
芹菜广播vs RabbitMQ扇出

我最近一直在用芹菜,我不喜欢它。它的配置是混乱的,过于复杂的,并且没有很好的文档记录。
我想从一个生产者向多个消费者发送带有芹菜的广播消息。使我困惑的是芹菜术语和底层传输rabbitMQ的术语之间的差异。
在RabbitMQ中,您可以使用单个扇出交换和多个队列来广播消息:
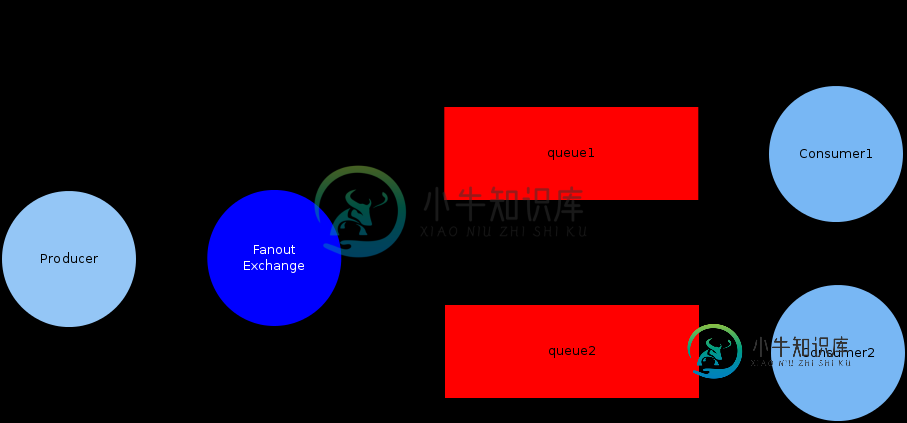
但在Celery中,术语都搞乱了:这里可以有一个广播队列,它向多个消费者发送消息:

我甚至不明白Celery广播队列应该如何工作,因为具有多个使用者的RabbitMQ队列用于负载平衡。因此在RabbitMQ中,如果多个消费者(即一个消费者池)连接到同一个队列,那么只有一个消费者会接收和处理消息,这在RabbitMQ文档中称为循环。
此外,芹菜的广播文档确实不足。我应该为广播队列指定哪种类型的RabbitMQ交换,扇出还是不扇出?你能举一个完整的例子吗?
因此,我要求的是(1)Celery中广播队列的概念和实现的澄清和(2)广播队列配置的完整示例。谢谢.
共有1个答案

这有帮助吗?
http://celery.readthedocs.org/en/latest/userguide/routing.html#exchanges-queues-and-routing-keys
Celery中的'queue'定义似乎包括交换,因此您可以在exchange('fanout')交换类型之上定义一个Celery队列,它将具有多个RabbitMQ队列的底层实现。
在这种情况下,我想您不希望Celery配置中有一个“广播”队列,除非您真的希望多个工作者处理同一任务。
-
现在,我想将< code>register事件发布到某个特殊的交换,我可以使用celery远程检索和处理它。 实际上,我已经使用了函数来实现这一点,但是它必须传递来指示应该执行哪个任务并消费它。所以它似乎不太适合我的目标。 我想要的就是这样: 向某些发布消息; 远程机器1订阅此或并捕获消息,用于执行任务; 远程机器2-与机器1相同但执行另一个任务-接收(可能需要回复某些) 例如,就像这个工作流一样
-
输出如下: 如果两个数组的维数不相同,则元素到元素的操作是不可能的。 然而,在 NumPy 中仍然可以对形状不相似的数组进行操作,因为它拥有广播功能。 较小的数组会广播到较大数组的大小,以便使它们的形状可兼容。 如果满足以下规则,可以进行广播: 如果输入在每个维度中的大小与输出大小匹配,或其值正好为 1,则在计算中可它。 如果上述规则产生有效结果,并且满足以下条件之一,那么数组被称为可广播的。 数
-
原文:Broadcasting 另见:numpy.broadcast 术语广播描述了NumPy在算术运算时如何处理不同形状的数组。 在某些条件下,较小的数组“广播”成较大的数组以便有相同的形状。 广播提供了一种矢量化操作数组的方法,这样可以在C而不是Python中进行循环。 它可以在不制作不必要的数据副本的情况下实现这一点,并且通常可以实现高效 然而,有些情况下广播是一个坏主意,因为它会导致内存使
-
问题内容: 我正在运行Django 1.8 + Celery 4.0.2 Celery配置良好,可以在Redis后端本地运行Django任务。但是,当我尝试使用设置时,此设置无效。其他设置则不是这种情况,例如 具体来说,我看到的是 lib / python2.7 / site-packages / celery / app / task.py(520)apply_async()因此,CELERY_
-
我最近开始研究分布式计算以提高计算速度。我选择了芹菜。然而,我对一些术语不太熟悉。所以,我有几个相关的问题。 来自芹菜文档: ... Celery通过消息进行通信,通常使用代理在客户机和工作人员之间进行调解。为了启动任务,客户机将消息添加到队列中,然后代理将该消息传递给工作者。 什么是客户端(这里)?什么是经纪商?为什么消息通过代理传递?为什么 Celery 会使用后端和队列进行进程间通信? 当我
-
SocketIO另外一个非常有用的特性就是广播消息。Flask-SocketIO中,只要将broadcast = True这个可选参数加到send()和emit()中即可: @socketio.on('my event') def handle_my_custom_event(data): emit('my response', data, broadcast=True) 当一个消息以广播选