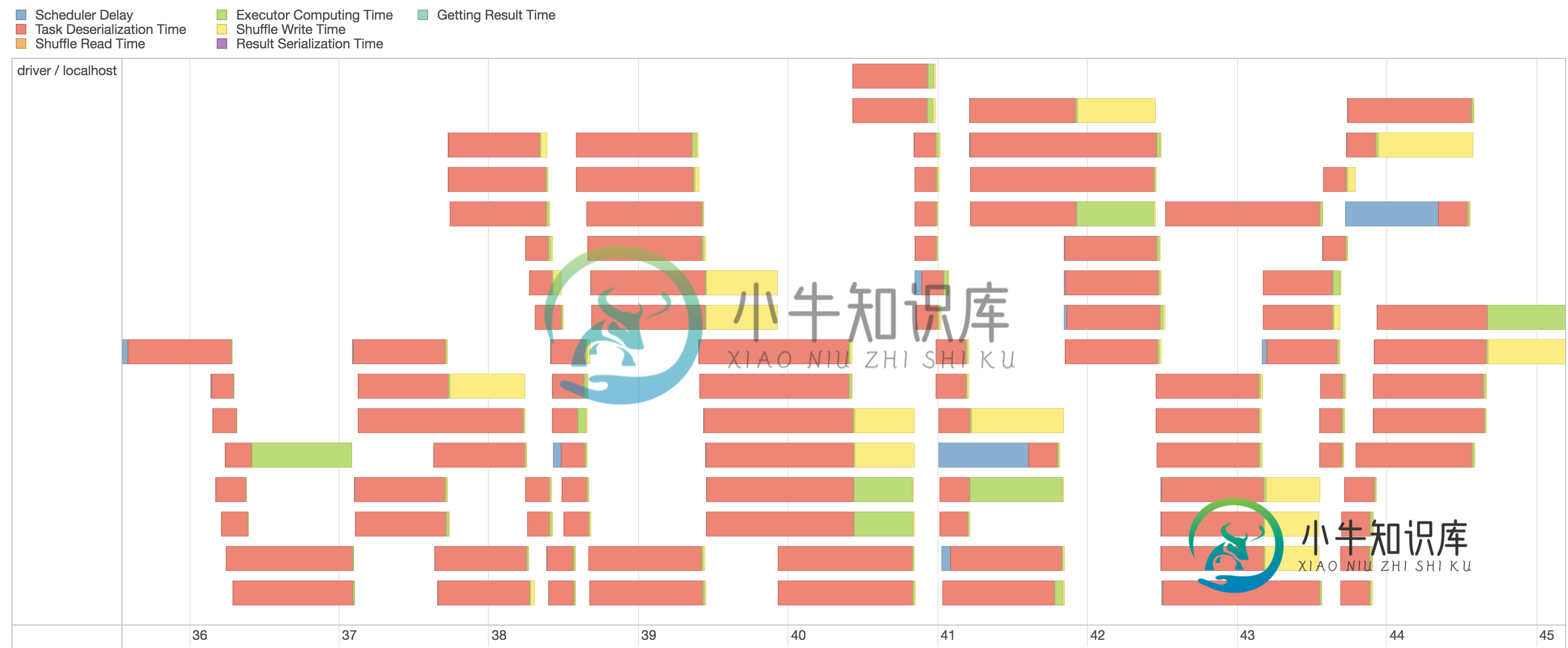
我还注意到有大量的垃圾回收机制:

垃圾回收是导致内存错误的问题吗?还是任务序列化?
我一直在作为一个更大的PyCharm项目的一部分运行Spark作业(因此Spark上下文被包装在一个类中)。我重构了代码,将其作为脚本运行,使用以下spark提交:
spark-submit spark_consumer.py \
--driver-memory=10G \
--executor-memory=5G \
--conf spark.executor.extraJavaOptions='-XX:+UseParallelGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps'
共有1个答案

我面临着类似的问题,它适用于:
Spark Submit:
spark-submit --driver-memory 3g\
--executor-memory 14g\
*.py
法典:
sc = SparkContext().getOrCreate()
-
我有一个csv文件列表,我使用 我目前正在尝试遍历csv列表,并使用方法将axis参数设置为1,以按列将所有数据帧添加到一起。 它是工作的希望,但我遇到的问题,因为所有的数据帧都有相同的冒号名称,当我连接他们我得到例如10列都与关键"日期" 不管怎样,我能给哥伦布起个独一无二的名字吗?比如伦敦约会,柏林约会?显然,这些名称基于数据帧的名称。
-
假设我有两个数据帧,具有不同级别的信息,如下所示: 我想加入df1和df2,并将“值”信息传递给df2:一天中的每一小时都将获得“日”值。 预期产出:
-
在Apache Spark 2.1.0中,我有两个数据帧aaa_01和aaa_ 02。 我对这两个数据帧执行内部联接,从两个数据帧中选择几个列以显示在输出中。 Join 工作正常,但输出数据帧具有与输入数据帧中存在的列名称相同的列名。我被困在这里。我需要使用新的列名称,而不是在输出数据帧中获取相同的列名称。 下面给出了示例代码供参考 我获取的输出数据帧的列名称为“col1,col2,col3”。我
-
基于“SC”代码,我需要将SRCTable与RefTable-1或RefTable-2连接起来 条件:如果SC为“D”,则SRCTable在KEY=KEY1上与RefTable-1连接以获得值。否则,如果SC为“U”,则SRCTable与键=键2上的RefTable-2连接 这是输入spark数据帧。 预期产出: 注意:输入表将有数百万条记录,因此需要一个优化的解决方案
-
我有3个CSV文件。每个数据框都有第一列作为人的(字符串)名称,而每个数据框中的所有其他列都是该人的属性。 如何将所有三个CSV文档“连接”在一起,创建一个单个CSV,每行都具有该人字符串名称的每个唯一值的所有属性? Pandas中的函数指定我需要一个多索引,但是我对分层索引方案与基于单个索引进行连接有什么关系感到困惑。
-
我需要将两个数据帧和一个接一个地连接起来,它们具有相同的行数(),而不考虑任何键。此函数类似于