
如何从隐藏的跨类HTML中刮取链接?

我正在学习网络抓取,因为我从真实的网站抓取真实世界的数据。然而,直到现在我才遇到这种问题。人们通常可以通过右键单击网站的一部分,然后单击检查选项来搜索想要的超文本标记语言源代码。我马上跳到这个例子来解释这个问题。
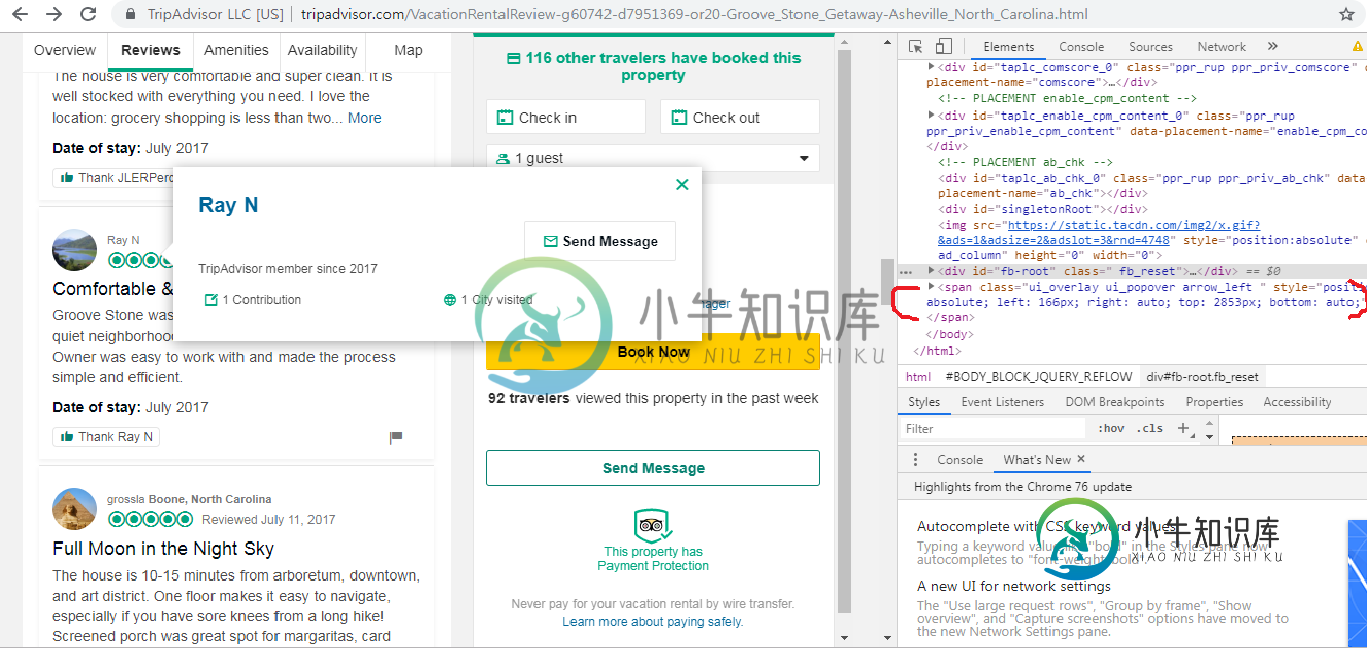
从上图中,红色标记的span类本来不存在,但是当我把光标放在用户的名字上(甚至没有点击)时,弹出一个该用户的小框,也显示了span类。我最终想要刮取的是嵌入在该span类中的用户配置文件的链接地址。我不确定,但是如果我可以解析那个span类,我想我可以尝试抓取链接地址,但是我一直无法解析那个隐藏的span类。
我没有期望那么多,但是我的代码当然给了我一个空列表,因为当我的光标不在用户名上时,span类没有出现。但是我展示我的代码来展示我所做的。
from bs4 import BeautifulSoup
from selenium import webdriver
#Incognito Mode
option=webdriver.ChromeOptions()
option.add_argument("--incognito")
#Open Chrome
driver=webdriver.Chrome(executable_path="C:/Users/chromedriver.exe",options=option)
driver.get("https://www.tripadvisor.com/VacationRentalReview-g60742-d7951369-or20-Groove_Stone_Getaway-Asheville_North_Carolina.html")
time.sleep(3)
#parse html
html =driver.page_source
soup=BeautifulSoup(html,"html.parser")
hidden=soup.find_all("span", class_="ui_overlay ui_popover arrow_left")
print (hidden)
有没有简单直观的方法可以使用selenium解析隐藏的span类?如果我可以解析它,我可以使用“find”函数解析用户的链接地址,然后循环遍历所有用户以获取所有链接地址。非常感谢。
