
网页正在用Chromedriver作为机器人检测Selenium Webdriver

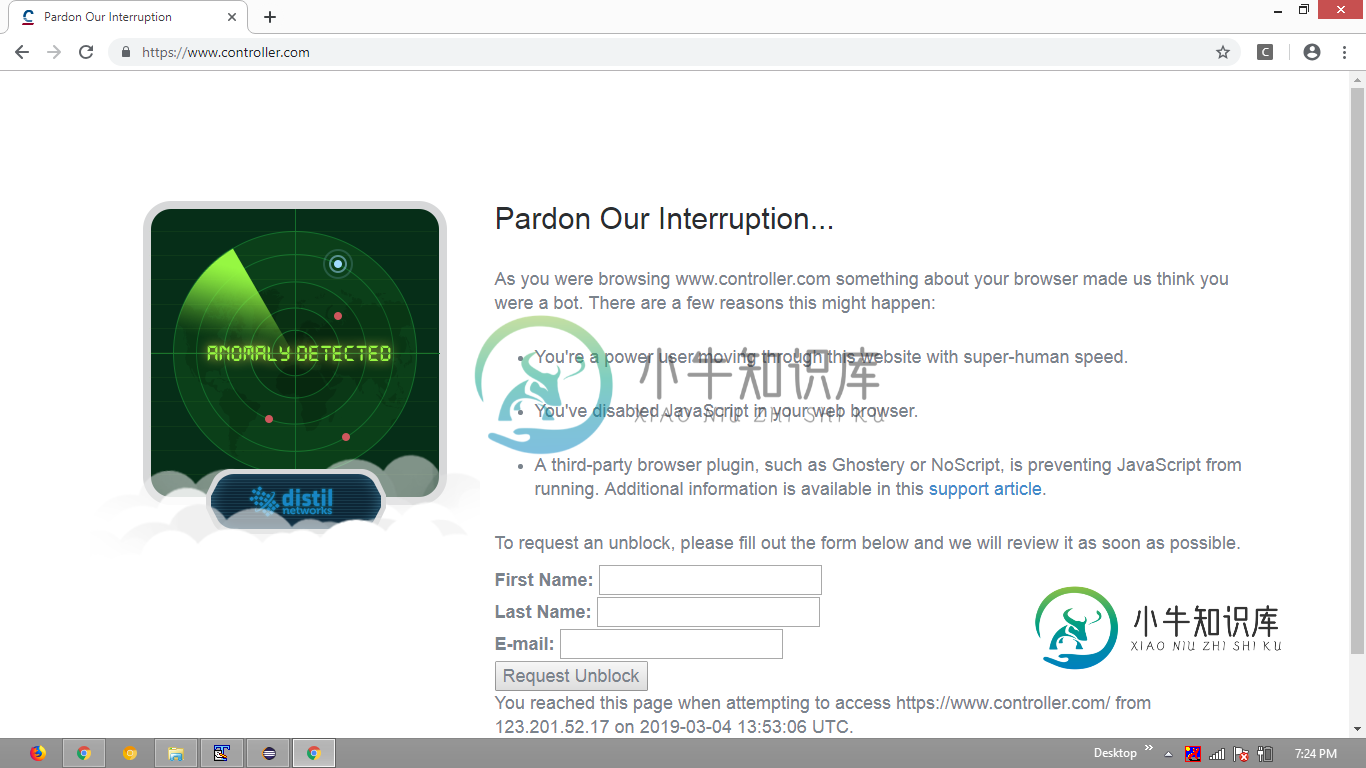
请原谅打断我们...当你浏览www.controller.com时,你的浏览器让我们以为你是个机器人。有几个原因可能会发生这种情况:你是一个超级用户,以超人的速度浏览这个网站。您已经在web浏览器中禁用了JavaScript。第三方浏览器插件,如Ghostery或NoScript,正在阻止JavaScript的运行。其他信息可在本支持文章中获得。若要申请解除封锁,请填写以下表格,我们将尽快审查。“
下面是我的代码:
from selenium import webdriver
import requests
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
options = webdriver.ChromeOptions()
options = webdriver.ChromeOptions()
options.add_argument("start-maximized")
options.add_argument("disable-infobars")
options.add_argument("--disable-extensions")
#options.add_argument('headless')
driver = webdriver.Chrome(chrome_options=options)
driver.get('https://www.controller.com/')
driver.implicitly_wait(30)
共有1个答案

您只在问题中提到了pandas.get_html,而在代码中只提到了options.add_argument('headless'),因此不确定是否正在实现它们。但是,从您的代码尝试中取出最少的代码,如下所示:
>
代码块:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("start-maximized")
options.add_argument("disable-infobars")
options.add_argument("--disable-extensions")
driver = webdriver.Chrome(chrome_options=options, executable_path=r'C:\Utility\BrowserDrivers\chromedriver.exe')
driver.get('https://www.controller.com/')
print(driver.title)
我也面临过同样的问题。
-
null
<script type="text/javascript" id="">
window.onbeforeunload=function(a){"undefined"!==typeof sessionStorage&&sessionStorage.removeItem("distil_referrer")};
</script>

根据这篇文章,确实有关于蒸馏的东西。它...:
Distil通过观察站点行为和识别刮刮器特有的模式来保护站点免受自动内容刮刮机器人的攻击。当Distil在一个站点上识别出恶意机器人时,它会创建一个黑名单行为配置文件,并将其部署到所有客户。类似于机器人防火墙的东西,Distil检测模式并做出反应。
进一步,
-
null
-
我正在尝试设置一个容器,以便在Chrome上使用RobotFramework进行测试。 但是当我运行容器时,我总是得到一个WebDriverException。我已经找过了,但找不到任何对我有效的修复方法。 这是我的Dockerfile
-
我一直在用Chromedriver测试Selenium,我注意到有些页面可以检测到你在使用Selenium,尽管根本没有自动化功能。即使我只是手动浏览,只是使用Chrome,通过Selenium和Xephyr,我也经常会看到一个页面,上面说检测到了可疑的activity。我已经检查了我的用户代理和我的浏览器指纹,他们都完全相同的正常Chrome浏览器。 当我用普通的Chrome浏览这些网站时,一切
-
我试图使用一个带有selenium的无头chrome浏览器,它也绕过了机器人检测测试,目前使用以下项目https://github.com/ultrafunkamsterdam/undetected-chromedriver每次我试图实现代码时,它都不能识别驱动程序。以下是您了解的链接 这是代码 好吧,当我运行程序时,我在终端中得到以下内容
-
问题内容: 如何使用php检测搜索引擎机器人? 问题答案: 这是Search Engine Directory of Spider names 然后使用来检查代理是否被称为蜘蛛。
-
问题内容: 我一直在使用Chromedriver测试Selenium,但我注意到,即使根本没有自动化功能,某些页面也可以检测到您正在使用Selenium。即使当我只是通过Selenium和Xephyr使用chrome手动浏览时,我也经常得到一个页面,指出检测到可疑活动。我已经检查了用户代理和浏览器指纹,它们与普通的chrome浏览器完全相同。 当我以普通的chrome浏览到这些站点时,一切正常,但
-
我们的实验室与一家网络公司合作,开发了保护网页不被网络爬虫抓取的技术。测试网站http://119.254.209.77/。我不能在左边的页面上得到网址,比如“检查”。当我点击链接时,它会创建一个网址。使用Python Selenium Firefox,我模拟了点击操作,但是我得到了一个空白页面,而不是真实的数据。如果我只是自己点击链接,它会返回真实的数据。所以我想知道如何服务器可以识别我是一个网