
如何在拼接现有pdf和从头创建的pdf时保留页面标签?

我有一个代码是创建一个“封面”,然后将其与现有的pdf文件合并。合并后,pdf标签丢失。如何保留现有pdf的pdf标签,然后将页面标签添加到从头开始创建的pdf页面(例如“封面”)?我认为这本书的例子是关于检索和替换页面标签的。我不知道如何将一个现有的pdf和一个从头创建的pdf连接起来。我用的是itext 5.3.0。提前感谢。
根据mkl的评论进行编辑
public ByteArrayOutputStream getConcatenatePDF()
{
if (bitstream == null)
return null;
if (item == null)
{
item = getItem();
if (item == null)
return null;
}
ByteArrayOutputStream byteout = null;
InputStream coverStream = null;
try
{
// Get Cover Page
coverStream = getCoverStream();
if (coverStream == null)
return null;
byteout = new ByteArrayOutputStream();
int pageOffset = 0;
ArrayList<HashMap<String, Object>> master = new ArrayList<HashMap<String, Object>>();
Document document = null;
PdfCopy writer = null;
PdfReader reader = null;
byte[] password = (ownerpass != null && !"".equals(ownerpass)) ? ownerpass.getBytes() : null;
// Get infomation of the original pdf
reader = new PdfReader(bitstream.retrieve(), password);
boolean isPortfolio = reader.getCatalog().contains(PdfName.COLLECTION);
char version = reader.getPdfVersion();
int permissions = reader.getPermissions();
// Get metadata
HashMap<String, String> info = reader.getInfo();
String title = (info.get("Title") == null || "".equals(info.get("Title")))
? getFieldValue("dc.title") : info.get("Title");
String author = (info.get("Author") == null || "".equals(info.get("Author")))
? getFieldValue("dc.contributor.author") : info.get("Author");
String subject = (info.get("Subject") == null || "".equals(info.get("Subject")))
? "" : info.get("Subject");
String keywords = (info.get("Keywords") == null || "".equals(info.get("Keywords")))
? getFieldValue("dc.subject") : info.get("Keywords");
reader.close();
// Merge cover page and the original pdf
InputStream[] is = new InputStream[2];
is[0] = coverStream;
is[1] = bitstream.retrieve();
for (int i = 0; i < is.length; i++)
{
// we create a reader for a certain document
reader = new PdfReader(is[i], password);
reader.consolidateNamedDestinations();
if (i == 0)
{
// step 1: creation of a document-object
document = new Document(reader.getPageSizeWithRotation(1));
// step 2: we create a writer that listens to the document
writer = new PdfCopy(document, byteout);
// Set metadata from the original pdf
// the position of these lines is important
document.addTitle(title);
document.addAuthor(author);
document.addSubject(subject);
document.addKeywords(keywords);
if (pdfa)
{
// Set thenecessary information for PDF/A-1B
