
如何在实践中创建幽灵小工具?

我正在开发(NASM GCC针对ELF64)一个PoC,它使用一个spectre小工具来测量访问一组缓存行(刷新重载)的时间。
如何制作可靠的幽灵小工具?
我相信我理解刷新重装技术背后的理论,然而在实践中,我鄙视一些噪音,我无法产生一个工作的概念验证。
由于我使用的是时间戳计数器,并且负载非常规则,因此我使用此脚本来禁用预取器,涡轮增压并修复/稳定CPU频率:
#!/bin/bash
sudo modprobe msr
#Disable turbo
sudo wrmsr -a 0x1a0 0x4000850089
#Disable prefetchers
sudo wrmsr -a 0x1a4 0xf
#Set performance governor
sudo cpupower frequency-set -g performance
#Minimum freq
sudo cpupower frequency-set -d 2.2GHz
#Maximum freq
sudo cpupower frequency-set -u 2.2GHz
我有一个连续的缓冲区,在4KiB上对齐,大到足以跨越256个缓存行,由整数个GAP行分隔。
SECTION .bss ALIGN=4096
buffer: resb 256 * (1 + GAP) * 64
我用这个函数来刷新256行。
flush_all:
lea rdi, [buffer] ;Start pointer
mov esi, 256 ;How many lines to flush
.flush_loop:
lfence ;Prevent the previous clflush to be reordered after the load
mov eax, [rdi] ;Touch the page
lfence ;Prevent the current clflush to be reordered before the load
clflush [rdi] ;Flush a line
add rdi, (1 + GAP)*64 ;Move to the next line
dec esi
jnz .flush_loop ;Repeat
lfence ;clflush are ordered with respect of fences ..
;.. and lfence is ordered (locally) with respect of all instructions
ret
该函数循环所有行,触摸中间的每一页(每页不止一次)并刷新每一行。
然后我使用这个函数来分析访问。
profile:
lea rdi, [buffer] ;Pointer to the buffer
mov esi, 256 ;How many lines to test
lea r8, [timings_data] ;Pointer to timings results
mfence ;I'm pretty sure this is useless, but I included it to rule out ..
;.. silly, hard to debug, scenarios
.profile:
mfence
rdtscp
lfence ;Read the TSC in-order (ignoring stores global visibility)
mov ebp, eax ;Read the low DWORD only (this is a short delay)
;PERFORM THE LOADING
mov eax, DWORD [rdi]
rdtscp
lfence ;Again, read the TSC in-order
sub eax, ebp ;Compute the delta
mov DWORD [r8], eax ;Save it
;Advance the loop
add r8, 4 ;Move the results pointer
add rdi, (1 + GAP)*64 ;Move to the next line
dec esi ;Advance the loop
jnz .profile
ret
附录中提供了 MCVE,并提供了一个可用于克隆的存储库。
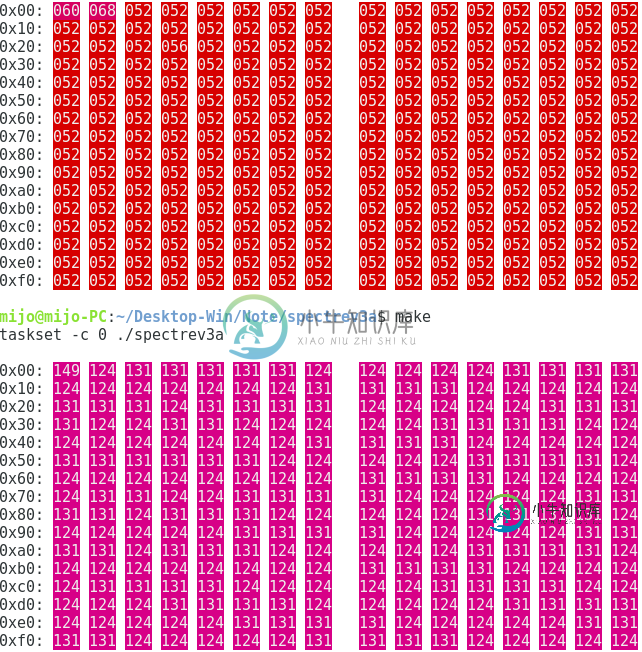
当在< code>GAP设置为0的情况下汇编时,使用< code>taskset -c 0链接并执行时,获取每一行所需的周期如下所示。

只有64行是从内存加载的。
输出在不同的运行中是稳定的。如果我将< code>GAP设置为1,则只从内存中取出32行,当然是64 * (1 0) * 64 = 32 * (1 1) * 64 = 4096,所以这可能与分页有关?
