
Pyspark错误:Java网关进程在发送其端口号之前退出

我正在使用Pyspark运行一些命令在Jupyter笔记本,但它是抛出错误。我尝试了这个链接中提供的解决方案(pyspark:exception:Java gateway process在发送驱动程序端口号之前退出),并且尝试了这里提供的解决方案(比如将路径更改为c:Java、卸载Java SDK 10和重新安装Java8,但它仍然给我带来了同样的错误。
我试着卸载和重新安装pyspark,我试着从anaconda提示符运行,但我还是得到同样的错误。我使用的是Python3.7,而pyspark版本是2.4.0。
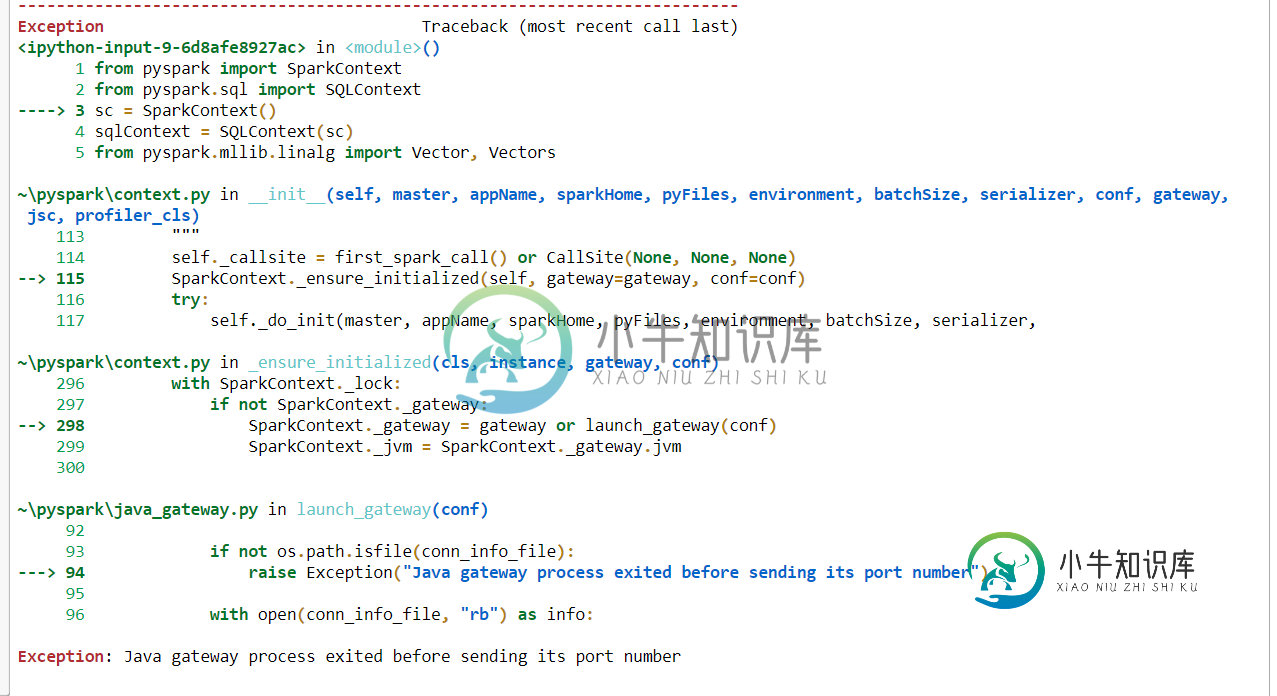
如果我使用这段代码,我会得到这个错误。“Exception:Java网关进程在发送其端口号之前退出”。
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext()
sqlContext = SQLContext(sc)
from pyspark.mllib.linalg import Vector, Vectors
from nltk.stem.wordnet import WordNetLemmatizer
from pyspark.ml.feature import RegexTokenizer, StopWordsRemover, Word2Vec
from pyspark import SparkContext
from pyspark.sql import SQLContext
from pyspark.mllib.linalg import Vector, Vectors
from nltk.stem.wordnet import WordNetLemmatizer
from pyspark.ml.feature import RegexTokenizer, StopWordsRemover, Word2Vec
这里是完整的错误代码图片。
共有1个答案

在bash终端中输入以下内容,它将被修复:
export PYSPARK_SUBMIT_ARGS="--master local[2] pyspark-shell"
这只是将pyspark-shell导出到shell环境变量pyspark_submit_args。
-
我在Spark 3.1.2和Hadoop 2.7中面临两个错误: 第一个是在python中导入'pyspark'并创建一个会话。 错误:'Java网关进程在发送端口号前已退出‘ 我从GitHub上的存储库中为以下Hadoop版本下载了它们:[2.7.1,2.7.7] 试过了,都不起作用。 我的环境变量--就我所检查的而言--是正确的: Windows 10 Python:3.7.10 水蟒:4.1
-
我在python环境中使用了pip安装pyspark,安装了java,但是当我尝试初始化spark会话时,我得到了一个java错误,java网关进程在发送端口号之前退出 运行时错误发布在上面,我在其他帖子中没有看到这种类型的错误
-
我运行Windows10,并通过Anaconda3安装了Python3。我在用Jupyter笔记本。我从这里安装了Spark(Spark-2.3.0-bin-Hadoop2.7.tgz)。我已经解压缩了这些文件,并将它们粘贴到我的目录d:\spark中。我已经修改了环境变量: 用户变量: 变量:SPARK_HOME 值:D:\spark\bin 我已经通过conda安装/更新了以下模块: 熊猫 皮
-
尝试使用时我遇到了一个问题。我在我的用户路径中安装并添加了。但根据文档,它不需要任何其他依赖项。 我的问题是,我必须安装其他东西吗?像Spark本身或类似的东西? 我在中使用。
-
我正试图用Anaconda在我的Windows10中安装Spark,但当我试图在JupyterNotebook中运行pyspark时,我遇到了一个错误。我正在遵循本教程中的步骤。然后,我已经下载了Java8并安装了Spark 3.0.0和Hadoop 2.7。 我已经为SPARK_HOME、JAVA_HOME设置了路径,并在“path”环境中包含了“/bin”路径。 在Anaconda pyspa
-
代码在下面 获取错误异常:Java网关进程在发送其端口号之前退出