// the position of these lines is important
writer.setPdfVersion(PdfWriter.VERSION_1_4);
writer.setPDFXConformance(PdfWriter.PDFA1B);
writer.createXmpMetadata();
}
else if (version == '5')
writer.setPdfVersion(PdfWriter.VERSION_1_5);
else if (version == '6')
writer.setPdfVersion(PdfWriter.VERSION_1_6);
else if (version == '7')
writer.setPdfVersion(PdfWriter.VERSION_1_7);
else
; // no operation
// Set security parameters
if (!pdfa)
{
if (password != null)
{
if (security && permissions != 0)
{
writer.setEncryption(null, password, permissions, PdfWriter.STANDARD_ENCRYPTION_128);
}
else
{
writer.setEncryption(null, password, PdfWriter.ALLOW_PRINTING | PdfWriter.ALLOW_COPY | PdfWriter.ALLOW_SCREENREADERS, PdfWriter.STANDARD_ENCRYPTION_128);
}
}
}
// step 3: we open the document
document.open();
// if this pdf is portfolio, does not add cover page
if (isPortfolio)
{
reader.close();
byte[] coverByte = getCoverByte();
if (coverByte == null || coverByte.length == 0)
return null;
PdfCollection collection = new PdfCollection(PdfCollection.TILE);
writer.setCollection(collection);
PdfFileSpecification fs = PdfFileSpecification.fileEmbedded(writer, null, "cover.pdf", coverByte);
fs.addDescription("cover.pdf", false);
writer.addFileAttachment(fs);
continue;
}
}
int n = reader.getNumberOfPages();
// step 4: we add content
PdfImportedPage page;
PdfCopy.PageStamp stamp;
for (int j = 0; j < n; )
{
++j;
page = writer.getImportedPage(reader, j);
if (i == 1) {
stamp = writer.createPageStamp(page);
Rectangle mediabox = reader.getPageSize(j);
Rectangle crop = new Rectangle(mediabox);
writer.setCropBoxSize(crop);
// add overlay text
//<-- Code for adding overlay text -->
stamp.alterContents();
}
writer.addPage(page);
}
PRAcroForm form = reader.getAcroForm();
if (form != null && !pdfa)
{
writer.copyAcroForm(reader);
}
// we retrieve the total number of pages
List<HashMap<String, Object>> bookmarks = SimpleBookmark.getBookmark(reader);
//if (bookmarks != null && !pdfa)
if (bookmarks != null)
{
if (pageOffset != 0)
{
SimpleBookmark.shiftPageNumbers(bookmarks, pageOffset, null);
}
master.addAll(bookmarks);
}
pageOffset += n;
}
if (!master.isEmpty())
{
writer.setOutlines(master);
}
if (isPortfolio)
{
reader = new PdfReader(bitstream.retrieve(), password);
PdfDictionary catalog = reader.getCatalog();
PdfDictionary documentnames = catalog.getAsDict(PdfName.NAMES);
PdfDictionary embeddedfiles = documentnames.getAsDict(PdfName.EMBEDDEDFILES);
PdfArray filespecs = embeddedfiles.getAsArray(PdfName.NAMES);
