
x86是否可以用更宽的负载重新排序一个狭窄的存储区,以完全包含它?

8.2.3.4加载可以用较早的存储重新排序到不同的位置
Intel-64内存排序模型允许用较早的存储重新排序到不同的位置。但是,不会将加载与存储区重新排序到相同的位置。
如果加载部分或完全重叠以前的存储区,但没有相同的起始地址,该怎么办?(具体案例见本帖末尾)
假设下面的类C代码:
// lock - pointer to an aligned int64 variable
// threadNum - integer in the range 0..7
// volatiles here just to show direct r/w of the memory as it was suggested in the comments
int TryLock(volatile INT64* lock, INT64 threadNum)
{
if (0 != *lock)
return 0; // another thread already had the lock
((volatile INT8*)lock)[threadNum] = 1; // take the lock by setting our byte
if (1LL << 8*threadNum != *lock)
{ // another thread set its byte between our 1st and 2nd check. unset ours
((volatile INT8*)lock)[threadNum] = 0;
return 0;
}
return 1;
}
; rcx - address of an aligned int64 variable
; rdx - integer in the range 0..7
TryLock PROC
cmp qword ptr [rcx], 0
jne @fail
mov r8, rdx
mov rax, 8
mul rdx
mov byte ptr [rcx+r8], 1
bts rdx, rax
cmp qword ptr [rcx], rdx
jz @success
mov byte ptr [rcx+r8], 0
@fail:
mov rax, 0
ret
@success:
mov rax, 1
ret
INT64 lock = 0;
void Thread_1() { TryLock(&lock, 1); }
void Thread_5() { TryLock(&lock, 5); }
共有1个答案

x86是否可以用更宽的负载重新排序一个狭窄的存储区,以完全包含它?
是的,x86可以用更宽的负载重新排序一个狭窄的存储区,从而完全包含它。
这就是锁算法被破坏的原因,shared_value不等于800000:
-
null
-
null
见下面正确的例子。
问题:
((INT8*)锁)[1]=1;和((INT8*)锁)[5]=1;存储区与锁的64bit加载不在同一个位置。然而,它们都被该负载完全包含,所以这是否“算作”相同的位置?
((volatile INT8*)lock)[threadNum] = 1; // STORE
if (1LL << 8*threadNum != *lock) // LOAD
>
如果存储和加载大小相等,那么将CPU-Core do(存储转发)查找加载到存储缓冲区中,并查看所有需要的数据-在完成存储之前,您可以立即获得所有实际数据
如果STORE和LOAD大小不相等,STORE(1字节)和LOAD(8字节),那么即使LOAD CPU-Core在Store-Buffer中进行查找,它也只能看到所需数据的1/8-在完成STORE之前,您无法立即获得所有实际数据。以下是CPU操作的两种变体:
>
案例-1:CPU-Core从处于共享状态(S)的缓存行加载其他数据,并与存储缓冲区重叠1个字节,但存储仍然保留在存储缓冲区中,并等待收到独占状态(E)的缓存行来修改它-即CPU-Core在存储完成之前读取数据-在您的示例中是data-races(error)。存储-加载重新排序为全局可见的加载-存储。-这正是x86_64上发生的情况
案例2:CPU-Core等待当存储缓冲区将被刷新,存储已经等待缓存行的排他状态(E)并且存储已经完成时,CPU-Core从缓存行加载所有需要的数据。存储加载不会在全局可见中重新排序。但这与使用mfence相同。
结论,在任何情况下,都必须在存储后使用mfence:
- 它完全解决了案例-1中的问题。
- 不会对案例-2中的行为和表现产生任何影响。空存储缓冲区的显式
mfence将立即结束。
- GCC 6.1.0(使用
mfence刷新存储缓冲区):https://godbolt.org/g/dtnmz7 - CLANG 4.0(使用
[LOCK]xchgb reg,[addr]刷新存储缓冲区):https://godbolt.org/g/bqy6ju
注意:xchgb总是有前缀lock,所以它通常不是用asm编写的,也不是用括号表示的。
所有其他编译器都可以在上面的链接上手动选择:PowerPC、ARM、ARM64、MIPS、MIPS64、AVR。
#ifdef __cplusplus
#include <atomic>
using namespace std;
#else
#include <stdatomic.h>
#endif
// lock - pointer to an aligned int64 variable
// threadNum - integer in the range 0..7
// volatiles here just to show direct r/w of the memory as it was suggested in the comments
int TryLock(volatile uint64_t* lock, uint64_t threadNum)
{
//if (0 != *lock)
if (0 != atomic_load_explicit((atomic_uint_least64_t*)lock, memory_order_acquire))
return 0; // another thread already had the lock
//((volatile uint8_t*)lock)[threadNum] = 1; // take the lock by setting our byte
uint8_t* current_lock = ((uint8_t*)lock) + threadNum;
atomic_store_explicit((atomic_uint_least8_t*)current_lock, (uint8_t)1, memory_order_seq_cst);
//if (1LL << 8*threadNum != *lock)
// You already know that this flag is set and should not have to check it.
