
删除具有唯一ENSG ID的重复基因

我是一个初学者与R.我有一个tibbledata.frame:这是一个基因列表,包含企业ID、基因符号、基因描述和ENSG_ID。我想删除与唯一的ENSG ID相关的基因重复。例如,在我的数据框中发现AKRC1是重复的,有2个ENSG标识,其中一个与基因AKRC2相同。
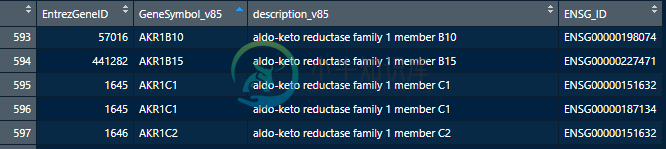
初始文件
我试图删除重复的,但问题是我保留了AKRC1
#确定非重复基因的指数
non_duplicated_idx
#仅使用索引返回非重复的基因
注释1
重复的基因被删除,但这里举例来说,AKRC1保留的ENSG_ID大于AKRC2。
删除重复项后

是否可以用唯一的ENSG_ID删除重复?(在这里,例如,我想保持AKRC1与ENSG00000187134)
非常感谢你的帮助,杰西卡
共有1个答案

-
问题内容: 我在表中有一些数据,看起来大致如下: tickId和timestamp都不是唯一的,但是tickId和timestamp的组合应该是唯一的。 我的表中有一些重复的数据,并且我试图将其删除。但是,我得出的结论是,给定数据的信息不足,无法区分另一行,基本上没有办法删除重复的行之一。我的猜测是,我将需要引入某种身份列,这将有助于我从另一行中识别出一行。 这是正确的吗,还是有某种神奇的方法可以
-
问题内容: 我必须清理具有重复行的表: 一个可能具有多个值: 我想对整个表执行一个查询,并删除和重复的所有行。在上面的示例中,删除后,我只想剩下1、2、4和5。 问题答案: ;WITH x AS ( SELECT id, gid, url, rn = ROW_NUMBER() OVER (PARTITION BY gid, url ORDER BY id) FROM dbo.table ) SEL
-
问题内容: 如何删除Postgres 9表中的重复行,行在每个字段上都是完全重复的,并且没有单个字段可用作唯一键,所以我不能只使用列并使用语句。 我正在寻找一个SQL语句,而不是需要我创建临时表并将记录插入其中的解决方案。我知道该怎么做,但是需要更多工作来适应我的自动化流程。 表定义: 样本数据: 问题答案: 如果您有能力重写整个表,则这可能是最简单的方法: 如果您需要专门针对重复的记录,则可以使
-
我有这样布局的模型: 这里的场景是我永远不希望用户删除数据。相反,删除只会隐藏记录。但是,我仍然希望所有非软删除的记录都遵循唯一的键约束。基本上,我希望有尽可能多的重复的已删除记录,但只有一个唯一的未删除记录可以存在。所以我本来想包括“已删除”字段(由django安全删除库提供),但问题是Django的唯一检查因“psycopg2”而失败。完整性错误:重复的键值违反了 ['field2', 'fi
-
问题内容: 我相信在A,B,C,D的两个表字段之间插入了唯一索引,以防止重复。但是我以某种方式简单地对它们做了一个普通索引。因此插入了重复项。它是2000万个记录表。 如果我将现有索引从普通索引更改为唯一索引,或者只是为A,B,C,D添加新的唯一索引,由于存在唯一记录,重复项将被删除还是添加失败?我将对其进行测试,但它已达到3000万条记录,并且我既不希望将表弄乱或复制它。 问题答案: 如果表中有
-
问题内容: 这个问题已经在这里有了答案 : SQLite删除查询错误 (3个答案) 7年前关闭。 我试图通过以下命令对SQLite中的表进行别名化(例如,这本书是我正在阅读“ Ramakrishnan的数据库管理系统”的书) 此代码给出了语法错误。在不使用别名的情况下,以下代码有效: 但是,如果我想为表加上别名,该怎么办?有人可以帮忙吗? 谢谢 问题答案: 该语句在单个表上运行,并且不使用表别名。