PdfDictionary filespec;
PdfDictionary refs;
PRStream stream;
PdfFileSpecification fs;
String path;
// copy embedded files
for (int i = 0; i < filespecs.size(); )
{
filespecs.getAsString(i++); // remove description
filespec = filespecs.getAsDict(i++);
refs = filespec.getAsDict(PdfName.EF);
for (PdfName key : refs.getKeys())
{
stream = (PRStream) PdfReader.getPdfObject(refs.getAsIndirectObject(key));
path = filespec.getAsString(key).toString();
fs = PdfFileSpecification.fileEmbedded(writer, null, path, PdfReader.getStreamBytes(stream));
fs.addDescription(path, false);
writer.addFileAttachment(fs);
}
}
}
if (pdfa)
{
InputStream iccFile = this.getClass().getClassLoader().getResourceAsStream(PROFILE);
ICC_Profile icc = ICC_Profile.getInstance(iccFile);
writer.setOutputIntents("Custom", "", "http://www.color.org", "sRGB IEC61966-2.1", icc);
writer.setViewerPreferences(PdfWriter.PageModeUseOutlines);
}
// step 5: we close the document
document.close();
}
catch (Exception e)
{
log.info(LogManager.getHeader(context, "cover_page: getConcatenatePDF", "bitstream_id="+bitstream.getID()+", error="+e.getMessage()));
// e.printStackTrace();
return null;
}
return byteout;
}
更新
根据mkl的回答,我修改了上面的代码,如下所示:
public ByteArrayOutputStream getConcatenatePDF()
{
if (bitstream == null)
return null;
if (item == null)
{
item = getItem();
if (item == null)
return null;
}
ByteArrayOutputStream byteout = null;
try
{
// Get Cover Page
InputStream coverStream = getCoverStream();
if (coverStream == null)
return null;
byteout = new ByteArrayOutputStream();
InputStream documentStream = bitstream.retrieve();
PdfReader coverPageReader = new PdfReader(coverStream);
PdfReader reader = new PdfReader(documentStream);
PdfStamper stamper = new PdfStamper(reader, byteout);
PdfImportedPage page = stamper.getImportedPage(coverPageReader, 1);
stamper.insertPage(1, coverPageReader.getPageSize(1));
PdfContentByte content = stamper.getUnderContent(1);
int n = reader.getNumberOfPages();
for (int j = 2; j <= n; j++) {
//code for overlay text
ColumnText.showTextAligned(stamper.getOverContent(j), Element.ALIGN_CENTER, overlayText,
crop.getLeft(10), crop.getHeight() / 2 + crop.getBottom(), 90);
}
content.addTemplate(page, 0, 0);
stamper.close();
}
catch (Exception e)
{
log.info(LogManager.getHeader(context, "cover_page: getConcatenatePDF", "bitstream_id="+bitstream.getID()+", error="+e.getMessage()));
e.printStackTrace();
return null;
}
return byteout;
}