如果在对前64行中的一行进行分析之前(但在刷新之后)执行存储,则输出更改为

任何存储其他行都给出第一种类型的输出。
我怀疑数学是错误的,但我需要再多看几眼才能找到答案。
编辑
Hadi Brais指出了易失性寄存器的误用,在修复了输出现在不一致之后。
我看到普遍在时序较低的地方运行(约50个周期),有时在时序较高的地方运行(约130个周期)。
我不知道130个周期的数字是从哪里来的(对内存来说太低,对缓存来说太高?)。
代码固定在MCVE(和存储库)中。
如果在分析之前执行了对任何第一行的存储,则不会在输出中反映任何更改。
附录-MCVE
BITS 64
DEFAULT REL
GLOBAL main
EXTERN printf
EXTERN exit
;Space between lines in the buffer
%define GAP 0
SECTION .bss ALIGN=4096
buffer: resb 256 * (1 + GAP) * 64
SECTION .data
timings_data: TIMES 256 dd 0
strNewLine db `\n0x%02x: `, 0
strHalfLine db " ", 0
strTiming db `\e[48;5;16`,
.importance db "0",
db `m\e[38;5;15m%03u\e[0m `, 0
strEnd db `\n\n`, 0
SECTION .text
;'._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .'
; ' ' ' ' ' ' ' ' ' ' '
; _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \
;/ \/ \/ \/ \/ \/ \/ \/ \/ \/ \/ \
;
;
;FLUSH ALL THE LINES OF A BUFFER FROM THE CACHES
;
;
flush_all:
lea rdi, [buffer] ;Start pointer
mov esi, 256 ;How many lines to flush
.flush_loop:
lfence ;Prevent the previous clflush to be reordered after the load
mov eax, [rdi] ;Touch the page
lfence ;Prevent the current clflush to be reordered before the load
clflush [rdi] ;Flush a line
add rdi, (1 + GAP)*64 ;Move to the next line
dec esi
jnz .flush_loop ;Repeat
lfence ;clflush are ordered with respect of fences ..
;.. and lfence is ordered (locally) with respect of all instructions
ret
;'._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .'
; ' ' ' ' ' ' ' ' ' ' '
; _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \
;/ \/ \/ \/ \/ \/ \/ \/ \/ \/ \/ \
;
;
;PROFILE THE ACCESS TO EVERY LINE OF THE BUFFER
;
;
profile:
lea rdi, [buffer] ;Pointer to the buffer
mov esi, 256 ;How many lines to test
lea r8, [timings_data] ;Pointer to timings results
mfence ;I'm pretty sure this is useless, but I included it to rule out ..
;.. silly, hard to debug, scenarios
.profile:
mfence
rdtscp
lfence ;Read the TSC in-order (ignoring stores global visibility)
mov ebp, eax ;Read the low DWORD only (this is a short delay)
;PERFORM THE LOADING
mov eax, DWORD [rdi]
rdtscp
lfence ;Again, read the TSC in-order
sub eax, ebp ;Compute the delta
mov DWORD [r8], eax ;Save it
;Advance the loop
add r8, 4 ;Move the results pointer
add rdi, (1 + GAP)*64 ;Move to the next line
dec esi ;Advance the loop
jnz .profile
ret
;'._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .'
; ' ' ' ' ' ' ' ' ' ' '
; _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \
;/ \/ \/ \/ \/ \/ \/ \/ \/ \/ \/ \
;
;
;SHOW THE RESULTS
;
;
show_results:
lea rbx, [timings_data] ;Pointer to the timings
xor r12, r12 ;Counter (up to 256)
.print_line:
;Format the output
xor eax, eax
mov esi, r12d
lea rdi, [strNewLine] ;Setup for a call to printf
test r12d, 0fh
jz .print ;Test if counter is a multiple of 16
lea rdi, [strHalfLine] ;Setup for a call to printf
test r12d, 07h ;Test if counter is a multiple of 8
jz .print
.print_timing:
;Print
mov esi, DWORD [rbx] ;Timing value
;Compute the color
mov r10d, 60 ;Used to compute the color
mov eax, esi
xor edx, edx
div r10d ;eax = Timing value / 78
;Update the color
add al, '0'
mov edx, '5'
cmp eax, edx
cmova eax, edx
mov BYTE [strTiming.importance], al
xor eax, eax
lea rdi, [strTiming]
call printf WRT ..plt ;Print a 3-digits number
;Advance the loop
inc r12d ;Increment the counter
add rbx, 4 ;Move to the next timing
cmp r12d, 256
jb .print_line ;Advance the loop
xor eax, eax
lea rdi, [strEnd]
call printf WRT ..plt ;Print a new line
ret
.print:
call printf WRT ..plt ;Print a string
jmp .print_timing
;'._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .'
; ' ' ' ' ' ' ' ' ' ' '
; _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \
;/ \/ \/ \/ \/ \/ \/ \/ \/ \/ \/ \
;
;
;E N T R Y P O I N T
;
;
;'._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .''._ .'
