
PDF 提取中缺少表格布局信息

我已经研究了从PDF进行文本提取/数据提取,并使用了其他一些堆栈溢出答案来寻求帮助,我设置的是Tika通过自定义ContentHandlerDecorator解析pdf,该自定义ContentHandlerDecorator使用sax事件来解析内容。我遇到了一个问题,虽然在 PDF 查看器中查看 pdf 时包含一个按行和列排列的数据表,但该信息似乎没有从 pdf 中提取,或者我没有看到如何使用 tika / 萨克斯找到它。
这是我所看到的一个例子:
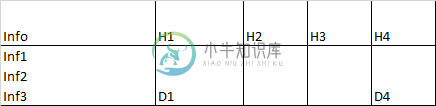
像上面这样的表格给了我这个(当我只是串起萨克斯事件时)
START http://www.w3.org/1999/xhtml, div, , div, class = page;
START http://www.w3.org/1999/xhtml, p, , p,
END http://www.w3.org/1999/xhtml, p, , p
WHITESPACE[
], 0, 1
START http://www.w3.org/1999/xhtml, p, , p,
CHARS [I, n, f], 0, 3
WHITESPACE[
], 0, 1
CHARS [o], 0, 1
WHITESPACE[
], 0, 1
END http://www.w3.org/1999/xhtml, p, , p
START http://www.w3.org/1999/xhtml, p, , p,
CHARS [I, n, f, o], 0, 4
CHARS [ ], 0, 1
CHARS [H, 1], 0, 2
CHARS [ ], 0, 1
CHARS [H, 2], 0, 2
CHARS [ ], 0, 1
CHARS [H, 3], 0, 2
CHARS [ ], 0, 1
CHARS [H, 4], 0, 2
WHITESPACE[
], 0, 1
END http://www.w3.org/1999/xhtml, p, , p
// Start of Second Row
START http://www.w3.org/1999/xhtml, p, , p,
CHARS [1], 0, 1
CHARS [I, n, f, 1], 0, 4
WHITESPACE[
], 0, 1
CHARS [I, n, f, 2], 0, 4
WHITESPACE[
], 0, 1
END http://www.w3.org/1999/xhtml, p, , p
START http://www.w3.org/1999/xhtml, p, , p,
CHARS [I, n, f, 3], 0, 4
WHITESPACE[
], 0, 1
END http://www.w3.org/1999/xhtml, p, , p
START http://www.w3.org/1999/xhtml, p, , p,
CHARS [D, 1], 0, 2
CHARS [ ], 0, 1
CHARS [D, 4], 0, 2
END http://www.w3.org/1999/xhtml, p, , p
由于段落似乎是随机结束的,没有新行开始的指示,在第二行的情况下,尽管在查看器中是这样显示的,但在空列的数据中没有间隙。
很抱歉,我无法提供pdf,但我正在寻找有关这些额外格式/布局数据存储或提取位置的任何信息,因为我从Tika获得的信息中显然缺少信息。这些段落中没有任何属性。
如果有帮助的话,我知道PDF是使用iText生成的,我可以在元数据中看到这一点,但在试用iText时,它似乎没有提供一种在不提供某种预先制作的提取模板的情况下以编程方式打开和解析PDF的方法,我不想这样做。
共有1个答案

SAX信息对于获取您想要的信息几乎毫无用处。IIRC,iText有一个文本提取API,您需要它将提供的位置信息来确定给定的文本位位于哪个列。
查看iText的SimpleTextExtraction战略。您需要构建类似的东西,注意evOccurred(),查找EventType.RENDER_TEXT。当您获得文本呈现事件时,您需要查看转换为TextRenderInfo的IEventData参数,并找出它在页面(和表中)的位置,是否在表中,等等。
根据位置信息,您必须推断出每条文本来自哪个列。不要依赖按逻辑顺序出现的信息。不要依赖文本使单元格处于单个呈现事件中。
注意:我对pdfbox,萨克斯或apache-tika几乎一无所知,所以很可能有一种不那么“自己动手”的方式来做到这一点。例如,您可以调整 Tika 的输出以提供定位信息(绝对或相对)。这些信息可能来自非常类似于SimpleTextExtracthtml" target="_blank">ionStrategy的东西。
狩猎愉快。
-
我有(相同的)数据保存为GIF图像文件和PDF文件,我想将其解析为超文本标记语言或XML。这些数据实际上是我大学自助餐厅的菜单。这意味着每周必须解析一个新版本的文件!一般来说,这些文件包含一些页眉和页脚文本,以及中间充满其他数据的表格。我读过一些关于stackoverflow的帖子,我也开始尝试将表格数据解析为超文本语言标记/XML: PDF格式 PDFBox||iText(Java) 谷歌文档导
-
我已经在java中使用PDFBox 1.8.10实现了简单的文本提取方法。由于某些原因,我必须将库升级到PDFBox 2.0.2。可能已删除PDFTextStripper()方法,或在新版本中找到另一个包。有没有办法解决这个问题?或者你能建议另一种从PDF获取文本的方法吗? 这是我的代码: 提前谢谢。
-
我想知道某个列存在于数据库中的哪个表中。所以我使用了带有where条件的sys.columns,这给了我一些object_id。 接下来,我从从上述查询收到的object_id中查找此表的实际名称,如下所示来自sys.tables。但是我的 select 语句返回一个空结果。这是否意味着数据库中不存在这样的表。如果是这样,sys.columns如何告诉我,我正在寻找的列位于具有此object_id
-
问题陈述: 我有一个PDF的结构像表格,但行是不可见的。请参阅下面的示例: 上图是我的表格在其中一个PDF页面中的样子。 我的研究 > 如何使用Python从PDF中提取表作为文本?--看了这道题,看了所有的答案。没有帮助 tabula:尝试了tabula API,但它只是提取标题而不是文本,可能是因为没有行。 我可以将整个pdf转换成文本,然后尝试用regex或数据操作来提取它。但这可能是非常乏
-
主要内容:本节引言:,1.本节学习路线图,2.TableLayout的介绍,3.如何确定行数与列数,4.三个常用属性,5.使用实例,6.发现的问题,本节小结:本节引言: 前面我们已经学习了平时实际开发中用得较多的线性布局(LinearLayout)与相对布局(RelativeLayout), 其实学完这两个基本就够用了,笔者在实际开发中用得比较多的也是这两个,当然作为一个好学的程序猿, 都是喜欢刨根问题的,所以虽说用得不多,但是还是有必要学习一下基本的用法的,说不定哪一天能用得上呢! 你说是吧,
-
学完了 Android 两个经典布局,是不是觉得已经可以应对大多数场景了?我记得当我学完 LinearLayout 和 RelativeLayout 之后,我觉得 UI 布局已经可以出师了,在本人从事了多年的 Android 研究之后,可以很负责任的告诉你,的确可以出师了。 大多数场景都可以通过这两个布局方式组合出来,不过光靠这两招出师可能会走不少弯路,因为 Google 还为我们提供了很多实用的