然后我将页面标签设置为封面。我省略了与我的问题无关的代码。
/**
*
* @return InputStream the resulting output stream
*/
private InputStream getCoverStream()
{
ByteArrayOutputStream byteout = getCover();
return new ByteArrayInputStream(byteout.toByteArray());
}
/**
*
* @return InputStream the resulting output stream
*/
private byte[] getCoverByte()
{
ByteArrayOutputStream byteout = getCover();
return byteout.toByteArray();
}
/**
*
* @return InputStream the resulting output stream
*/
private ByteArrayOutputStream getCover()
{
ByteArrayOutputStream byteout;
Document doc = null;
try
{
byteout = new ByteArrayOutputStream();
doc = new Document(PageSize.LETTER, 24, 24, 20, 40);
PdfWriter pdfwriter = PdfWriter.getInstance(doc, byteout);
PdfPageLabels labels = new PdfPageLabels();
labels.addPageLabel(1, PdfPageLabels.EMPTY, "Cover page", 1);
pdfwriter.setPageLabels(labels);
pdfwriter.setPageEvent(new HeaderFooter());
doc.open();
//code omitted (contents of cover page)
doc.close();
return byteout;
}
catch (Exception e)
{
log.info(LogManager.getHeader(context, "cover_page", "bitstream_id="+bitstream.getID()+", error="+e.getMessage()));
return null;
}
}
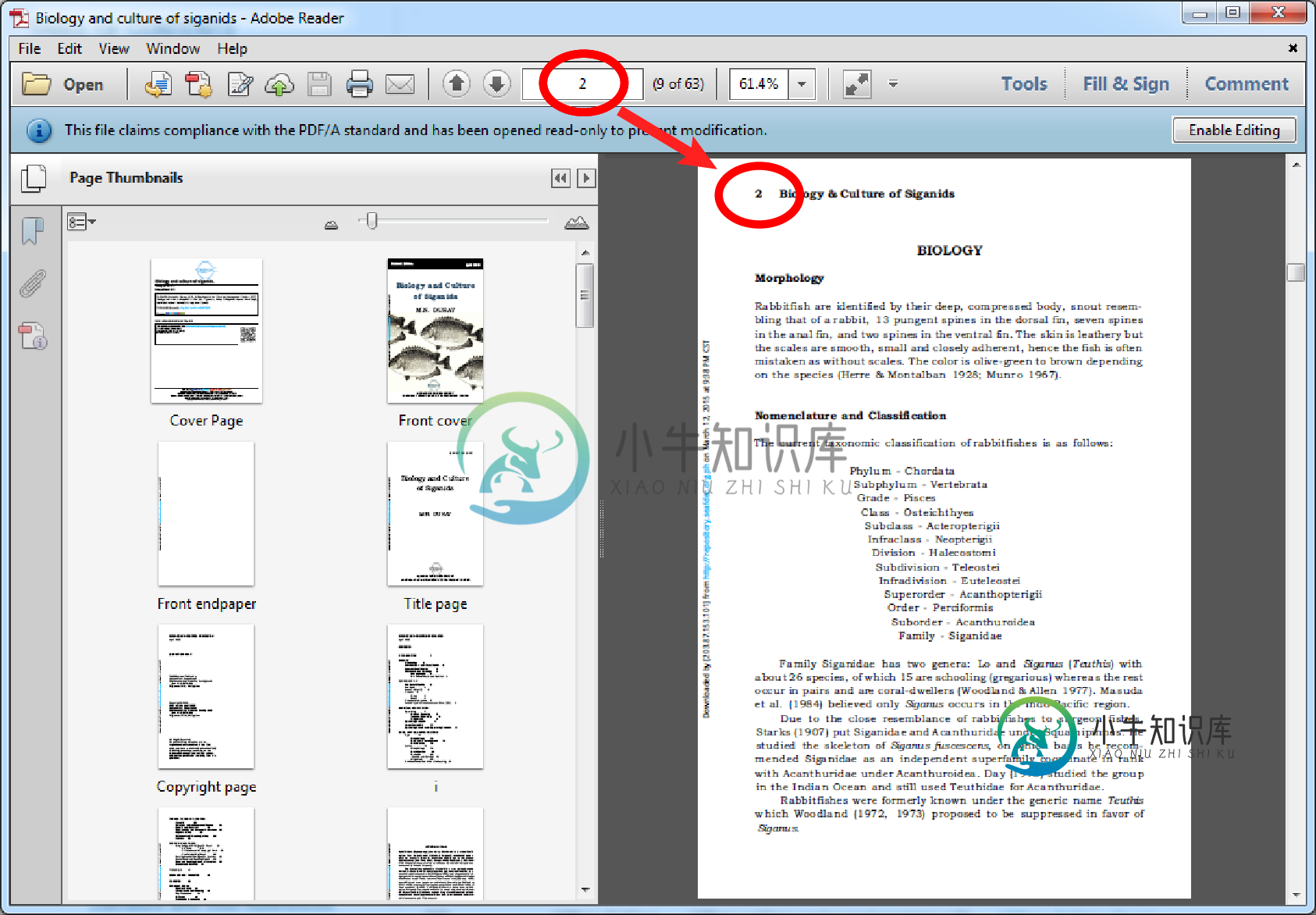
修改后的代码保留了现有pdf的页面标签(见截图1)(documentStream),但生成的合并pdf(截图2和3)由于插入了封面而偏离了1页。正如mkl所建议的那样,我应该在封面上使用页面标签,但似乎导入页面的pdf标签丢失了。我现在关心的是如何将页面标签设置为mkl建议的最终文档状态?我想我应该使用PdfWriter,但我不知道把它放在我修改的代码中的位置。我假设在 stamper.close() 部分之后,这就是我的文档的最终状态,我是否正确?再次提前致谢。
@mkl的最终更新荣誉下面的屏幕截图是我应用mkl答案的最新更新后的结果。页面标签现在正确分配给页面。此外,使用PdfStamper而不是PdfCopy(如我的原始代码中使用的那样)并没有破坏现有pdf的PDF/A合规性。
共有1个答案

通常使用PdfCopy合并PDF是正确的选择,它从复制的页面创建一个新文档,尽可能多地复制页面级信息,而不是首选任何单个文档。
不过,您的情况有些特殊:您有一个文档,您喜欢它的结构和内容,并希望通过添加一个页面(标题页)对它进行小的更改。一直以来,包括文档级信息(例如,元数据,嵌入文件,...)仍将出现在结果中。
在这种用例中,使用PdfStamper将更改“戳”到现有PDF上更合适。
您可能希望从以下内容开始:
try ( InputStream documentStream = getClass().getResourceAsStream("template.pdf");
InputStream titleStream = getClass().getResourceAsStream("title.pdf");
OutputStream outputStream = new FileOutputStream(new File(RESULT_FOLDER, "test-with-title-page.pdf")) )
{
PdfReader titleReader = new PdfReader(titleStream);
PdfReader reader = new PdfReader(documentStream);
PdfStamper stamper = new PdfStamper(reader, outputStream);
PdfImportedPage page = stamper.getImportedPage(titleReader, 1);
stamper.insertPage(1, titleReader.getPageSize(1));
PdfContentByte content = stamper.getUnderContent(1);
content.addTemplate(page, 0, 0);
stamper.close();
}
PS:关于评论中的问题:
在我上面的代码中,我应该有一个覆盖文本(在 stamp.alterContents() 部分之前),但我省略了该部分代码以进行测试。你能给我一个如何实现它的想法吗?