======================================================================
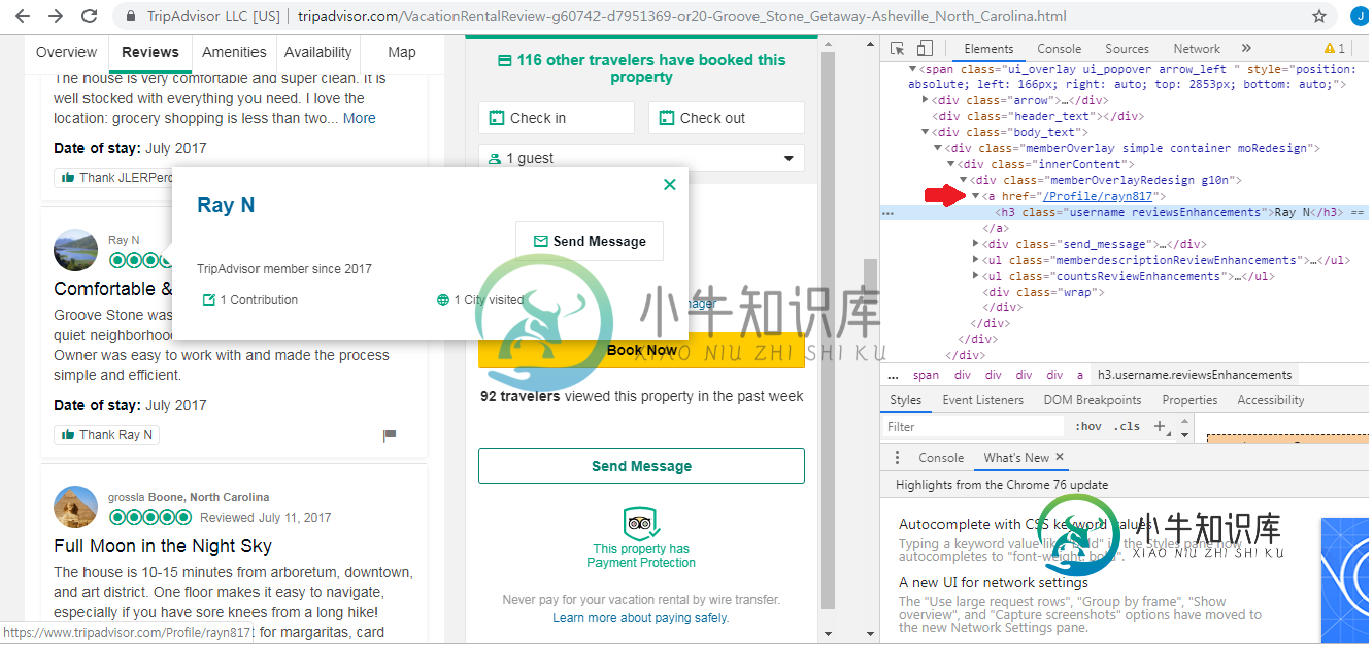
要添加有关我要检索内容的更详细说明,我想从下图中获取红色箭头指向的链接。谢谢你指出我需要更多的解释。
===========================================到目前为止已更新代码=====================
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait as wait
from selenium.webdriver.support import expected_conditions as EC
#Incognito Mode
option=webdriver.ChromeOptions()
option.add_argument("--incognito")
#Open Chrome
driver=webdriver.Chrome(executable_path="C:/Users/chromedriver.exe",options=option)
driver.get("https://www.tripadvisor.com/VacationRentalReview-g60742-d7951369-or20-Groove_Stone_Getaway-Asheville_North_Carolina.html")
time.sleep(3)
profile=driver.find_element_by_xpath("//div[@class='mainContent']")
profile_pic=profile.find_element_by_xpath("//div[@class='ui_avatar large']")
ActionChains(driver).move_to_element(profile_pic).perform()
ActionChains(driver).move_to_element(profile_pic).click().perform()
#So far I could successfully hover over the first user. A few issues occur after this line.
