
JMH-奇怪的基准测试结果

我使用JMH对DOM解析器进行基准测试。我得到了非常奇怪的结果,因为第一次迭代实际上比后面的迭代运行得更快
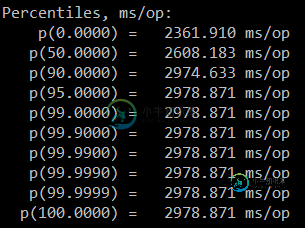
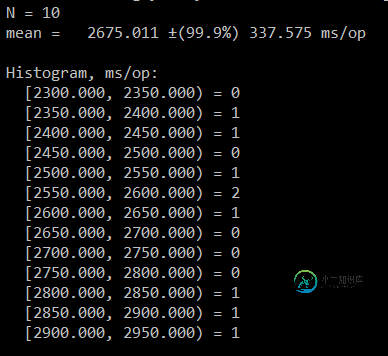
有人能解释为什么会这样吗?此外,百分位数和所有数字意味着什么?为什么在第三次迭代后它开始变得稳定?一次迭代是否意味着整个基准测试方法的一次迭代?下面是我正在运行的方法
@Benchmark
@BenchmarkMode(Mode.SingleShotTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@Warmup(iterations = 13, time = 1, timeUnit = TimeUnit.MILLISECONDS)
public void testMethod_no_attr() {
try {
File fXmlFile = new File("500000-6.xml");
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder dBuilder = dbFactory.newDocumentBuilder();
Document doc = dBuilder.parse(fXmlFile);
} catch (Exception e) {
e.printStackTrace();
}
}
共有2个答案

您的屏幕截图缺少直方图输出。你看到的只是直方图的一个百分比。
检查此示例。我们有100次迭代,方法BoolArrayVsBitSetBenchmark#原语的结果是:
Result "de.jawb.jmh.benchmark.example.bool.BoolArrayVsBitSetBenchmark.primitive":
N = 100
mean = 0,493 ±(99.9%) 0,003 s/op
Histogram, s/op:
[0,490, 0,495) = 93
[0,495, 0,500) = 3
[0,500, 0,505) = 1
[0,505, 0,510) = 1
[0,510, 0,515) = 0
[0,515, 0,520) = 0
[0,520, 0,525) = 1
[0,525, 0,530) = 0
[0,530, 0,535) = 0
[0,535, 0,540) = 0
[0,540, 0,545) = 0
[0,545, 0,550) = 0
[0,550, 0,555) = 0
[0,555, 0,560) = 1
Percentiles, s/op:
p(0,0000) = 0,490 s/op
p(50,0000) = 0,491 s/op
p(90,0000) = 0,494 s/op
p(95,0000) = 0,496 s/op
p(99,0000) = 0,558 s/op
p(99,9000) = 0,559 s/op
p(99,9900) = 0,559 s/op
p(99,9990) = 0,559 s/op
p(99,9999) = 0,559 s/op
p(100,0000) = 0,559 s/op
第一条直方图线[0490,0495)=93表示93个呼叫属于组max 0490s和min 0494s。注意括号“)”
总而言之,这意味着没有呼叫比0,491 s / op更快,因为
p(00000)=0490秒/操作
最大执行时间为0,559 s/op,因为
p(100,0000)= 0.559s/op

这些百分点是可怕的误导。不要使用它们。
如果你有N = 10,难怪所有的底部值都是相同的。因为你的样本太少了,无法谈论任何像99.999%分位数这样的东西。我在这里实际考虑的唯一值是中位数(50%分位数),最终是IQR(四分位数之间的比率)。
如果你乐观,你会认为你最慢的样本是95%。如果您不太乐观,请将 N=10 的最慢样本视为 90% 分位数。如果你更认真地对待这些估计,你可以把间距视为大约1/sqrt(N-1)的指示,即假设高达33%的运行将比N=10的最慢样本慢。您需要更多的样本来缩小这些估计值的范围!任何超过95%的东西都只是猜测。99% - 你不能回答那里发生的事情。你只是没有足够的数据。
如前所述,这些价值观完全是胡说八道。根据数据,您无法估计P(999999)=某物。这个数字相当于百万分之一的跑步成绩比这个差。但你只做了10次,不要用这个小N来预测如果你有一百万会发生什么。JMH不应该为小N打印这些极端分位数。
-
我通过JMH进行了一些基准测试 假设我在一个Java文件中列出了三个基准测试 每种方法都对服务于相同目的的不同算法进行基准测试。当我一起运行所有基准测试时,与逐个运行基准测试相比,结果会有所不同。 例如,在Java文件上仅使用onw基准执行JMH运行。 如果只运行此方法,此方法的结果会更好,但是如果使用更多基准,结果会更差。 假设基于结果的基准测试 我还尝试改变基准的顺序(按字典顺序执行),结果是
-
受另一个关于堆栈溢出的问题的启发,我编写了一个微型基准来检查,什么更有效: 有条件地检查零除数或 捕获和处理 下面是我的代码: 我对JMH完全陌生,不确定代码是否正确。 我的基准是正确的吗?你看到任何错误吗? 旁白:请不要建议询问https://codereview.stackexchange.com.对于Codereview,代码必须已按预期工作。我不确定这个基准是否能按预期工作。
-
我正在使用向服务器发送REST请求的自定义Java库为HTTP服务器编写性能测试。在开始时,我正在执行数据准备阶段,以便获得一个要向服务器发送请求的对象列表。 现在,问题是,我可以使用注释测试可以注入基准函数的参数列表: 问题是,我希望通过Java参数列表实现同样的效果,并避免对它们进行迭代。你能告诉我怎么做吗?
-
我是JMH的新手。在运行代码并使用不同的注释之后,我真的不明白它是如何工作的。我使用迭代=1、预热=1、fork=1来查看我的代码将执行一次,但事实并非如此。JMH运行我的代码超过100000次,我不知道为什么。那么,如何控制代码调用的时间?下面是我的代码:(我为测试修复了JMHSample\u 01)
-
我目前有一个JMH基准测试来衡量所有实现相同接口的各种数据结构的性能。基准测试工作正常,但我想为每个基准测试打印一些额外的信息,这些信息描述了我的数据结构在试验前后的状态。 目前,我正在做下面的代码 问题是与JMH的输出混淆。有没有办法避免这种情况,并在JMH完成其试验报告后运行我的打印声明?另一种方法是将其写入一个文件,然后进行合并,但最好得到一个不需要手动合并的报告。
-
我的最终目标是使用标准Java集合作为基准,为几个Java基本集合库创建一套全面的基准。在过去,我曾使用循环方法编写这类微基准测试。我将我正在进行基准测试的函数放在一个循环中,并迭代100万次,这样jit就有机会预热。我取循环的总时间,然后除以迭代次数,得到一个对我正在进行基准测试的函数的单个调用所需时间的估计值。在最近阅读了JMH项目,特别是这个例子:JMHSample_11_循环之后,我看到了