你的意思是像覆盖水印一样的东西吗?PdfStamper允许您访问每个页面的“覆盖内容”,您可以在该页面上绘制任何内容:
PdfContentByte overContent = stamper.getOverContent(pageNumber);
我的另一个问题是关于页面偏移量,因为我插入了封面,页面编号偏移了1页。我如何解决这个问题?
遗憾的是,iText 的“下载放大”不会自动更新作的 PDF 的页面标签定义。实际上,这并不奇怪,因为不清楚插入的页面将如何标记。@Bruno 至少,iText可以从插入页码之后开始更改页面标签部分。
但是,使用iText的低级API可以修复原始标签位置并为插入的页面添加标签。这可以类似于操作中的iText页面标签示例实现,更确切地说是其操作页面标签部分;只需在压模之前添加此内容即可:
PdfDictionary root = reader.getCatalog();
PdfDictionary labels = root.getAsDict(PdfName.PAGELABELS);
if (labels != null)
{
PdfArray newNums = new PdfArray();
newNums.add(new PdfNumber(0));
PdfDictionary coverDict = new PdfDictionary();
coverDict.put(PdfName.P, new PdfString("Cover Page"));
newNums.add(coverDict);
PdfArray nums = labels.getAsArray(PdfName.NUMS);
if (nums != null)
{
for (int i = 0; i < nums.size() - 1; )
{
int n = nums.getAsNumber(i++).intValue();
newNums.add(new PdfNumber(n+1));
newNums.add(nums.getPdfObject(i++));
}
}
labels.put(PdfName.NUMS, newNums);
stamper.markUsed(labels);
}
对于具有这些标签的文档:
它会生成一个具有以下标签的文档:
我刚刚发现插入的页面“封面”丢失了其链接注释。我想知道是否有解决方法,因为根据该书,使用PdfStamper时插入页面的交互功能会丢失。
事实上,在 iText PDF 生成类中,只有 Pdf*复制* 保留了注释等交互式功能。不幸的是,一个人必须决定一个人是否想要
- 创建一个真正的新PDF(
PDF作家),除了内容可嵌入之外,没有其他PDF中的信息; - 操作单个现有 PDF(“Pdf收藏夹”),保留该 PDF 中的所有信息,但除了可嵌入的内容外,没有其他 PDF 中的信息;
- 将任意数量的现有 PDF (
PdfCopy) 与所有要保留的 PDF 中的大多数页面级信息合并,但不包含任何文档级信息。
在您的案例中,我认为新的封面只有静态内容,没有动态特性,因此假设PdfStamper是最好的。如果你只需要处理链接,你可以考虑手动复制链接,例如使用这个助手方法
/**
* <p>
* A primitive attempt at copying links from page <code>sourcePage</code>
* of <code>PdfReader reader</code> to page <code>targetPage</code> of
* <code>PdfStamper stamper</code>.
* </p>
* <p>
* This method is meant only for the use case at hand, i.e. copying a link
* to an external URI without expecting any advanced features.