if ( 0 != ( (~(1LL << 8*threadNum)) &
atomic_load_explicit((atomic_uint_least64_t*)lock, memory_order_seq_cst) ))
{ // another thread set its byte between our 1st and 2nd check. unset ours
//((volatile uint8_t*)lock)[threadNum] = 0;
atomic_store_explicit((atomic_uint_least8_t*)current_lock, (uint8_t)0, memory_order_release);
return 0;
}
return 1;
}
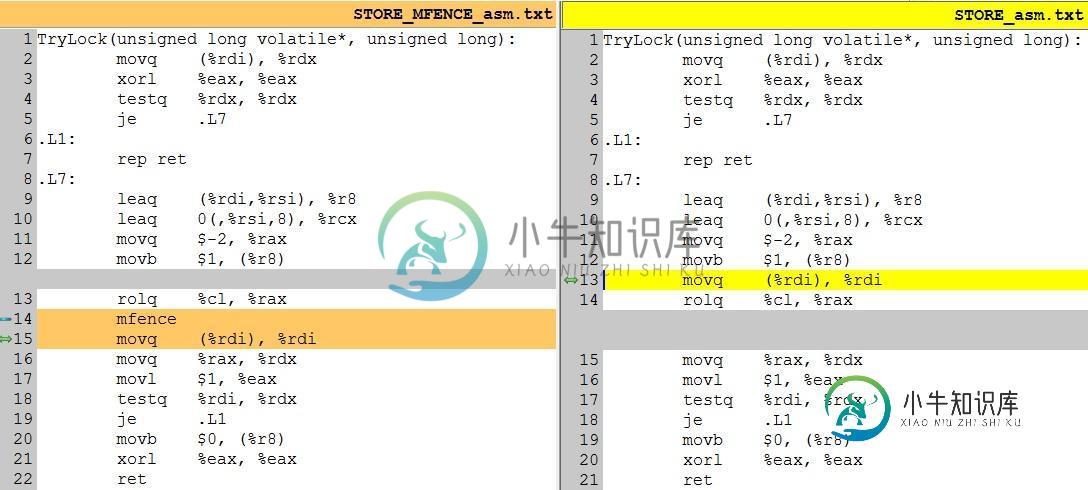
TryLock(unsigned long volatile*, unsigned long):
movq (%rdi), %rdx
xorl %eax, %eax
testq %rdx, %rdx
je .L7
.L1:
rep ret
.L7:
leaq (%rdi,%rsi), %r8
leaq 0(,%rsi,8), %rcx
movq $-2, %rax
movb $1, (%r8)
rolq %cl, %rax
mfence
movq (%rdi), %rdi
movq %rax, %rdx
movl $1, %eax
testq %rdi, %rdx
je .L1
movb $0, (%r8)
xorl %eax, %eax
ret
其工作原理完整示例:http://coliru.stacked-crooked.com/a/65e3002909d8beae
shared_value = 800000
如果不使用mfence-Data-Races会发生什么
有一个StoreLoad重新排序,如上面描述的情况-1(即,如果不对存储使用顺序一致性)-ASM:https://godbolt.org/g/p3j9fr
-
null
-
最后一个2字节加载从紧邻的前一个存储区中获取第二个字节,但从前一个存储区中获取第一个字节。这个加载可以被存储转发吗,还是需要等到前面的两个存储都提交到L1? 请注意,通过这里的存储转发,我包含了任何机制,这些机制可以满足来自仍然在存储缓冲区中的存储的读取,而不是等待它们提交到L1,即使这是一个比“从单个存储转发”的最佳情况更慢的路径。
-
问题内容: 我有一个使用标签中定义的Java Applet的Web应用程序。是否可以添加在Applet完全加载后触发的javascript事件?这是一些初始化javascript,取决于小程序已完全加载且有效。 问题答案: 如果您没有对applet的源代码控制,则可以在调用applet上的方法之前轮询要加载的applet。这是我写的一个实用程序函数,它就是这样做的: 这样称呼它:
-
我读过很多关于内存排序的文章,他们都只说CPU会重新排序加载和存储。 CPU(我对x86 CPU特别感兴趣)是否只对加载和存储进行重新排序,而不对其拥有的其余指令进行重新排序?
-
问题内容: 我需要开发一个可长期离线运行的Web应用程序。为了使它可行,我无法避免将敏感数据(个人数据,而不是您将仅存储散列数据的类型)保存在本地存储中。 我接受不建议这样做,但是我几乎没有选择要执行以下操作来保护数据: 使用斯坦福JavaScript加密库和AES-256将所有内容都加密到本地存储中 用户密码是加密密钥,未存储在设备上 通过ssl从单个受信任的服务器提供所有内容(在线时) 使用o
-
问题内容: 它看起来像一个简单的任务,但却无法正常工作。我需要重新订购宽度为100%的平板电脑的div。 原始参考: 问题答案: 如果您首先考虑移动技术,它是可行的。将div按您希望它们在小视口中出现的顺序放置,然后对它们在大视口中重新排序。
-
问题内容: 我想创建一个包含一个或多个容器的Docker容器。Docker有可能吗? 问题答案: 在docker内部运行docker绝对是可能的。最主要的是,您将外部容器具有额外的特权(以开头),然后在该容器中安装docker。 查看此博客文章以获取更多信息:Docker-in-Docker。 本条目中描述了一种可能的用例。该博客介绍了如何在Jenkins Docker容器中构建Docker容器。