#The error message says "type object 'By' has no attribute 'xpath'". I thought this would work since I searched on the internet how to enable this function.
waiting=wait(driver, 5).until(EC.element_to_be_clickable((By.xpath,('//span//a[contains(@href,"/Profile/")]'))))
#This gives me also a error message saying that "unable to locate the element".
#Some of the ways to code in Python and Java were different so I searched how to get the value of the xpath which contains "/Profile/" but gives me an error.
profile_box=driver.find_element_by_xpath('//span//a[contains(@href,"/Profile/")]').get_attribute("href")
print (profile_box)
还有,在这种情况下,有没有办法迭代xpath?
共有2个答案

下面的代码将提取href值。试着让我知道进展如何。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome('/usr/local/bin/chromedriver') # Optional argument, if not specified will search path.
driver.implicitly_wait(15)
driver.get("https://www.tripadvisor.com/VacationRentalReview-g60742-d7951369-or20-Groove_Stone_Getaway-Asheville_North_Carolina.html");
#finds all the comments or profile pics
profile_pic= driver.find_elements(By.XPATH,"//div[@class='prw_rup prw_reviews_member_info_hsx']//div[@class='ui_avatar large']")
for i in profile_pic:
#clicks all the profile pic one by one
ActionChains(driver).move_to_element(i).perform()
ActionChains(driver).move_to_element(i).click().perform()
#print the href or link value
profile_box=driver.find_element_by_xpath('//span//a[contains(@href,"/Profile/")]').get_attribute("href")
print (profile_box)
driver.quit()
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.interactions.Actions;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
public class Selenium {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver", "./lib/chromedriver");
WebDriver driver = new ChromeDriver();
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
driver.get("https://www.tripadvisor.com/VacationRentalReview-g60742-d7951369-or20-Groove_Stone_Getaway-Asheville_North_Carolina.html");
//finds all the comments or profiles
List<WebElement> profile= driver.findElements(By.xpath("//div[@class='prw_rup prw_reviews_member_info_hsx']//div[@class='ui_avatar large']"));
for(int i=0;i<profile.size();i++)
{
//Hover on user profile photo
Actions builder = new Actions(driver);
builder.moveToElement(profile.get(i)).perform();
builder.moveToElement(profile.get(i)).click().perform();
//Wait for user details pop-up
WebDriverWait wait = new WebDriverWait(driver, 10);
wait.until(ExpectedConditions.visibilityOfElementLocated(By.xpath("//span//a[contains(@href,'/Profile/')]")));
//Extract the href value
String hrefvalue=driver.findElement(By.xpath("//span//a[contains(@href,'/Profile/')]")).getAttribute("href");
//Print the extracted value
System.out.println(hrefvalue);
}
//close the browser
driver.quit();
