
CloudFront->S3,用于ECS中具有多个动态后端的静态或API网关

我需要为站点实现一个反向代理/重定向服务,该服务将托管在AWS S3(静态JS资产)+CloudFront和作为不同任务运行的多个后端AWS ECS在domain.com/api/session_numberRedirect或反向代理服务应该分析输入参数并重定向到相应的后端。
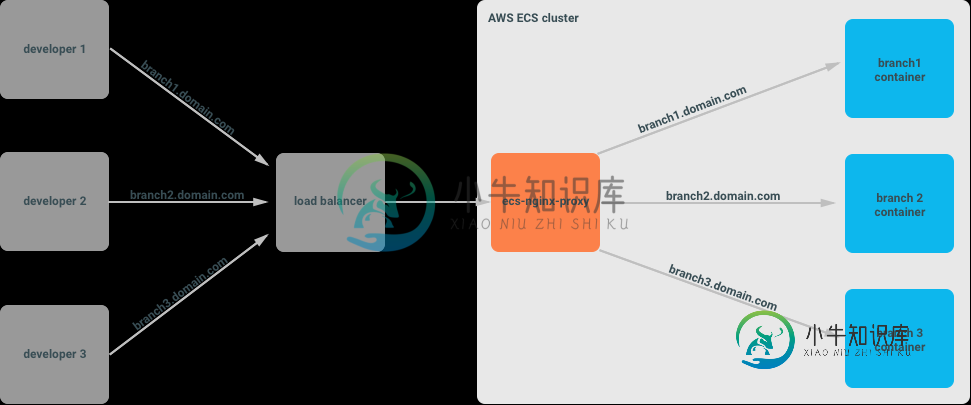
到目前为止,我已经找到了ECS-nginx-proxy,但它看起来更像是用于开发/阶段环境的工具。如何使用AWS服务如ALB+API Gateway、Lambda@Edge在生产中实现这样的服务?
共有1个答案

您真正想放在那里的不是nginx,而是Traefik负载均衡器:
- 如何在ECS上设置Traefik?
- https://netbears.com/blog/traefik-cluster-ecs/
-
当您使用网关创建API并映射自定义域时,AWSAPIGateway会在cloudfront发行版中创建一个条目 来源:http://docs.aws.amazon.com/apigateway/latest/developerguide/how-to-custom-domains.html 对于您创建的每个API,API网关都会为该API设置Amazon CloudTop分发。使用默认API UR
-
我试图将一个静态网站安装到S3中,使用自定义域,并使用CloudFront处理HTTPS。 问题是根路径可以正常工作,而子路径不能正常工作。 显然,所有这些都与默认根对象有关,我在这两个地方都将其配置为index.html。 null 即使Index.html的副本出现在安装目录中,CloudFront也不会返回默认的根对象。 如果将发行版配置为允许CloudFront支持的所有HTTP方法,则默
-
问题内容: 我一直在寻找方法来改善托管在CDN(如Amazon S3)上的angularJS应用的SEO(即,没有后端的简单存储)。那里的大多数解决方案(PhantomJS,prerender.io,seo.js等)都依赖后端来识别搜寻器生成的url,然后从其他地方获取相关页面。即使grunt- html-snapshot 最终也需要您执行此操作,即使您提前生成快照页面也是如此。 该解决方案基本上
-
有人能提供一个简单的例子来解释Java中动态多态性和静态多态性之间的区别吗?
-
主要内容:静态网页,动态网页本节我们了解一下静态网页和动态网页的相关概念。如果您熟悉前端语言的话,那么您可以快速地了解本节知识。 当我们在编写一个爬虫程序前,首先要明确待爬取的页面是静态的,还是动态的,只有确定了页面类型,才方便后续对网页进行分析和程序编写。对于不同的网页类型,编写爬虫程序时所使用的方法也不尽相同。 静态网页 静态网页是标准的 HTML 文件,通过 GET 请求方法可以直接获取,文件的扩展名是 、 等,网面中
-
我理解了使用奇怪的重复模板模式的静态多态性的机制。我只是不明白这有什么好处。 公开的动机是: 更喜欢使虚函数私有。 当然,还有一个彻底的解释,为什么这是好的风格。 在本指南的上下文中,第一个示例是好的,因为: 关于静态多态性,我遗漏了什么?这一切都是关于好的C++风格吗? 应该什么时候使用?有哪些指导方针?