
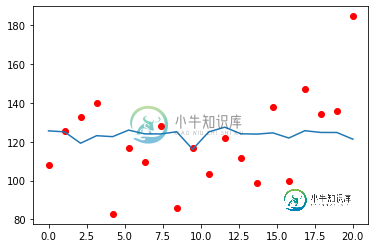
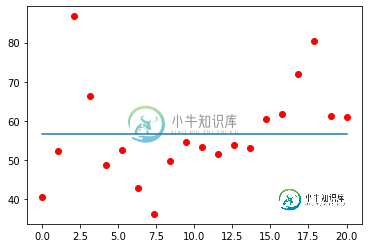
SVR/SVM 输出预测彼此非常相似,但远非真实值

主要思想是根据输入特征预测2个目标输出。
>
输入特征已经使用sklearn中的Standard caler()进行了缩放。X_train的大小是(190 x 6),Y_train=(190 x 2)。X_test是(20 x 6),Y_test=(20x2)
线性和rbf内核还利用Gridsearch chCV来查找最佳C(线性)、gamma和C('rbf')
[问题]我在线性和rbf内核上使用MultiOutputRegressor执行SVR,但是,预测的输出彼此非常相似(不完全是常量预测)并且与y的真实值相去甚远。
下面是散点图表示Y的真实值的图。第一张图片对应于第一个目标的结果,Y[:,0]。而第二张图片是第二个目标,Y[:,1]。
我必须扩展目标输出吗?是否有任何其他有助于提高测试准确性的模型?
我尝试过随机森林回归量并执行调整,测试准确性与我使用SVR获得的准确率大致相似。(以下结果来自 SVR)
最佳参数:{estimator__C':1}
MAE:[18.51151192 9.604601]#来自线性核
最佳参数 (rbf): {'estimator__C': 1, “estimator__gamma”: 1e-09} MAE (rbf): [17.80482033 9.39780134] #from rbf 内核
非常感谢!非常感谢任何帮助和意见^__^
----------------代码-----------------------------
import numpy as np
from numpy import load
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.multioutput import MultiOutputRegressor
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import RepeatedKFold
rkf = RepeatedKFold(n_splits=5, n_repeats=3)
#input features - HR, HRV, PTT, breathing_rate, LASI, AI
X = load('200_patient_input_scaled.npy')
#Output features - SBP, DBP
Y = load('200_patient_output_raw.npy')
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.095, random_state = 43)
epsilon = 0.1
#--------------------------- Linear SVR kernel Model ------------------------------------------------------
linear_svr = SVR(kernel='linear', epsilon = epsilon)
multi_output_linear_svr = MultiOutputRegressor(linear_svr)
#multi_output_linear_svr.fit(X_train, Y_train) #just to see the output
#GridSearch - find the best C
grid = {'estimator__C': [1,10,10,100,1000] }
grid_linear_svr = GridSearchCV(multi_output_linear_svr, grid, scoring='neg_mean_absolute_error', cv=rkf, refit=True)
grid_linear_svr.fit(X_train, Y_train)
#Prediction
Y_predict = grid_linear_svr.predict(X_test)
print("\nBest parameter:", grid_linear_svr.best_params_ )
print("MAE:", mean_absolute_error(Y_predict,Y_test, multioutput='raw_values'))
#-------------------------- RBF SVR kernel Model --------------------------------------------------------
rbf_svr = SVR(kernel='rbf', epsilon = epsilon)
multi_output_rbf_svr = MultiOutputRegressor(rbf_svr)
#Grid search - Find best combination of C and gamma
grid_rbf = {'estimator__C': [1,10,10,100,1000], 'estimator__gamma': [1e-9, 1e-8, 1e-7, 1e-6, 1e-5, 1e-4, 1e-3, 1e-2] }
grid_rbf_svr = GridSearchCV(multi_output_rbf_svr, grid_rbf, scoring='neg_mean_absolute_error', cv=rkf, refit=True)
grid_rbf_svr.fit(X_train, Y_train)
#Prediction
Y_predict_rbf = grid_rbf_svr.predict(X_test)
print("\nBest parameter (rbf):", grid_rbf_svr.best_params_ )
print("MAE (rbf):", mean_absolute_error(Y_predict_rbf,Y_test, multioutput='raw_values'))
#Plotting
plot_y_predict = Y_predict_rbf[:,1]
plt.scatter( np.linspace(0, 20, num = 20), Y_test[:,1], color = 'red')
plt.plot(np.linspace(0, 20, num = 20), plot_y_predict)
共有1个答案

一个常见的错误是,当人们使用Standard Scaler时,他们会沿着错误的数据轴使用它。您可以缩放所有数据,或者逐行而不是逐列缩放,请确保您做得对!我会手动执行以确保这一点,因为否则我认为它需要不同的Standard Scaler适合每个功能。
[回应/编辑]:我认为这只是否定了StandardScaler通过反转应用程序所做的事情。我并不完全确定StandardScaler的行为,我只是根据经验说了这些,并且在缩放多个特征数据时遇到了麻烦。如果我是你(例如最小最大缩放),我会喜欢这样的东西:
columnsX = X.shape[1]
for i in range(columnsX):
X[:, i] = (X[:, i] - X[:, i].min()) / (X[:, i].max() - X[:, i].min())
-
我使用scikit learn训练了一个SVR模型,该模型通过使用比特币以前日期的收盘价来预测比特币的未来价格。我已使用以下函数将日期从第一个可用日期转换为增量: 我的DataFrame头部看起来如下所示: 然后我将其划分为测试数据集和训练数据集,如下所示: 并在训练模型之前对数据集进行最小最大缩放,如下所示: 我的模型是用下面的函数训练的,我发现多项式核给出了最好的结果: 我得到以下准确性和交叉
-
我不知道语法是什么意思。感谢任何帮助。 谢谢你。
-
我已经在Python中通过,它们看起来都非常相似。为什么?如何随机化它们?
-
我有一个对象列表: 每一个都包含一个Object2列表。我试图遍历objList,以便从每个Object1各自的Object2列表中删除Object2的特定实例: 这会引发错误:“集合已修改;枚举操作可能无法执行。” 我不明白的是,我正在从Object2List中删除一个对象,它没有被枚举。为什么会抛出此错误?
-
我正试图确定相似度得分的截止范围。如果名称差异太大,我想排除它们以进行手动检查。 虽然低于。4的名称似乎完全不同,但。4的范围似乎相当相似。 但是后来我遇到了一些奇怪的异常,在这个范围内的一些名称完全不同,而一些名称只相差一两个字母(见下面的示例)。
-
问题内容: 我要两个紧挨着。右边大约200px;并且左侧必须填满屏幕的其余宽度?我怎样才能做到这一点? 问题答案: 您可以使用 flexbox 布置物品: 这基本上只是刮擦flexbox的表面。Flexbox可以做很多令人惊奇的事情。 对于较旧的浏览器支持,可以使用CSS float 和 width 属性来解决它。