}
}
输出
https://www.tripadvisor.com/Profile/861kellyd
https://www.tripadvisor.com/Profile/JLERPercy
https://www.tripadvisor.com/Profile/rayn817
https://www.tripadvisor.com/Profile/grossla
https://www.tripadvisor.com/Profile/kapmem

我认为您可以使用请求库而不是selenium。
当您将鼠标悬停在用户名上时,您将获得如下所示的请求URL。
import requests
from bs4 import BeautifulSoup
html = requests.get('https://www.tripadvisor.com/VacationRentalReview-g60742-d7951369-or20-Groove_Stone_Getaway-Asheville_North_Carolina.html')
print(html.status_code)
soup = BeautifulSoup(html.content, 'html.parser')
# Find all UID of username
# Split the string "UID_D37FB22A0982ED20FA4D7345A60B8826-SRC_511863293" into UID, SRC
# And recombine to Request URL
name = soup.find_all('div', class_="memberOverlayLink")
for i in name:
print(i.get('id'))
# Use url to get profile link
response = requests.get('https://www.tripadvisor.com/MemberOverlay?Mode=owa&uid=805E0639C29797AEDE019E6F7DA9FF4E&c=&src=507403702&fus=false&partner=false&LsoId=&metaReferer=')
soup = BeautifulSoup(response.content, 'html.parser')
result = soup.find('a')
print(result.get('href'))
这是输出:
200
UID_D37FB22A0982ED20FA4D7345A60B8826-SRC_511863293
UID_D37FB22A0982ED20FA4D7345A60B8826-SRC_511863293
UID_D37FB22A0982ED20FA4D7345A60B8826-SRC_511863293
UID_805E0639C29797AEDE019E6F7DA9FF4E-SRC_507403702
UID_805E0639C29797AEDE019E6F7DA9FF4E-SRC_507403702
UID_805E0639C29797AEDE019E6F7DA9FF4E-SRC_507403702
UID_6A86C50AB327BA06D3B8B6F674200EDD-SRC_506453752
UID_6A86C50AB327BA06D3B8B6F674200EDD-SRC_506453752
UID_6A86C50AB327BA06D3B8B6F674200EDD-SRC_506453752
UID_97307AA9DD045AE5484EEEECCF0CA767-SRC_500684401
UID_97307AA9DD045AE5484EEEECCF0CA767-SRC_500684401
UID_97307AA9DD045AE5484EEEECCF0CA767-SRC_500684401
UID_E629D379A14B8F90E01214A5FA52C73B-SRC_496284746
UID_E629D379A14B8F90E01214A5FA52C73B-SRC_496284746
UID_E629D379A14B8F90E01214A5FA52C73B-SRC_496284746
/Profile/JLERPercy
如果你想用硒来获得弹出框,
可以使用ActionChains执行hover()函数。
但是我认为它比使用请求效率低。
from selenium.webdriver.common.action_chains import ActionChains
ActionChains(driver).move_to_element(element).perform()
-
问题内容: 我已经在ASPX中创建了一个表。我想根据要求隐藏其中一列,但是没有像HTML表构建那样的属性。我该如何解决我的问题? 问题答案: 为此,您需要使用样式表。
-
我对python和刮擦是新手,请帮助我如何从这个表中刮擦数据。对于登录,请转到公共登录,然后输入收件人和收件人日期。 数据模型:数据模型具有以下特定顺序和大小写的列:“record_date”、“doc_number”、“doc_type”、“role”、“name”、“apn”、“transfer_amount”、“county”和“state”。“角色”列可以是“授权人”,也可以是“授权人”,
-
有多个包含美国专利No.9,000,000的转让数据的div元素出现在行下面 有办法用JSOUP提取这个隐藏的html吗?
-
问题内容: 我正在开发一个需要从链接获取网页源,然后从该页面解析html的应用程序。 您能给我一些例子,还是从哪里着手开始编写这样的应用程序? 问题答案: 您可以使用HttpClient执行HTTP GET并检索HTML响应,如下所示:
-
这是我的代码: 我在找“eFotrait-table”: 具体来说,这一条:
-
废弃链接应该是一个简单的壮举,通常只需获取a标签的< code>src值。 我最近偶然发现这个网站(https://sunteccity.com.sg/promotions ),每个项目的a标签的href值无法找到,但重定向仍然有效。我正在试图找出一种方法来抓取项目及其相应的链接。我的典型python selenium代码如下所示 但是,我似乎无法检索任何、属性,我想知道这是否可能。我注意到我也无