
是否有一种方法可以提交集群上的Google Dataproc PySpark作业以供使用。ipynb文件?

我正在Google Dataproc集群上的Jupyter Notebook上工作。当您使用笔记本时,它会在每个单元格的执行上给出输出。
我必须在集群上提交PySpark作业。作业将. py文件作为输入。下面附上截图
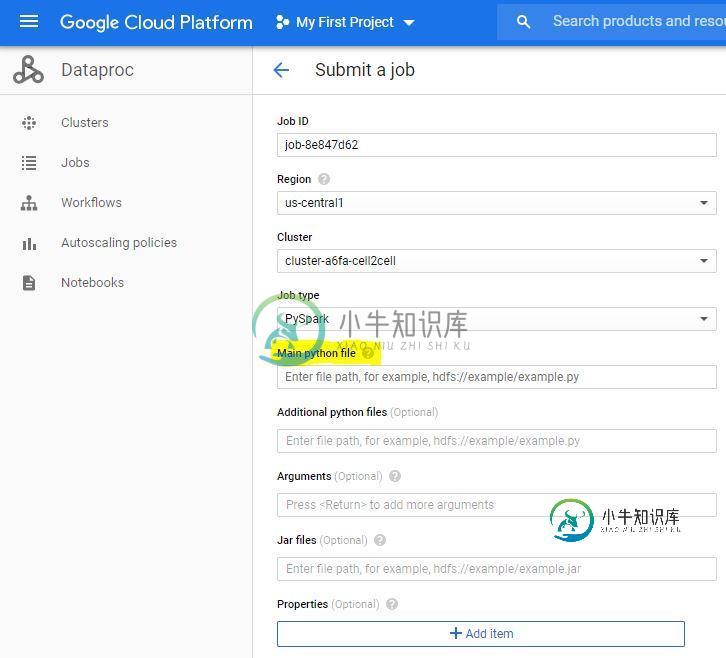
当我进入一条小路。ipynb文件它给出了以下错误。
线程“main”组织中出现异常。阿帕奇。火花SparkException:无法从JAR文件加载主类:/tmp/job-e4811479-cell2cell1/Customer\u chorn\u(Cell2Cell)\u Parallel。组织的ipynb。阿帕奇。火花部署SparkSubmitArguments。组织中的错误(SparkSubmitArguments.scala:657)。阿帕奇。火花部署SparkSubmitArguments。org上的loadEnvironmentArguments(SparkSubmitArguments.scala:221)。阿帕奇。火花部署SparkSubmitArguments。(SparkSubmitArguments.scala:116)在org。阿帕奇。火花部署SparkSubmit$$anon$2$$anon$3。(SparkSubmit.scala:907)在org。阿帕奇。火花部署SparkSubmit$$anon$2。org上的parseArguments(SparkSubmit.scala:907)。阿帕奇。火花部署SparkSubmit。doSubmit(SparkSubmit.scala:81)位于org。阿帕奇。火花部署SparkSubmit$$anon$2。doSubmit(SparkSubmit.scala:920)位于org。阿帕奇。火花部署SparkSubmit$。main(SparkSubmit.scala:929)位于org。阿帕奇。火花部署SparkSubmit。main(SparkSubmit.scala)
我假设我们只能将. py文件作为集群上的作业提交。此外,由于代码的性质,将. ipynb转换为. py对我来说是不可行的。我想要每个单元的输出。
有什么方法可以提交集群上的. ipynb文件吗?或者我需要制作一个. py文件来实现这一点?
任何帮助都很感激。谢谢。
共有1个答案

您不能提交笔记本文件,即ipynb。
您应该将其转换为py文件,然后在spark dataproc集群上提交。
火花提交的输出可以向GCS写入多个输出,但只返回一个输出。
因此,您可以在GCS上为每个输出创建一个对象,并将结果包含在bucket中。
-
正如标题所预期的,我在向docker上运行的spark集群提交spark作业时遇到了一些问题。 我在scala中写了一个非常简单的火花作业,订阅一个kafka服务器,安排一些数据,并将这些数据存储在一个elastichsearch数据库中。 如果我在我的开发环境(Windows/IntelliJ)中从Ide运行spark作业,那么一切都会完美工作。 然后(我一点也不喜欢java),我按照以下说明添
-
问题内容: 使用标准的Rails form_for,我可以通过select和collection_select助手传递ajax请求,例如: 我似乎无法弄清楚如何使用simple_form 问题答案: 弄清楚了。您只需要添加以下内容:
-
我已经用一个JDBCstore实现了Quartz调度器。 我有一个作业QzJob1,它是CRON每两分钟调度一次的。但作业的总执行时间为3分钟。 现在我的要求是。是否有一种方法可以使它在所有节点上都是唯一的,这样,在该作业完成之前,尽管触发器在完成之前已经准备好了,但它不会再次被触发。 我试图找出它,但什么也找不到。因此,请指导/指示/指点我,使我将它向前推进。 感谢你的帮助。
-
我目前正在尝试开发一个不和谐的机器人使用Java在Replit,我想保持我的机器人的令牌在.env文件,所以只有我可以访问它。但是,我不知道如何访问Main.java文件中的变量。有办法吗?
-
问题内容: 问题是:编写一个交换两个变量的方法。这两个变量应该是原语。它不需要是通用的,例如两个变量。有办法吗? 问题答案: 如果不使用数组或对象,不可以,无法在方法中进行操作。
-
在Spock规范中,expect:或then:block中的任何行都被计算并断言为,除非它具有返回类型为的签名。 方法在类中定义如下: 我故意在那里断言,这样它就不会失败。即使失败并出现错误: 如何以及为什么方法调用结果被计算为?