* </p>
*/
void copyLinks(PdfStamper stamper, int targetPage, PdfReader reader, int sourcePage)
{
PdfDictionary sourcePageDict = reader.getPageNRelease(sourcePage);
PdfArray annotations = sourcePageDict.getAsArray(PdfName.ANNOTS);
if (annotations != null && annotations.size() > 0)
{
for (PdfObject annotationObject : annotations)
{
annotationObject = PdfReader.getPdfObject(annotationObject);
if (!annotationObject.isDictionary())
continue;
PdfDictionary annotation = (PdfDictionary) annotationObject;
if (!PdfName.LINK.equals(annotation.getAsName(PdfName.SUBTYPE)))
continue;
PdfArray rectArray = annotation.getAsArray(PdfName.RECT);
if (rectArray == null || rectArray.size() < 4)
continue;
Rectangle rectangle = PdfReader.getNormalizedRectangle(rectArray);
PdfName hightLight = annotation.getAsName(PdfName.H);
if (hightLight == null)
hightLight = PdfAnnotation.HIGHLIGHT_INVERT;
PdfDictionary actionDict = annotation.getAsDict(PdfName.A);
if (actionDict == null || !PdfName.URI.equals(actionDict.getAsName(PdfName.S)))
continue;
PdfString urlPdfString = actionDict.getAsString(PdfName.URI);
if (urlPdfString == null)
continue;
PdfAction action = new PdfAction(urlPdfString.toString());
PdfAnnotation link = PdfAnnotation.createLink(stamper.getWriter(), rectangle, hightLight, action);
stamper.addAnnotation(link, targetPage);
}
}
}
您可以在插入原始页面后立即调用它:
PdfImportedPage page = stamper.getImportedPage(titleReader, 1);
stamper.insertPage(1, titleReader.getPageSize(1));
PdfContentByte content = stamper.getUnderContent(1);
content.addTemplate(page, 0, 0);
copyLinks(stamper, 1, titleReader, 1);
当心,这种方法非常简单。它仅考虑具有 URI 操作的链接,并使用与原始页面相同的位置、目标和突出显示设置在目标页面上创建链接。如果原始要素使用更精细的特征(例如,如果它带有自己的外观流,甚至仅使用边框样式属性),并且您希望保留这些特征,则必须改进方法以将这些特征的条目复制到新注释中。
-
对于演示节目,我被要求提供一个powerpoint文件。然而,我更喜欢LaTeX和Beamer来创建我的幻灯片。所以我有了创建一个自动脚本的想法,从我的PDF文件中提取图像并创建一个PPT文件。 我是Automator新手,但通过谷歌搜索,我很容易就找到了: 询问查找器项目。 将 PDF 页面呈现为图像。( 分辨率 : 300) 创建PPT图片幻灯片 不幸的是,有一个问题 :图片不能完全填满幻灯片
-
我的用例是我正在动态生成pdf。我也有一个单页的pdf。我想在现有的pdf页面之后/之前连接新生成的PDF。 我已经能够从超文本标记语言生成PDF(这可能导致2-3页)Pdf从超文本标记语言与CSS 我试图查找示例,其中之一是按页面方式连接现有的PDF使用现有的PDF-Concatenate
-
我想从现有的Word2010文档创建一个文档,并使用Docx4j3.1.0将其转换为PDF。我在样品的基础上 这个东西应该有用吗?如果是:我怎样才能发现我遗漏了什么?
-
} 有什么建议吗?提前谢了。
-
问题内容: 在应用程序中,用户可以上传尺寸为8.46“ x 10.97”的任何pdf文件。根据我们的应用程序尺寸应为8.5“ x 11”。问题是,如何重新调整现有pdf页面的大小以设置8.5“ x11”?我必须通过代码修复,而不是手动,赞扬线路或外部软件。请让我知道提供此功能的Java支持jar(免费版)或通过简单的Java修复也可以。 问题答案: 使用iText,您可以执行以下操作: 我介绍了公
-
我想生产一个PDF的网页在景观。虽然可以使用以下方法将页面大小设置为横向: 这并没有达到我想要的,因为我添加的任何内容仍然是面向左->右的,而我希望它是底部->顶部的。 即。这就是我得到的: 我已经能够实现所需的输出打开PDF后,它已经创建并使用iText旋转它,但我想要一个解决方案,让我旋转后立即与iText添加内容。