
具有映射多行并跨行匹配的总和

想要编写 Excel 公式,该公式将根据行的匹配项对值求和。要匹配的单元格可以多次出现,并且基于映射图例,它们应返回值的总和。
在黄色单元格中,我试图根据G3: G8中名称的匹配来计算B9: B21范围内的值的总和,根据映射图例到Item1,然后是Item2和Item 3。此外,我想考虑在日期1、日期2和日期3之间进行的总和。下面的SumProduct公式仅适用于单个日期的sum数组,而不适用于日期1、日期2和日期3:
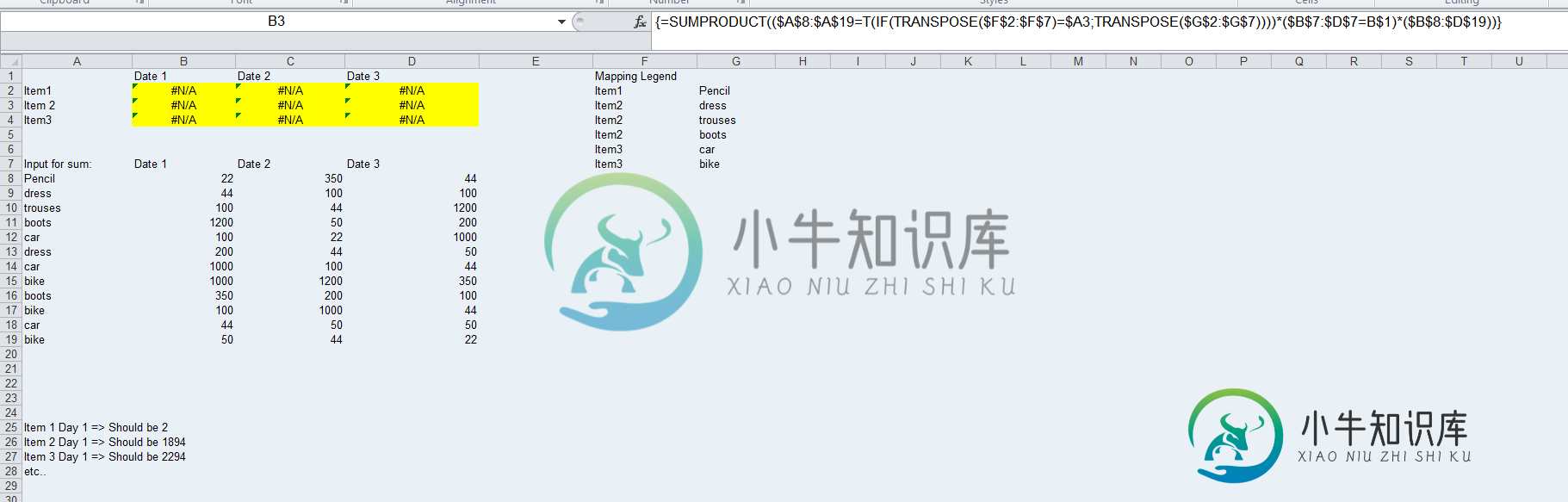
有人知道如何解决这个问题吗?我想补充一点,我希望每个黄色单元格中的fomrula都是相同的,而不需要在日期之间拆分数组。此外,在公式中,重要的是要在“日期1”、“日期2”和“日期3”匹配的基础上使用它。
共有1个答案

将此数组公式放入带有CSE的B2中,然后向右和向下填充。
=SUM(SUMIFS(INDEX($B$8:$D$19, 0, MATCH(B$1, $B$7:$D$7, 0)), $A$8:$A$19, IF($F$2:$F$7=$A2, $G$2:$G$7)))
-
假设我有这样的代码: 输出是相同的线程名称,所以这里没有的好处--我的意思是有一个线程来完成所有的工作。 在内部有以下代码: 我理解强制属性如果“outer”流将是并行的(它们可能会阻塞),“outer”将不得不等待“flatmap”完成,反过来(因为使用了相同的公共池),但为什么总是强制这样做呢? 这是一个可以在以后的版本中改变的东西吗?
-
麻烦请问用golang的正则怎么把p标签的文本内容取出来,谢谢 补充,上边代码只是html一部分,
-
问题内容: 我有一个表创建与: 我用这个插入数据: 当我从表中选择以下内容时: 这将返回2行 为什么会这样呢?为什么即使查询指定值仅是1,但没有空格,它也返回最后带有空格的版本? 问题答案: 有趣的是,如果您使用LIKE,则可以工作: 编辑: 经过更多的研究,我发现其他人与我们进行了相同的对话。看这里。该评论仅在讨论中进行了一半。但是结果是如我们所发现的,要么如上所述使用LIKE,要么添加第二个条
-
问题内容: 我有两个表,并且具有一对多关系。一个可能与许多相关联。 我想做的是运行一个查询,该查询查找具有特定的attributeID集合的所有dataID。我不能: 那将使用那些属性中的任何一个来获取所有的dataID,我想要具有所有这些属性的dataID。 有什么建议吗? 仍然使用比基本选择更多的查询来解决问题。 问题答案: 由于您需要读取表的三个不同行,因此建议使用来避免子查询。
-
我的问题听起来很琐碎,但我谷歌了很多页面还是找不到答案。 我在窗户上。我有一个文本文件。如果我用notepad++打开它,它看起来像这样 我想尝试几件事 如果我们想缩进!行如果它的前一行以“function”开头,一个天真的想法会是(实际上它的工作是notepad++) 但没有奏效。如何正确地去做?
-
我有一个包含100,000行(人)和500列(概率)的数据集,我想用测试概率扫描各列,以找到大于和最接近测试值的列标题(a、b或c ),并将标题记录在新列中。 以数据表为例: 新列将记录“a”(0.1 我最初做它作为一个矩阵,而不是data.table.下面的代码不会工作,但给出了一个想法,它是如何运作的 如何跨 data.table 中的列执行此匹配。我认为我需要使用 来自 的查询。但不确定如何