
简单查询的Cassandra分区密钥

共有1个答案

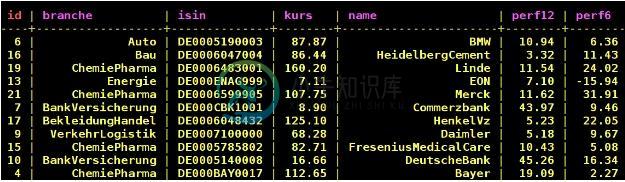
这取决于你需要什么信息来提出请求。如果知道分支和公司名称,可以将主键:分支作为分区键,名称作为集群键。
primary key ((branch), name)
这样,您就可以使用以下内容进行第一个查询:
select kurs from table where branch =? and name =?;
第二种方法,您可以只指定分区键并创建一个聚合函数来返回平均值:
select avg(kurs) from table where branch = ?
-
因此,我尝试使用Spark SQL进行以下查询('timestamp'是分区键): 虽然作业产生200个任务,但查询不会返回任何数据。 另外,我可以保证会返回数据,因为在cqlsh上运行查询(使用'token'函数进行适当的转换)确实会返回数据。 但不幸的是我不知道什么是“过滤器”...
-
我的主要问题是用复合分区键对表上的Cassandra resultset进行分页。然而,我试图用一个简单的场景来缩小范围。喂,我有桌子, 我有一个数据, 我的模式使用默认的分区器(Murmur3Partitioner)。这是完全可以实现的吗?
-
我正在尝试将以下结构存储在卡桑德拉中。 上面的大多数查询是 这就是为什么将()设置为主键很有用的原因。 根据docu,Cassandra的默认分区键是主键的第一列-在我的例子中是,但我想在Cassandr集群上均匀分布数据,我不能允许一个中的所有数据只存储在一个分区中,因为有些商店有10M条记录,有些只有1k条记录。 我可以设置()作为分区键,然后我可以达到Cassandra集群中记录的统一分布。
-
我想查询表的完整分区。我的复合分区键由组成和是字符串,是整数。 我需要将hour_of_timestamp字段添加到我的分区键,因为在摄取数据时存在热点。 现在我想知道查询数据的完整分区的最有效方法是什么?根据这个博客,使用会在协调器节点上造成大量开销。 使用TOKEN函数并用两个TOKEN查询分区是否更好?如<代码> SELECT * from my table WHERE TOKEN(id,d
-
使用Spark连接器通过分区键查询cassandra的理想方法是什么。我使用传入键,但这导致cassandra在引擎盖下添加,从而导致超时。 当前设置: 这里是分区(不是主)键,我有一个复合主键,只使用分区键进行查询 更新:是的,我得到了一个异常:
-
我正在spark项目中使用spark sql 3.0.2和spark-cassandra-connector_2.12:3.1.0以及java8。 在写卡桑德拉表格时,我面临以下错误 最新的异常是在一致性LOCAL_ONE的简单写入查询期间发生Cassandra超时(需要1个副本,但只有0个副本确认了写入) 请检查执行程序日志以获取更多异常和信息table_cassandraAsyncStatem