; ' ' ' ' ' ' ' ' ' ' '
; _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \ _' \
;/ \/ \/ \/ \/ \/ \/ \/ \/ \/ \/ \
main:
;Flush all the lines of the buffer
call flush_all
;Test the html" target="_blank">access times
call profile
;Show the results
call show_results
;Exit
xor edi, edi
call exit WRT ..plt
共有1个答案

缓冲区是从bss部分分配的,因此当程序加载时,操作系统会将所有缓冲区缓存行映射到同一CoW物理页面。刷新所有行后,只有对虚拟地址空间中前 64 行的访问在所有缓存级别1 中都未命中,因为所有2 个后续访问都指向同一个 4K 页面。这就是为什么前 64 次访问的延迟落在主内存延迟的范围内,而当 GAP 为零时,所有后续访问的延迟等于 L1 命中延迟3。
当<code>GAP<code>为1时,同一物理页的每隔一行都会被访问,因此主内存访问(L3未命中)的数量为32(64的一半)。也就是说,前32个等待时间将在主存储器等待时间的范围内,并且所有随后的等待时间将是L1命中。类似地,当<code>GAP<code>为63时,所有访问都指向同一行。因此,只有第一次访问将错过所有缓存。
解决方案是将<code>flush_all更改为<code>mov dword[rdi],0,以确保缓冲区分配在唯一的物理页中。(可以删除<code>flush_all
您可以参考为什么只有在存在存储初始化循环时才统计用户模式L1存储未命中事件?另一个例子是,CoW页面可能具有欺骗性。
在这个答案的前一版本中,我建议删除对<code>flush_all<code>的调用,并使用<code>GAP<code>值63。通过这些更改,所有访问延迟似乎都非常高,我错误地得出结论,所有访问都缺少所有缓存级别。如上所述,如果<code>GAP<code>值为63,则所有访问都会变成同一缓存行,该缓存行实际上位于一级缓存中。然而,所有延迟都很高的原因是因为每次访问都是针对不同的虚拟页面,并且TLB没有针对每个虚拟页面(到同一物理页面)的任何映射,因为通过删除对<code>flush_all</code>的调用,以前没有触及任何虚拟页面。因此,测量的延迟表示TLB未命中延迟,即使正在访问的行在一级缓存中。
我在这个答案的前一个版本中也错误地声称,有一个L3预取逻辑不能通过MSR 0x1A4禁用。如果通过在MSR 0x1A4中设置其标志来关闭特定的预取器,那么它确实会完全关闭。此外,除了英特尔记录的预取器之外,没有其他数据预取器。
脚注:
(1)如果您不禁用DCU IP预取器,它实际上会在刷新后将所有线路预取回L1,因此所有访问仍将在L1中命中。
(2)在极少数情况下,在同一内核上执行中断处理程序或调度其他线程可能会导致某些行从L1以及可能的缓存层次结构的其他级别中被逐出。
(3) 请记住,您需要减去<code>rdtscp
(4)Intel手册似乎没有指定clflush是否带有读取顺序,但在我看来是这样的。
-
问题内容: 我不知道它的名字是否正确,但是我想看看是否有一种特定的方法来实现文本字段,以便当它没有焦点且为空时,出现一个淡淡的灰色字符串文本显示在该字段中。单击该字段时,文本应该消失,就像StackOverflow之类的搜索栏的工作方式一样。我知道我可以更改使用方法和焦点侦听器来完成此操作,但是我只是想知道是否有人知道某些Java实现可以帮助我解决此问题。 问题答案: 对于它的价值,我发现实际实现
-
我无法使用 apache poi eclipse 在我创建的 java excel 中创建工作表
-
可以使用一张图像来创建精灵,PNG, JPEG, TIFF, WebP, 这几个格式都可以。当然也有一些其它的方式可以创建精灵,如使用 图集 创建,通过 精灵缓存 创建,我们会一个一个的讨论。本节介绍通过图像创建精灵。 使用图像创建 Sprite 能用一个特定的图像去创建: auto mySprite = Sprite::create("mysprite.png"); 上面直接使用了 myspr
-
问题内容: 我想为工具提示创建一个自定义CSS类,该类将包裹长度超过25-30的字符串。通常这样长的文本不适合tootltip文本区域。 而且是否有使用[工具提示ui.bootstrap.tooltip)进行此操作?就像使用自定义CSS类来获取所需的输出。 这是简单的CSS工具提示 这是相同的代码片段: 问题答案: CSS解决方案 对于眼前的问题有一个非常简单的解决方案。我基本上添加的是以下CSS
-
本文向大家介绍ThreadPoolExecutor 创建方法最佳实践?相关面试题,主要包含被问及ThreadPoolExecutor 创建方法最佳实践?时的应答技巧和注意事项,需要的朋友参考一下 在《阿里巴巴 Java 开发手册》“并发处理”这一章节,明确指出线程资源必须通过线程池提供,不允许在应用中自行显示创建线程。 为什么呢? 使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源开
-
问题内容: 在C ++中,我可以创建如下数组: 在python中,我只知道我可以声明一个列表,而不要附加一些项目或类似。 我可以按给定的大小(如c ++)初始化列表,并且不进行任何赋值吗? 问题答案: (tl;博士:您问题的确切答案是或,但您可能不在乎,可以摆脱使用的困扰。) 您可以将列表初始化为所有相同的元素。使用非数字值在语义上有意义(如果使用它会在以后产生错误,这是一件好事)或类似0的值(不