
VisualVM与Eclipse MAT中的堆大小差异[重复]

共有1个答案

重复:为什么我的Java堆转储大小比使用的内存小得多?
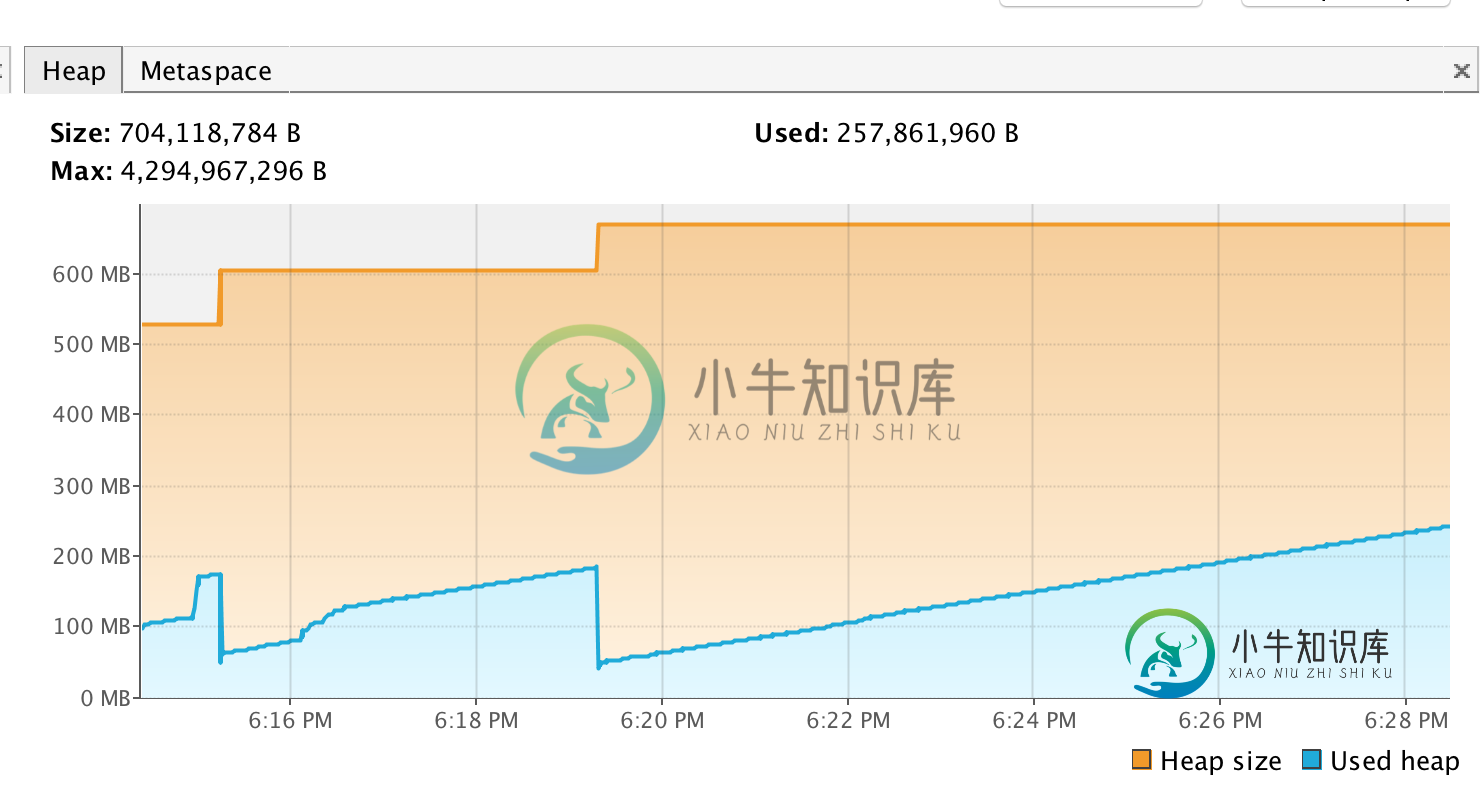
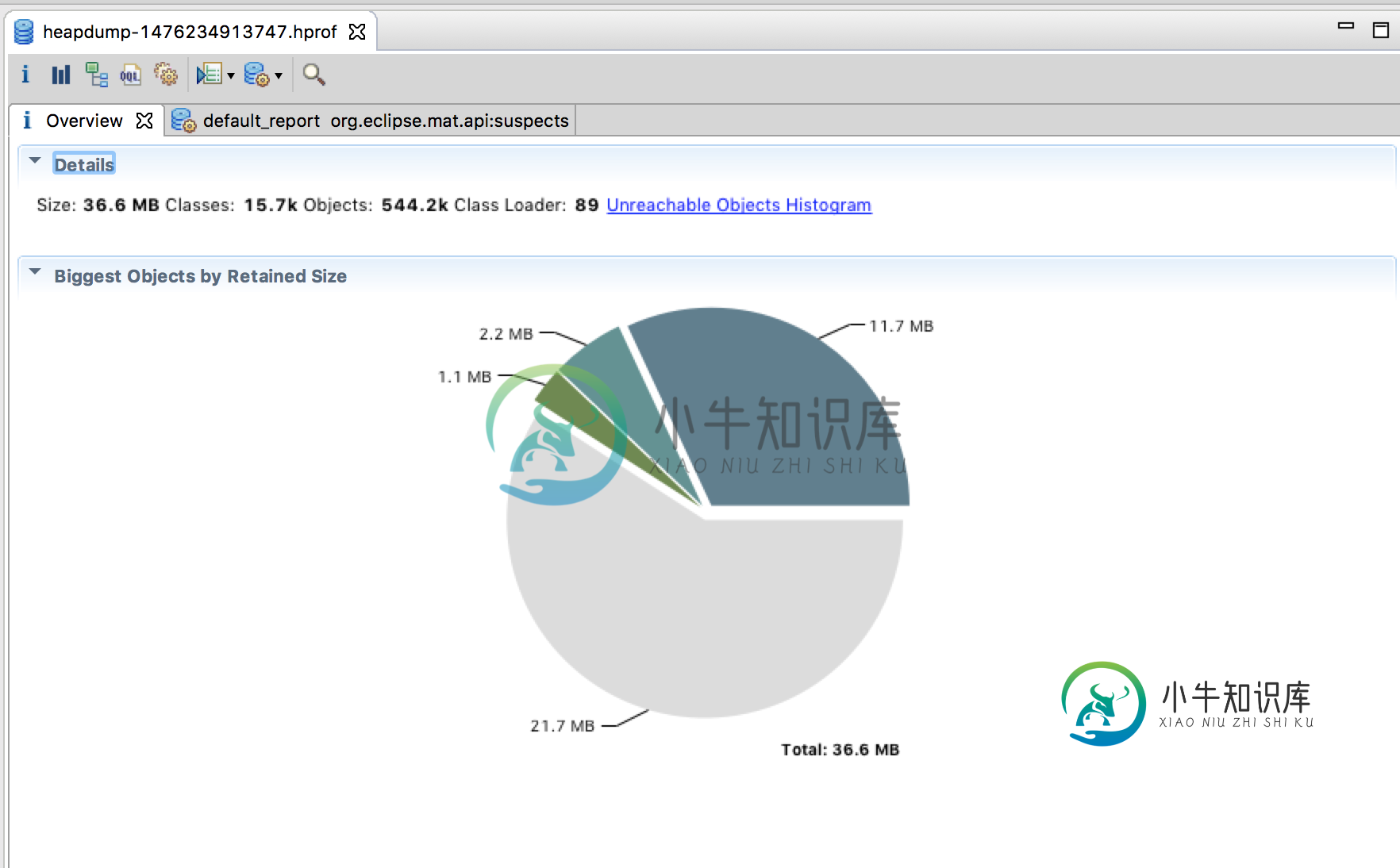
TLDR;堆转储触发的垃圾收集和转储显示“使用的堆”
-
我正在Windows 8.1 64位上开发java swing应用程序,带有4GB内存和JDK版本8u20 64位。 问题是当我使用带有监视器选项的Netbeans profiler启动应用程序时。 加载第一个Jframe时,应用程序Memory Heap约为18mb,JVM进程大小约为50mb(Image1)。 然后,当我启动另一个Jframe时,它包含一个带有webView的JFxPanel,
-
我是Java的初学者,刚开始使用Intellij作为我的IDE。 当我使用它时,有时会延迟。 我更改了我的 xms 和 xmx 以获得更大的堆大小(xms = 1024,xmx = 2048),但它抛出了一个错误。 所以,我把它回滚了。 错误消息是这样的:“初始堆大小设置为大于最大堆大小的值”。 有什么问题? 如果可能,如何增加最大堆大小? 我用的是笔记本电脑,它有8GB内存。x64Intelli
-
在图像中,使用内存为3.8G,提交内存为8.6G,最大内存也为8.6G,任何人都可以解释使用内存和提交内存之间的差异,或者任何解释它的链接。
-
我正试图在过期日期前三天,但我不知道如何发送? 思维方式 检索剩余三天到期的所有订阅者 发送电子邮件给他们的用户 代码 表我需要检查名为 这个表有一个名为的列,我需要检查它以找到
-
使用Java的工作代码: C++代码用dictionary[“Apple”,“Pen”]返回“ApplePenApple”的false,我不知道为什么java返回true是正确的。这两种解决方案之间唯一的主要区别(我认为)是我的C++在java代码中使用向量而不是原生数组。最初,我认为这可能与C++使用自动存储(堆栈)而不是自由存储(堆)有关,这就是为什么我使用向量而不是C样式的数组来避免内存管理
-
我是并行编程的新手。.NET 中有两个类可用:类和。 所以,我的问题是: 这些课程之间有什么区别 什么时候使用<code>线程<code>优于<code>任务<code>更好(反之亦然)